
如果看了此文還不懂 Word2Vec,那是我太笨
轉自http://www.sohu.com/a/128794834_211120
自從 Google 的 Tomas Mikolov 在《Efficient Estimation of Word Representation in Vector Space》提出 Word2Vec,就成為了深度學習在自然語言處理中的基礎部件。Word2Vec 的基本思想是把自然語言中的每一個詞,表示成一個統一意義統一維度的短向量。至於向量中的每個維度具體是什麼意義,沒人知道,也無需知道,也許對應於世界上的一些最基本的概念。但是,讀論文去理解 Word2Vec 的模型生成,依然有些雲裡霧裡,於是只好求助於讀程式碼,然後就茅塞頓開,與大家分享。
任何一門語言,都是由一堆的片語成,所有的詞,構成了一個詞彙表。詞彙表,可以用一個長長的向量來表示。詞的個數,就是詞彙表向量的維度。那麼,任何一個詞,都可以表示成一個向量,詞在詞彙表中出現的位置設為1,其它的位置設為0。但是這種詞向量的表示,詞和詞之間沒有交集,用處不大。
Word2Vec 的訓練模型,看穿了,是具有一個隱含層的神經元網路(如下圖)。它的輸入是詞彙表向量,當看到一個訓練樣本時,對於樣本中的每一個詞,就把相應的在詞彙表中出現的位置的值置為1,否則置為0。它的輸出也是詞彙表向量,對於訓練樣本的標籤中的每一個詞,就把相應的在詞彙表中出現的位置的值置為1,否則置為0。那麼,對所有的樣本,訓練這個神經元網路。收斂之後,將從輸入層到隱含層的那些權重,作為每一個詞彙表中的詞的向量。比如,第一個詞的向量是(w1,1 w1,2 w1,3 ... w1,m),m是表示向量的維度
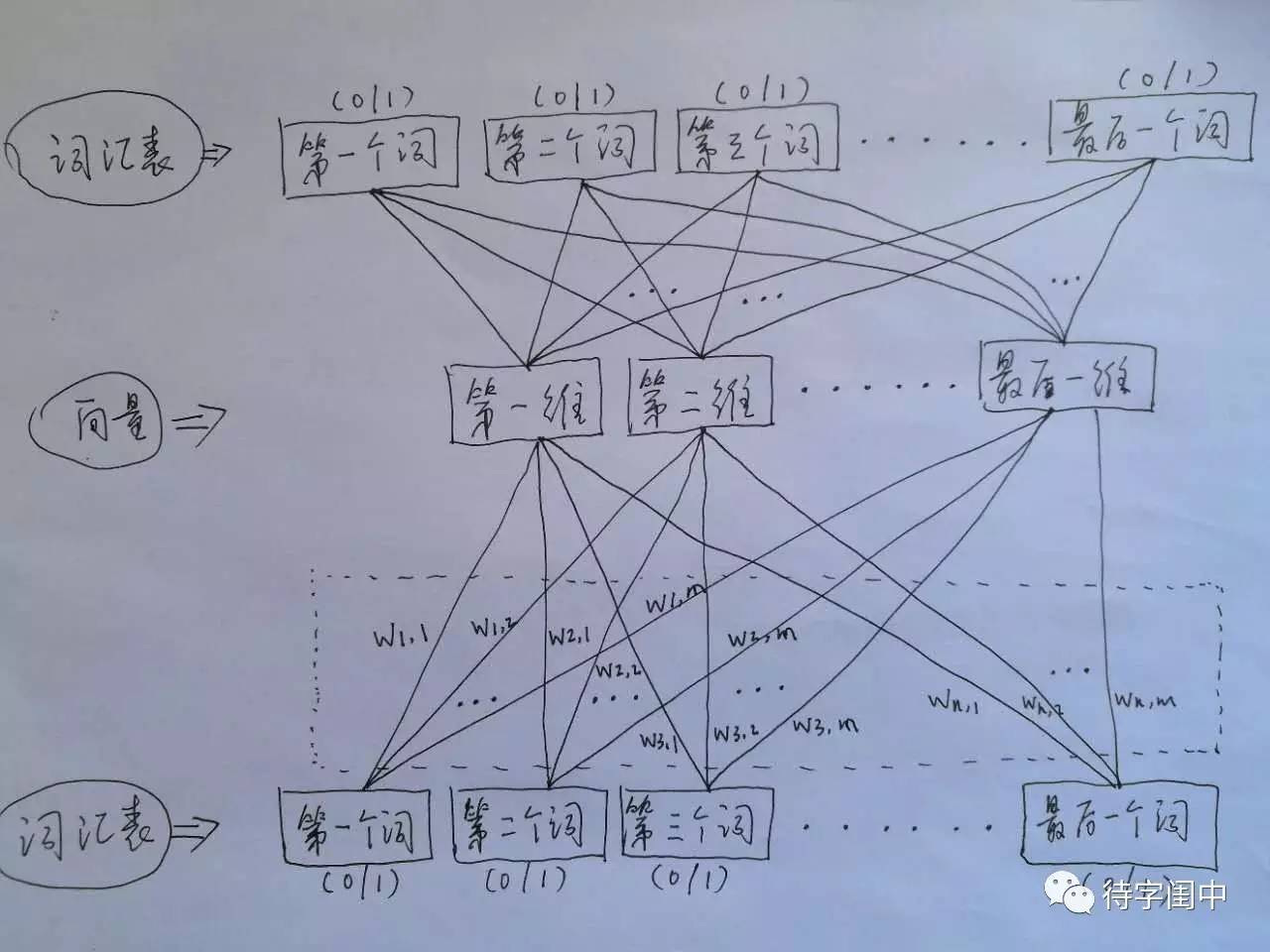
訓練 Word2Vec 的思想,是利用一個詞和它在文字中的上下文的詞,這樣就省去了人工去標註。論文中給出了 Word2Vec 的兩種訓練模型,CBOW (Continuous Bag-of-Words Model) 和 Skip-gram (Continuous Skip-gram Model)。
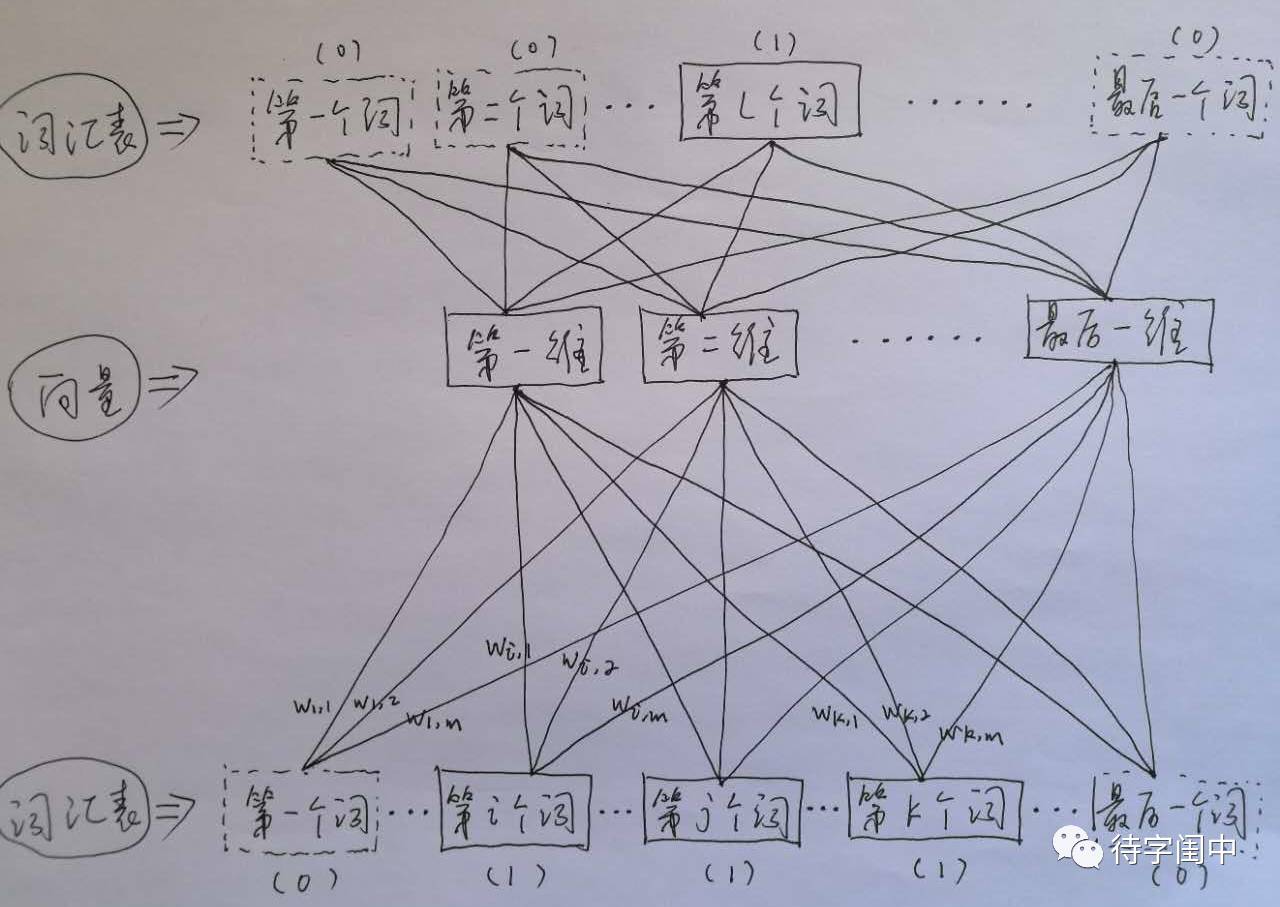
首先看CBOW,它的做法是,將一個詞所在的上下文中的詞作為輸入,而那個詞本身作為輸出,也就是說,看到一個上下文,希望大概能猜出這個詞和它的意思。通過在一個大的語料庫訓練,得到一個從輸入層到隱含層的權重模型。如下圖所示,第l個詞的上下文詞是i,j,k,那麼i,j,k作為輸入,它們所在的詞彙表中的位置的值置為1。然後,輸出是l,把它所在的詞彙表中的位置的值置為1。訓練完成後,就得到了每個詞到隱含層的每個維度的權重,就是每個詞的向量。
Word2Vec 程式碼庫中關於CBOW訓練的程式碼,其實就是神經元網路的標準反向傳播演算法。

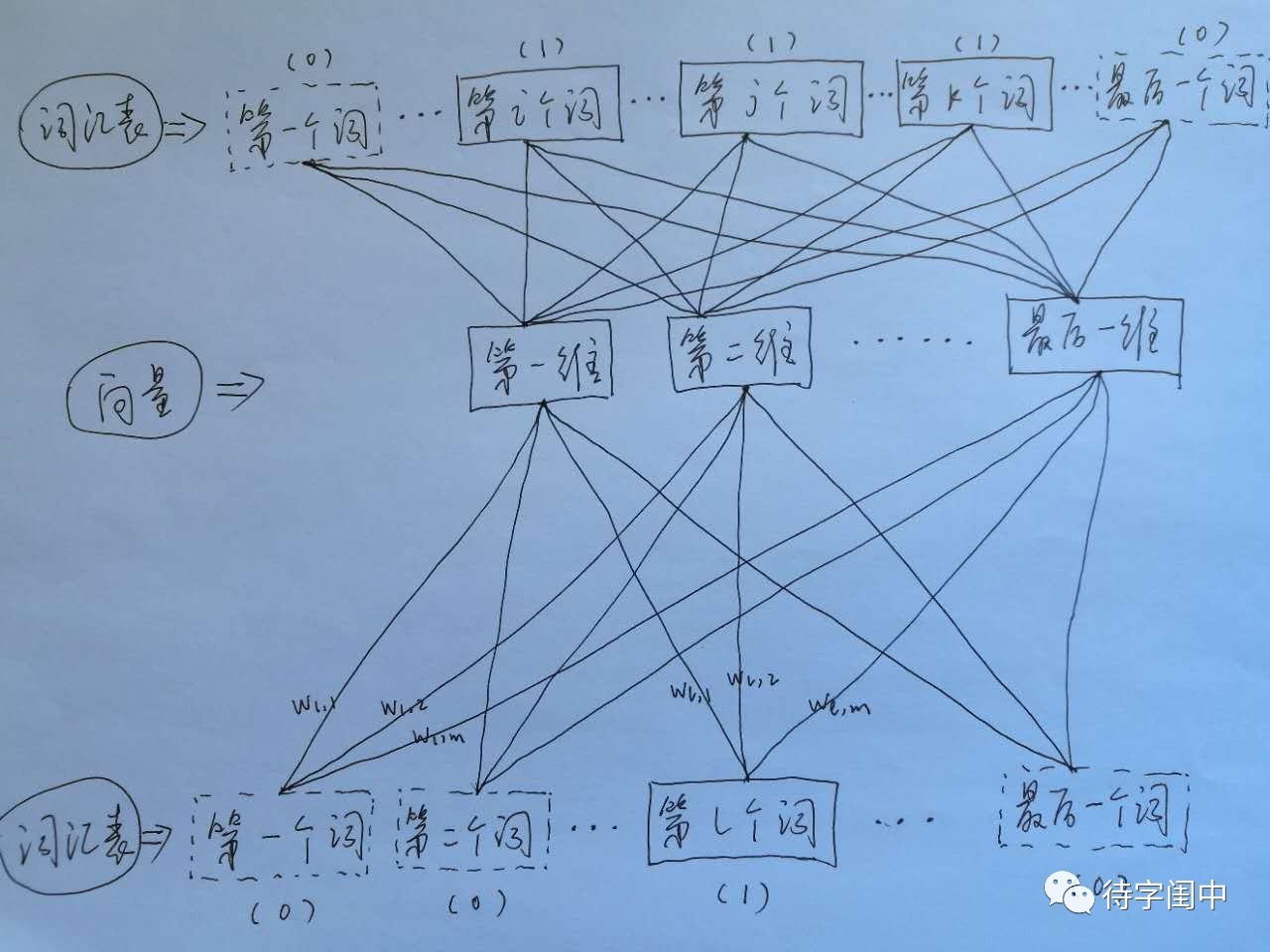
接著,看看Skip-gram,它的做法是,將一個詞所在的上下文中的詞作為輸出,而那個詞本身作為輸入,也就是說,給出一個詞,希望預測可能出現的上下文的詞。通過在一個大的語料庫訓練,得到一個從輸入層到隱含層的權重模型。如下圖所示,第l個詞的上下文詞是i,j,k,那麼i,j,k作為輸出,它們所在的詞彙表中的位置的值置為1。然後,輸入是l,把它所在的詞彙表中的位置的值置為1。訓練完成後,就得到了每個詞到隱含層的每個維度的權重,就是每個詞的向量。
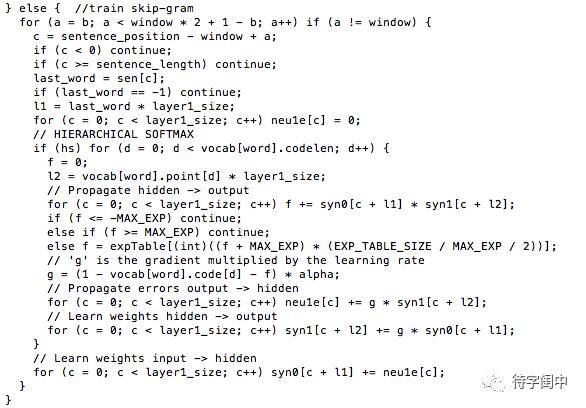
Word2Vec 程式碼庫中關於Skip-gram訓練的程式碼,其實就是神經元網路的標準反向傳播演算法。
一個人讀書時,如果遇到了生僻的詞,一般能根據上下文大概猜出生僻詞的意思,而 Word2Vec 正是很好的捕捉了這種人類的行為,利用神經元網路模型,發現了自然語言處理的一顆原子彈。