
tensorflow的資料讀取機制詳解
tensorflow的資料讀取機制詳解
Tensorflow中為了充分利用GPU,減少GPU等待資料的空閒時間,使用了兩個執行緒分別執行資料讀入和資料計算。
其中一個執行緒源源不斷的讀取硬碟圖片並存入記憶體佇列中,例外一個執行緒從記憶體佇列讀出圖片,並執行計算任務。
Tensorflow在記憶體佇列之前,還設定了一個檔名佇列,檔名佇列存放的是參與訓練的檔名,要訓練N個epoch,則檔名佇列中就含有N個批次的所有檔名。如下所示:
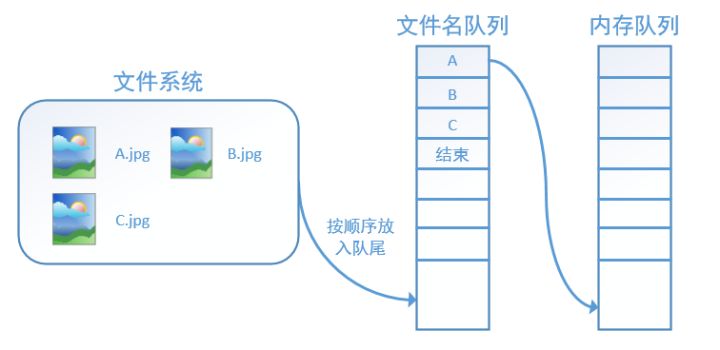
當tf讀完會丟擲一個OutofRange 的異常,外部捕獲到這個異常之後就可以結束程式了。而建立tf的檔名佇列就需要使用到 tf.train.slice_input_producer 函式。
tf.train.slice_input_producer
tf.train.slice_input_producer是一個tensor生成器,作用是按照設定,每次從一個tensor列表中按順序或者隨機抽取出一個tensor放入檔名佇列。
slice_input_producer(tensor_list, num_epochs=None, shuffle=True, seed=None, - 第一個引數tensor_list:包含一系列tensor的列表,表中tensor的第一維度的值必須相等,即個數必須相等,有多少個影象,就應該有多少個對應的標籤。
- 第二個引數num_epochs: 可選引數,是一個整數值,代表迭代的次數,如果設定
num_epochs=None,生成器可以無限次遍歷tensor列表,如果設定為
num_epochs=N,生成器只能遍歷tensor列表N次。 - 第三個引數shuffle:bool型別,設定是否打亂樣本的順序。一般情況下,如果shuffle=True,生成的樣本順序就被打亂了,在批處理的時候不需要再次打亂樣本,使用
tf.train.batch函式就可以了;如果shuffle=False,就需要在批處理時候使用tf.train.shuffle_batch函式打亂樣本。 - 第四個引數seed: 可選的整數,是生成隨機數的種子,在第三個引數設定為shuffle=True的情況下才有用。
- 第五個引數capacity:設定tensor列表的容量。
- 第六個引數shared_name:可選引數,如果設定一個‘shared_name’,則在不同的上下文環境(Session)中可以通過這個名字共享生成的tensor。
- 第七個引數name:可選,設定操作的名稱。
tf.train.slice_input_producer定義了樣本放入檔名佇列的方式,包括迭代次數,是否亂序等,要真正將檔案放入檔名佇列,還需要呼叫tf.train.start_queue_runners 函式來啟動執行檔名佇列填充的執行緒,之後計算單元才可以把資料讀出來,否則檔名佇列為空的,計算單元就會處於一直等待狀態,導致系統阻塞。
tf.train.slice_input_producer 和 tf.train.start_queue_runners 使用:
import tensorflow as tf
images = ['img1', 'img2', 'img3', 'img4', 'img5']
labels= [1,2,3,4,5]
epoch_num=8
f = tf.train.slice_input_producer([images, labels],num_epochs=None,shuffle=False)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(epoch_num):
k = sess.run(f)
print '************************'
print (i,k)
coord.request_stop()
coord.join(threads)
tf.train.slice_input_producer函式中shuffle=False,不對tensor列表亂序,輸出:
************************
(0, ['img1', 1])
************************
(1, ['img2', 2])
************************
(2, ['img3', 3])
************************
(3, ['img4', 4])
************************
(4, ['img5', 5])
************************
(5, ['img1', 1])
************************
(6, ['img2', 2])
************************
(7, ['img3', 3])
如果設定shuffle=True,輸出亂序:
************************
(0, ['img5', 5])
************************
(1, ['img4', 4])
************************
(2, ['img1', 1])
************************
(3, ['img3', 3])
************************
(4, ['img2', 2])
************************
(5, ['img3', 3])
************************
(6, ['img2', 2])
************************
(7, ['img1', 1])
tf.train.batch
tf.train.batch是一個tensor佇列生成器,作用是按照給定的tensor順序,把batch_size個tensor推送到檔案佇列,作為訓練一個batch的資料,等待tensor出隊執行計算。
batch(tensors, batch_size, num_threads=1, capacity=32,
enqueue_many=False, shapes=None, dynamic_pad=False,
allow_smaller_final_batch=False, shared_name=None, name=None)
- 第一個引數tensors:tensor序列或tensor字典,可以是含有單個樣本的序列;
- 第二個引數batch_size: 生成的batch的大小;
- 第三個引數num_threads:執行tensor入隊操作的執行緒數量,可以設定使用多個執行緒同時並行執行,提高執行效率,但也不是數量越多越好;
- 第四個引數capacity: 定義生成的tensor序列的最大容量;
- 第五個引數enqueue_many: 定義第一個傳入引數tensors是多個tensor組成的序列,還是單個tensor;
- 第六個引數shapes: 可選引數,預設是推測出的傳入的tensor的形狀;
- 第七個引數dynamic_pad:
定義是否允許輸入的tensors具有不同的形狀,設定為True,會把輸入的具有不同形狀的tensor歸一化到相同的形狀; - 第八個引數allow_smaller_final_batch:
設定為True,表示在tensor佇列中剩下的tensor數量不夠一個batch_size的情況下,允許最後一個batch的數量少於batch_size,設定為False,則不管什麼情況下,生成的batch都擁有batch_size個樣本; - 第九個引數shared_name: 可選引數,設定生成的tensor序列在不同的Session中的共享名稱;
- 第十個引數name: 操作的名稱;
如果tf.train.batch的第一個引數 tensors 傳入的是tenor列表或者字典,返回的是tensor列表或字典,如果傳入的是隻含有一個元素的列表,返回的是單個的tensor,而不是一個列表。
以下舉例: 一共有5個樣本,設定迭代次數是2次,每個batch中含有3個樣本,不打亂樣本順序:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
# 樣本個數
sample_num=5
# 設定迭代次數
epoch_num = 2
# 設定一個批次中包含樣本個數
batch_size = 3
# 計算每一輪epoch中含有的batch個數
batch_total = int(sample_num/batch_size)+1
# 生成4個數據和標籤
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape))
return images,labels
def get_batch_data(batch_size=batch_size):
images, label = generate_data()
# 資料型別轉換為tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32)
#從tensor列表中按順序或隨機抽取一個tensor
input_queue = tf.train.slice_input_producer([images, label], shuffle=False)
image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=1, capacity=64)
return image_batch, label_batch
image_batch, label_batch = get_batch_data(batch_size=batch_size)
with tf.Session() as sess:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess, coord)
try:
for i in range(epoch_num): # 每一輪迭代
print '************'
for j in range(batch_total): #每一個batch
print '--------'
# 獲取每一個batch中batch_size個樣本和標籤
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
# for k in
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError:
print("done")
finally:
coord.request_stop()
coord.join(threads)
輸出:
************
--------
((3, 224, 224, 3), array([0, 1, 2], dtype=int32))
--------
((3, 224, 224, 3), array([3, 4, 0], dtype=int32))
************
--------
((3, 224, 224, 3), array([1, 2, 3], dtype=int32))
--------
((3, 224, 224, 3), array([4, 0, 1], dtype=int32))
每次生成的batch中含有3個樣本,不打亂次序,所以生成的tensor序列是按照‘0,1,2,3,4,0,1,2,3……’排列的。
如果設定每個batch中含有2個樣本,打亂次序,即設定 batch_size = 2, tf.train.slice_input_producer函式中 shuffle=True,輸出為:
************
--------
((2, 224, 224, 3), array([3, 0], dtype=int32))
--------
((2, 224, 224, 3), array([4, 1], dtype=int32))
--------
((2, 224, 224, 3), array([2, 3], dtype=int32))
************
--------
((2, 224, 224, 3), array([1, 0], dtype=int32))
--------
((2, 224, 224, 3), array([2, 4], dtype=int32))
--------
((2, 224, 224, 3), array([1, 4], dtype=int32))
與tf.train.batch函式相對的還有一個tf.train.shuffle_batch函式,兩個函式作用一樣,都是生成一定數量的tensor,組成訓練一個batch需要的資料集,區別是tf.train.shuffle_batch會打亂樣本順序。
最後
程式設計師深度學習微信公眾號, 歡迎關注
