
HotSpot虛擬機器GC調優指南
1簡介
從桌面小程式applet到大型伺服器上的Web服務,有各種各樣的應用程式在使用Java平臺,標準版(Java SE)。為了支援這些不同種類的部署,Java HotSpot虛擬機器實現(Java HotSpot VM)提供了多種垃圾收集器,每個垃圾收集器都旨在滿足不同的需求。
Java SE根據執行應用程式的計算機種類選擇最合適的垃圾收集器。但是,這種選擇對於每個應用程式可能都不是最佳的。具有嚴格效能目標或其他要求的使用者,開發人員和管理員可能需要明確選擇垃圾收集器並調整某些引數以達到所需的效能級別。
本文件提供了有助於完成這些任務的資訊。首先,在序列Stop-the-world收集器的上下文中描述了垃圾收集器的一般功能和基本調整選項。然後介紹其他收集器的特定功能以及選擇收集器時要考慮的因素。
垃圾收集器(GC)是一種記憶體管理工具,它通過以下操作實現自動記憶體管理:
• 將物件分配給年輕代並將老物件移到老年代。
• 通過併發(並行)標記階段在老年代中查詢活動物件。當Java堆總佔用率超過預設閾值時,Java HotSpot VM將觸發標記階段。請參閱Concurrent Mark Sweep(CMS)收集器和Garbage-First垃圾收集器部分。
• 通過並行拷貝,壓縮活動物件來恢復可用記憶體。請參閱並行收集器和Garbage-First垃圾收集器部分。
垃圾收集器的選擇在什麼時候很重要?對於某些應用程式,答案是永遠不重要。也就是說,垃圾收集得很好,收集的頻率適度,程式停頓的時間也可以接受。但是,對於大型應用程式來說情況並非如此,特別是那些具有大量資料(GB級以上),多個執行緒和高事務處理率的應用程式。
Amdahl定律(給定問題的並行加速受到問題的序列部分的限制)意味著大多數工作負載無法完美並行化; 某些部分總是序列的,不會受益於並行性。對於Java平臺也是如此。特別是Oracle Java 1.4之前的Java平臺的虛擬機器不支援並行垃圾收集,因此相對於其他並行應用程式而言垃圾收集對多處理器系統的影響更大。
圖1-1中的圖表“比較垃圾收集中花費的時間百分比”模擬了一個理想的系統,除了垃圾收集(GC)之外,它是完全可擴充套件的。紅線是在單處理器系統上僅花費1%的時間用於垃圾收集的應用程式,而具有32個處理器的系統上,吞吐量損失超過20%。洋紅色線顯示,對於花費10%的時間用於垃圾收集的應用程式(不考慮在單處理器應用程式中垃圾收集時間過多),當擴充套件到32個處理器時,超過75%的吞吐量會丟失。
圖1-1比較垃圾收集時間的百分比
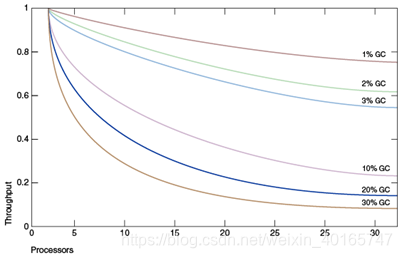
“圖1-1比較垃圾收集時間百分比”的描述
這表明在小型系統上開發時可忽略不計的速度問題可能成為擴充套件到大型系統時的主要瓶頸。然而,在減少這種瓶頸方面的微小改進可以在效能上產生很大的提高。對於足夠大的系統,選擇正確的垃圾收集器並在必要時進行調整是值得的。
序列收集器通常適用於大多數“小型”應用程式(大約100MB堆的現代處理器上)的應用程式。其他收集器具有額外的開銷或複雜性,這是其實現特殊行為的代價。如果應用程式不需要備用收集器的特殊行為,那麼請使用序列收集器。序列收集器不應該是最佳選擇的一種情況是在具有大量記憶體和兩個記憶體的機器上執行的大型高度執行緒化的應用程式,當應用程式在此類伺服器級計算機上執行時,預設情況下會選擇並行收集器。請參閱“人機工程學”一節。
本文件是在使用Solaris作業系統(SPARC Platform Edition)上的Java SE 8的基礎上編寫的。但是,此處提供的概念和建議適用於所有受支援的平臺,包括Linux,Microsoft Windows,Solaris作業系統(x64平臺版)和OS X。此外,所有支援的平臺上都提供了所提到的命令列選項,某些選項的預設值在每個平臺上可能不同。
2 Ergonomics
Ergonomics是Java虛擬機器(JVM)和垃圾收集調優(例如基於行為的調優)提高應用程式效能的過程。JVM為垃圾收集器,堆大小和執行時編譯器提供與平臺相關的預設選擇。這些選擇符合不同型別應用程式的需求,同時需要較少的命令列調整。此外,基於行為的調優動態調整堆的大小以滿足應用程式的指定行為。
本節介紹這些預設選項和基於行為的調整。在使用後續部分中描述的更詳細控制之前,請先使用這些預設值。
- 垃圾收集器,堆和執行時編譯器預設選項
伺服器級機器的配置如下:
• 2個或更多物理處理器
• 2 GB以上的實體記憶體
在伺服器級計算機上,預設情況下選擇以下內容:
• 吞吐量垃圾收集器
• 初始堆大小為1/64的實體記憶體,最大為1 GB
• 最大堆大小為1/4實體記憶體,最大為1 GB
• Server runtime編譯器
有關64位系統的初始堆和最大堆大小,請參閱並行收集器中的“預設堆大小”一節。
伺服器類機器的定義適用於所有平臺,但執行Windows作業系統版本的32位平臺除外。表2-1“預設執行時編譯器”顯示了針對不同平臺的執行時編譯器所做的選擇。
表2-1預設執行時編譯器
| 平臺 | 作業系統 | 預設 | 伺服器類預設 |
|---|---|---|---|
| i586 | Linux | 客戶端 | 伺服器 |
| i586 | 視窗 | 客戶 | 客戶 |
| SPARC(64位) | Solaris | 伺服器 | 伺服器3 |
| AMD(64位) | Linux的 | 伺服器 | 伺服器3 |
| AMD(64位) | 視窗 | 伺服器 | 伺服器3 |
1客戶端表示使用客戶端執行時編譯器。伺服器意味著使用伺服器執行時編譯器。
2選擇策略即使在伺服器類機器上也使用客戶端執行時編譯器。之所以做出這樣的選擇是因為歷史上客戶端應用程式(例如,互動式應用程式)在平臺和作業系統的這種組合上執行得更頻繁。
3僅支援伺服器執行時編譯器。
- 基於行為的調整
對於並行收集器,Java SE提供了兩個基於實現應用程式的指定行為的垃圾收集調整引數:最大停頓時間目標和應用程式吞吐量目標; 請參閱並行收集器一節。(這兩個選項在其他收集器中不可用。)請注意,不能始終滿足這些行為。應用程式需要一個足夠大的堆來至少儲存所有活著的資料。此外,最小堆大小可能妨礙達到這些期望的目標。
- 最長停頓時間目標
停頓時間是垃圾收集器停止應用程式並恢復不再使用的空間的持續時間。最大停頓時間目標的意圖是限制這些停頓的最長時間。垃圾收集器維護平均停頓時間和平均值的方差,平均值是從執行開始時獲得的,但是是加權的,越近期的停頓權值越大。如果平均值加上停頓時間的方差大於最大停頓時間目標,則垃圾收集器認為目標未得到滿足。
使用命令列選項指定最大停頓時間目標-XX:MaxGCPauseMillis=。是需要停頓毫秒。垃圾收集器將調整Java堆大小和與垃圾收集相關的其他引數,以嘗試使垃圾收集停頓時間短於毫秒。預設情況下,沒有最大停頓時間目標。這些調整可能會導致垃圾收集器更頻繁地發生,從而降低了應用程式的整體吞吐量。垃圾收集器嘗試在吞吐量目標之前滿足任何停頓時間目標。但是,在某些情況下,無法滿足所需的停頓時間目標。
- 吞吐量目標
吞吐量目標是根據收集垃圾所花費的時間和垃圾收集之外所花費的時間(稱為應用程式時間)來衡量的。目標由命令列選項指定-XX:GCTimeRatio=。垃圾收集時間與應用時間的比率為1 /(1 + )。例如,-XX:GCTimeRatio=19設定垃圾收集總時間的1/20或5%的目標。
垃圾收集所花費的時間是年輕代和老年代收集的總時間。如果未滿足吞吐量目標,則增加代的大小以努力增加應用程式在收集之間執行的時間。
- 佔用空間目標
如果已滿足吞吐量和最大停頓時間目標,則垃圾收集器會減小堆的大小,直到無法滿足其中一個目標(總是吞吐量目標),然後解決未達到的目標。
- 調優策略
除非您知道需要的堆大於預設的最大堆大小,否則不要為堆選擇最大值。選擇足以滿足您的應用程式的吞吐量目標。
堆將增大或縮小到支援所選吞吐量目標的大小。應用程式行為的更改可能導致堆增長或縮小。例如,如果應用程式開始以更高的速率分配,則堆將增長以保持相同的吞吐量。
如果堆增長到其最大大小並且未滿足吞吐量目標,則最大堆大小對於吞吐量目標而言太小。將最大堆大小設定為接近平臺上的總實體記憶體但不會導致應用程式交換的值。再次執行應用程式。如果仍未達到吞吐量目標,則應用程式時間的目標對於平臺上的可用記憶體來說太高。
如果可以滿足吞吐量目標,但停頓時間過長,則選擇最大停頓時間目標。選擇最大停頓時間目標可能意味著您的吞吐量目標將無法滿足,因此請選擇對應用程式而言可接受的折衷的值。
當垃圾收集器試圖滿足競爭目標時,堆的大小通常會振盪。即使應用程式已達到穩定狀態,也是如此。實現吞吐量目標(可能需要更大的堆)的壓力是與最大停頓時間的目標和最小佔用空間的目標(兩者都可能需要小堆)相競爭。
3 世代
Java SE平臺的一個優勢是它可以保護開發人員免受記憶體分配和垃圾收集複雜性的影響。但是,當垃圾收集是主要瓶頸時,瞭解此隱藏實現很有用。垃圾收集器對應用程式使用物件的方式做出假設,這些可以反映在可調引數中,可以調整這些引數以提高效能,而不會犧牲抽象的功能。
當一個物件無法再從正在執行的程式中的任何指標訪問時,它被認為是垃圾。最直接的垃圾收集演算法是迭代每個可到達的物件。剩下的任何物體都被認為是垃圾。這種方法所花費的時間與活動物件的數量成正比,這對於維護大量實時資料的大型應用程式來說是不可行的。
虛擬機器包含許多不同的垃圾收集演算法,這些演算法使用世代集合進行組合。簡單的垃圾收集檢查堆中的每個活動物件,而分代收集利用幾個經驗觀察的大多數應用程式的屬性,以使回收未使用(垃圾)物件所需的工作最小化。所觀察的屬性中最重要的是弱世代假說:大多數物件只能存活很短的時間。
圖3-1中的藍色區域是物件生命週期的典型分佈。x軸是以分配的位元組為單位測量的物件生命週期。y軸上的位元組數是具有相應生命週期的物件中的總位元組數。左邊的尖峰表示在分配後不久可以回收的物體(換句話說,已經“死亡”)。例如,迭代器物件在單個迴圈的持續時間內通常是活動的。
圖3-1物件生命週期的典型分佈
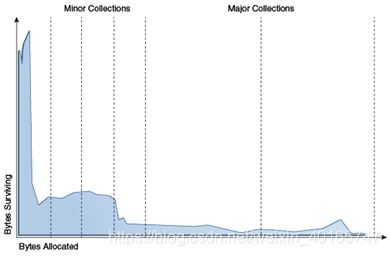
“圖3-1物件生命週期的典型分佈”的描述
有些物件的生命週期很長,因此分佈向右延伸。例如,通常在初始化時分配一些物件,這些物件一直存在直到程序退出。在這兩個極端之間是在一些中間計算期間存活的物件,在這裡看作是初始峰值右側的塊。一些應用具有非常不同的分佈,但是大多數具有這種一般形狀。通過關注大多數物件“年輕時死亡”這一事實,可以實現高效收集。
為了優化這種情況,記憶體是在世代中管理的(記憶體池包含不同年齡的物件)。當某個世代填滿時,會發生垃圾收集。絕大多數物件都分配在年輕物件(年輕代)池中,並且大多數物件都在那裡死亡。當年輕代填滿時,它會導致一個小小的收集只收集年輕代;其他世代的垃圾沒有回收。
假設弱世代假說成立,並且年輕代中的大多數物體都是垃圾並且可以被回收,則可以優化為minor收集。這些收集的成本,按照第一順序,與收集的活動物件的數量成比例;很快就會收集到充滿死亡物件的年輕代。通常,來自年輕代的倖存物件的一部分在每次minor收集期間被移動到老年代。最終,老年代將填滿並必須收集,從而產生一個major收集,即收集整個堆。major收集通常比minor收集持續更長時間,因為涉及的物件數量明顯更多。
如Ergonomics部分所述,Ergonomics動態選擇垃圾收集器,以在各種應用程式上提供良好的效能。序列垃圾收集器專為具有小型資料集的應用程式而設計,其預設引數被選擇為對大多數小型應用程式有效。並行或吞吐量垃圾收集器旨在用於具有中到大資料集的應用程式。由Ergonomics選擇的堆大小引數加上自適應大小策略的功能旨在為伺服器應用程式提供良好的效能。這些選擇適用於大多數情況,但不是所有情況,這導致了本文件的核心原則:
注意:
如果垃圾收整合為瓶頸,您很可能必須自定義總堆大小以及各代的大小。檢查詳細的垃圾收集器輸出,然後探索各個效能指標對垃圾收集器引數的敏感性。
圖3-2,“除了並行收集器和G1之外,世代的預設排列”
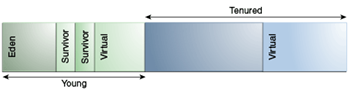
“圖3-2世代預設排列,並行收集器和G1除外”的說明
在初始化時,除非需要,否則實際上保留了最大地址空間但未分配給實體記憶體。為物件儲存器保留的完整地址空間可以分為年輕和老年代。
年輕代由Eden和兩個倖存者空間組成。大多數物件最初都是在Eden中分配的。一個倖存者空間在任何時候都是空的,並且作為Eden中任何活動物件的目的地;另一個倖存者空間是下一個複製收集的目的地。以這種方式在倖存者空間之間複製物件,直到它們足夠老到老年代(複製到老年代)。
- 效能注意事項
垃圾收集效能有兩個主要指標:
• 吞吐量是未垃圾收集總時間的百分比。吞吐量包括分配所花費的時間(但通常不需要調優分配速度)。
• 停頓是應用程式顯示無響應的時間,因為正在進行垃圾收集。
使用者對垃圾收集有不同的要求。例如,有些人認為Web伺服器的正確度量標準是吞吐量,因為垃圾收集期間的停頓可能是可以容忍的,或者只是被網路延遲所掩蓋。但是,在互動式圖形程式中,即使短停頓頓也可能對使用者體驗產生負面影響。
一些使用者對其他考慮因素很敏感。佔用空間是一個程序的工作集,以頁和快取行來衡量。在具有有限實體記憶體或許多程序的系統上,佔用空間可能會影響可伸縮性。
及時性是指物件變為死亡和記憶體可用之間的時間,這是分散式系統的一個重要考慮因素,包括遠端方法呼叫(RMI)。
通常,選擇特定世代的尺寸以權衡這些因素。例如,非常大的年輕代可以最大化吞吐量,但這樣做是以佔用空間,及時性和停頓時間為代價的。年輕代的停頓可以通過使用小型年輕代來最小化,如此會影響吞吐量。一世代的大小不會影響另一代的收集頻率和停頓時間。
沒有一種正確的方法可以選擇世代大小。最佳選擇取決於應用程式使用記憶體的方式以及使用者要求。因此,虛擬機器對垃圾收集器的選擇並不總是最佳的。
- 測量
使用應用程式特定的目標值是測量吞吐量和佔用空間最好方法。例如,可以使用客戶端負載生成器測試Web伺服器的吞吐量,而在Solaris作業系統上可以使用pmap命令測量伺服器的佔用空間。通過檢查虛擬機器本身的診斷輸出,可以輕鬆估計由於垃圾回收導致的停頓。
命令列選項-verbose:gc會在每次收集中列印有關堆和垃圾回收的資訊。例如,從大型伺服器應用程式輸出:
[GC 325407K-> 83000K(776768K),0.2300771 secs]
[GC 325816K-> 83372K(776768K),0.2454258 secs]
[Full GC 267628K-> 83769K(776768K),1.8479984 secs]
輸出顯示兩個minor收集,和一個major收集。箭頭前後的數字(例如,第一行的325407K->83000K)分別表示垃圾收集之前和之後的活動物件的組合大小。在minor收集之後,大小包括一些垃圾(不再存活)但無法回收的物件。這些物件要麼包含在老年代中,要麼被老年代引用。
括號中的數字(例如,(776768K))是堆可用大小:可用於Java物件的空間量,而無需從作業系統請求更多記憶體。請注意,此數字僅包括一個倖存者空間。除了在垃圾收集期間,在任何給定時間僅使用一個倖存者空間來儲存物件。
該行的最後一項(例如0.2300771 secs)表示執行收集所花費的時間,在這種情況下大約是四分之一秒。
第三行中major收集的格式類似。
注意: 產生的輸出格式-verbose:gc在未來版本中可能會有所變化。
命令列選項-XX:+PrintGCDetails會輸出有關要列印的其他資訊,此處顯示了使用序列垃圾收集器的輸出示例。
[GC [DefNew:64575K-> 959K(64576K),0.0457646秒] 196016K-> 133633K(261184K),0.0459067秒]
這表明minor收集恢復了約98%的年輕一代,DefNew: 64575K->959K(64576K)並且0.0457646 secs(約45毫秒)。
整個堆的使用減少到大約51%(196016K->133633K(261184K)),並且收集(在年輕代收集)有一些輕微的額外開銷,如最終時間所示0.0459067 secs。
注意: 產生的輸出格式-XX:+PrintGCDetails在未來版本中可能會有所變化。
該選項-XX:+PrintGCTimeStamps在每個收集的開頭新增時間戳,這對於檢視垃圾收集發生的頻率很有用。
111.042:[GC 111.042:[DefNew:8128K-> 8128K(8128K),0.0000505 secs] 111.042:[Tenured:18154K-> 2311K(24576K),0.1290354 secs] 26282K-> 2311K(32704K),0.1293306 secs]
該收集開始執行應用程式大約111秒。minor收集大約在同一時間開始。此外,還顯示了由老年代描繪的主要收集資訊。老年代使用量減少到約10%(18154K->2311K(24576K))並花費0.1290354 secs(約130毫秒)。
4 確定世代的大小
許多引數會影響世代的大小。圖4-1“堆引數”說明了堆中的已保留的空間和虛擬空間之間的差異。在初始化虛擬機器時,將保留堆的整個空間。可以使用-Xmx選項指定保留空間的大小。如果-Xms引數的值小於-Xmx引數的值,則不會立即將所有保留的空間提交給虛擬機器。未保留的空間在此圖中標記為“虛擬”。堆的不同部分(老年代和年輕代)可以根據需要增長到虛擬空間的極限。
一些引數是堆的一部分與另一部分的比率。例如,引數NewRatio表示老年代與年輕代的相對大小。
圖4-1堆引數
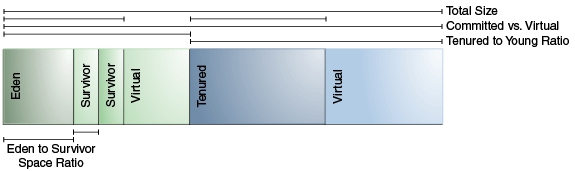
“圖4-1堆引數”的說明
總堆
以下關於堆和預設堆大小的增長和收縮的討論不適用於並行收集器。(見在確定世代大小並行收集Ergonomics節,有關於並行收集器調整堆大小和堆預設大小的詳細資訊。)然而,控制堆的總大小和世代的尺寸的引數確實適用於並行收集。
影響垃圾收集效能的最重要因素是總可用記憶體。由於收集發生在記憶體被填滿時,因此吞吐量與可用記憶體量成反比。
預設情況下,虛擬機器在每次收集中增大或縮小堆,以嘗試將可用空間的比例保持在特定範圍內以儲存活動的物件。此目標範圍設定為由引數百分比-XX:MinHeapFreeRatio=和-XX:MaxHeapFreeRatio=,並且總尺寸下限是-Xms及上限是-Xmx。表4-1“64位Solaris作業系統的預設引數”中顯示了64位Solaris作業系統(SPARC Platform Edition)的預設引數:
表4-1 64位Solaris作業系統的預設引數
| 引數 | 預設值 |
|---|---|
| MinHeapFreeRatio | 40 |
| MaxHeapFreeRatio | 70 |
| -Xms | 6656k |
| -Xmx | calculated |
使用這些引數,如果一代中的可用空間百分比低於40%,則生成將擴充套件為維持40%的可用空間,直到生成的最大允許大小。類似地,如果自由空間超過70%,那麼將收縮這一代,使得只有70%的空間是免費的,受制於該代的最小尺寸。
如表4-1“64位Solaris作業系統的預設引數”中所述,預設的最大堆大小是由JVM計算的值。Java SE中用於並行收集器和伺服器JVM的計算現在用於所有垃圾收集器。部分計算是32位平臺和64位平臺上最大堆大小的上限。請參閱並行收集器中的預設堆大小部分。客戶端JVM有類似的計算,這導致最大堆大小小於伺服器JVM。
以下是有關伺服器應用程式的堆大小的一般準則:
• 除非您遇到停頓問題,否則請儘量為虛擬機器授予儘可能多的記憶體。預設大小通常太小。
• 將Xms和-Xmx設定為相同的值可關閉虛擬機器的大小決策,以提高可預測性。但是,如果你做出糟糕的選擇,則虛擬機器無法補救。
• 通常,在增加處理器數量時增加記憶體,因為分配可以並行化。
- 年輕代
除了總可用記憶體,影響垃圾收集效能的第二個最有影響的因素是專用於年輕代堆的比例。年輕代越大,發生的minor收集就越少。但是,對於有限的堆大小,較大的年輕代意味著較小的老年代,這將增加major收集的頻率。最佳選擇取決於應用程式分配的物件的生命週期分佈。
預設情況下,年輕代的大小由引數NewRatio控制。例如,設定-XX:NewRatio=3意味著年輕和老年代之間的比例是1:3。換句話說,Eden和倖存者空間的組合大小將是總堆大小的四分之一。
引數NewSize和MaxNewSize限制年輕代的大小。將這些設定為相同的值可以固定年輕代的大小,就像設定-Xms和-Xmx為相同的值一樣。以這種更細的粒度調優年輕代,比用NewRatio以整數倍調整更有幫助。
- 倖存者空間大小
您可以使用該引數SurvivorRatio來調整倖存者空間的大小,但這通常對效能不重要。例如,-XX:SurvivorRatio=6將eden和倖存者空間之間的比率設定為1:6。換句話說,每個倖存者空間將是eden大小的六分之一,因此是年輕代的八分之一(不是七分之一,因為有兩個倖存者空間)。
如果倖存者空間太小,則複製收集會直接溢位到老年代。如果倖存者空間太大,它們將毫無用處。在每次垃圾收集時,虛擬機器會選擇一個閾值編號,該閾值編號是物件在終止之前可以複製的次數。選擇此閾值是為了使倖存者空間保持半滿。命令列選項-XX:+PrintTenuringDistribution(不是所有的垃圾收集器都可用)可用於顯示此閾值和新世代中物件的年齡。它對於觀察應用程式的生命週期分佈也很有用。
表4-2“Survivor Space Sizing的預設引數值”提供了64位Solaris的預設值:
表4-2 Survivor Space Sizing的預設引數值
引數 伺服器JVM預設值
| NewRatio | 2 |
|---|---|
| NewSize | 1310M |
| MaxNewSize | 不限 |
| SurvivorRatio | 8 |
年輕代的最大值將根據總堆的最大值和NewRatio引數的值來計算。MaxNewSize引數的“不受限制”預設值意味著計算值不受MaxNewSize限制,除非MaxNewSize在命令列中指定了值。
以下是伺服器應用程式的一般準則:
• 首先確定您可以為虛擬機器提供的最大堆大小。然後根據年輕代尺寸繪製效能指標,以找到最佳設定。
o 請注意,最大堆大小應始終小於計算機上安裝的記憶體量,以避免過多的頁面錯誤(page faults)和抖動。
• 如果總堆大小是固定的,那麼增加年輕代的大小會減少老年代大小。保持老年代足夠大,以容納應用程式在任何給定時間使用的所有實時資料,加上一些餘量空間(10到20%或更多)。
• 根據先前對老年代的約束:
o 給年輕代留下充足的記憶體。
o 隨著處理器數量的增加,增加年輕代的大小,因為分配可以並行化。
5 收集器
- 收集器種類
Java HotSpot VM包括三種不同型別的收集器,每種收集器具有不同的效能特徵。
• 序列收集器使用單個執行緒來執行所有垃圾收集工作,這使得它相對有效,因為執行緒之間沒有通訊開銷。它最適合單處理器機器,因為它無法利用多處理器硬體,儘管它對於具有小資料集(最大約100 MB)的應用程式的多處理器非常有用。預設情況下,在某些硬體和作業系統配置上選擇序列收集器,或者可以使用該選項顯式啟用序列收集器-XX:+UseSerialGC。
• 並行收集器(也稱為吞吐量收集器)並行執行minor收集,這可以顯著減少垃圾收集開銷。它適用於在多處理器或多執行緒硬體上執行的具有中型到大型資料集的應用程式。預設情況下,在某些硬體和作業系統配置上選擇並行收集器,或者可以使用該選項顯式啟用並行收集器-XX:+UseParallelGC。
o 並行壓縮是一種使並行收集器能夠並行執行major收集的功能。如果沒有並行壓縮,major收集將使用單個執行緒執行,這可能會限制可伸縮性。如果-XX:+UseParallelGC已指定選項,則預設啟用並行壓縮。關閉它的選項是-XX:-UseParallelOldGC。
• 大多數併發收集器同時執行大部分工作(例如,在應用程式仍在執行時)以防止垃圾收集停頓。它適用於具有中型到大型資料集的應用程式,其中響應時間比總吞吐量更重要,因為用於最小化停頓的技術會降低應用程式效能。Java HotSpot VM提供兩個主要併發收集器之間的選擇; 參考常見收集器。使用選項-XX:+UseConcMarkSweepGC可啟用CMS收集器或-XX:+UseG1GC啟用G1收集器。
- 選擇收集器
除非您的應用程式具有相當嚴格的停頓時間要求,否則首先執行您的應用程式並允許VM選擇收集器。如有必要,請調整堆大小以提高效能。如果效能仍不符合您的目標,請使用以下指南作為選擇收集器的起點。
• 如果應用程式具有較小的資料集(最大約100 MB),那麼選擇序列收集器 -XX:+UseSerialGC。
• 如果應用程式將在單個處理器上執行且沒有停頓時間要求,則讓VM選擇收集器,或選擇帶有該選項的序列收集器-XX:+UseSerialGC。
• 如果(a)峰值應用程式效能是第一優先順序,並且(b)沒有停頓時間要求或1秒或更長的停頓是可接受的,則讓VM選擇收集器,或選擇並行收集器-XX:+UseParallelGC。
• 如果響應時間比總吞吐量更重要,並且垃圾收集停頓必須保持短於大約1秒,則使用-XX:+UseConcMarkSweepGC或選擇併發收集器-XX:+UseG1GC。
這些指南僅提供了選擇收集器的起點,因為效能取決於堆的大小,應用程式維護的實時資料量以及可用處理器的數量和速度。停頓時間對這些因素特別敏感,因此前面提到的1秒閾值只是近似值:並行收集器在許多資料大小和硬體組合上將經歷超過1秒的停頓時間; 相反,併發收集器可能無法在某些組合上保持短於1秒的停頓。
如果推薦的收集器未達到所需效能,請首先嚐試調整堆和生成大小以滿足所需目標。如果效能仍然不足,那麼嘗試使用不同的收集器:使用併發收集器來減少停頓時間,並使用並行收集器來提高多處理器硬體的總吞吐量。
6 並行收集器
並行收集器(這裡也稱為吞吐量收集器)是類似於序列收集器的新代收集器; 主要區別在於多個執行緒用於加速垃圾收集。使用命令列選項啟用並行收集器-XX:+UseParallelGC。預設情況下,使用此選項,並行執行minor和major收集,以進一步減少垃圾收集開銷。
有N個硬體執行緒,其中N大於8的機器上,並行收集器使用的一個固定分數N作為垃圾收集執行緒的數量。對於較大的N值,該分數約為5/8。在N值低於8時,使用的數字是N.。在一些選定的平臺上,分數降至5/16。可以使用命令列選項(稍後描述)調整垃圾收集器執行緒的特定數量。在具有一個處理器的主機上,由於並行執行所需的開銷(例如,同步),並行收集器的效能可能不如序列收集器。但是,在執行具有中型到大型堆的應用程式時,它通常在具有兩個處理器的計算機上的效能優於序列收集器,並且當有兩個以上處理器可用時,通常比序列收集器表現更好。
可以使用命令列選項控制垃圾收集器執行緒的數量 -XX:ParallelGCThreads=。如果使用命令列選項對堆進行顯式調整,那麼並行收集器的良好效能所需的堆大小與序列收集器所需的大小相同。但是,啟用並行收集器應使收集停頓時間更短。因為多個垃圾收集器執行緒正在參與minor收集,所以在從年輕代升級到老年代期間,可能存在一些碎片。minor收集中每個垃圾收集執行緒保留一部分用於升級的老年代,並且為這些“升級緩衝區” 劃分空間可能導致碎片效應。減少垃圾收集器執行緒的數量並增加老年代的大小可以減少這種碎片效應。
- 世代
如前所述,並行收集器中世代的排列是不同的。如圖6-1“並行收集器中的生成安排”所示:
圖6-1並行收集器中的世代排列
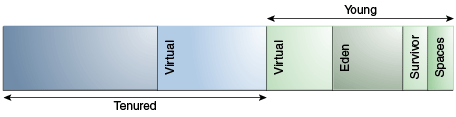
“圖6-1並行收集器中的世代排列”的描述
- 並行收集器Ergonomics
預設情況下,在伺服器級計算機上選擇並行收集器。此外,並行收集器使用自動調整方法,允許您指定特定行為,而不是世代大小和其他低階調整細節。您可以指定最大垃圾收集停頓時間,吞吐量和佔用空間(堆大小)。
• 最大垃圾收集停頓時間:使用命令列選項指定最大停頓時間目標-XX:MaxGCPauseMillis=。這被解釋為需要停頓毫秒或更短的停頓時間的提示; 預設情況下,沒有最大停頓時間目標。如果指定了停頓時間目標,則會調整堆大小和與垃圾回收相關的其他引數,以嘗試使垃圾回收停頓時間短於指定值。這些調整可能導致垃圾收集器降低應用程式的總吞吐量,並且不能始終滿足所需的停頓時間目標。
• 吞吐量:吞吐量目標是根據垃圾收集所花費的時間與垃圾收集之外所花費的時間(稱為應用程式時間)來衡量的。目標由命令列選項指定,該選項-XX:GCTimeRatio=設定垃圾收集時間與應用程式時間的比率1 / (1 + )。
例如,-XX:GCTimeRatio=19將目標設定為垃圾收集中總時間的1/20或5%。預設值為99,垃圾回收的則目標為1%。
• 佔用空間:最大堆佔用空間使用選項指定-Xmx。此外滿足其他目標,收集器有一個隱含的目標,即最小化堆的大小。
- 目標優先權
目標按以下順序解決:
- 最大停頓時間目標
- 吞吐量目標
- 最小佔用空間目標
首先滿足最大停頓時間目標。只有在滿足後才能解決吞吐量目標。同樣,只有在滿足前兩個目標之後才考慮佔用空間目標。
- 世代大小調整
收集器保留的平均停頓時間等統計資訊將在每個收集的末尾更新,然後確定是否滿足目標的測試,並對世代的尺寸進行任何所需的調整。一個例外是,顯式垃圾收集(例如,呼叫System.gc())不保持統計資料和調整世代大小。
增長和縮小世代的尺寸是通過增量來完成的,這些增量是世代的尺寸的固定百分比,以便世代增長減少以達到其期望的尺寸。增長和縮小以不同的速度完成。預設情況下,世代以20%的增量增長,並以5%的增量縮小。年輕代增長百分比由-XX:YoungGenerationSizeIncrement=控制,XX:TenuredGenerationSizeIncrement=命令列選項控制老年代。通過命令列標誌調整世代收縮的百分比-XX:AdaptiveSizeDecrementScaleFactor=。如果增長增量為X%,那麼收縮的減少量是X / D百分比。
如果收集器決定在啟動時增長世代大小,則會在增量中新增補充百分比。這種補充隨著收集的數量而衰減,並且沒有長期影響。補充的目的是提高啟動效能。縮小沒有補充百分比。
如果未滿足最大停頓時間目標,則縮小一次一個世代的大小。如果兩世代的停頓時間都高於目標,那麼具有較大停頓時間的世代的大小首先縮小。
如果不滿足吞吐量目標,則增加兩世代的大小。每個都與其對垃圾收集總時間的貢獻成比例地增加。例如,如果年輕代的垃圾收集時間是總收集時間的25%,並且如果年輕代的完全增量是20%,那麼年輕代將增加5%。
- 預設堆大小
除非在命令列中指定了初始和最大堆大小,否則它們將根據計算機上的記憶體量進行計算。
客戶端JVM預設初始和最大堆大小
最大實體記憶體大小為192兆(MB)時,預設的最大堆大小是實體記憶體的一半,否則最大實體記憶體大小為1千兆(GB)時, 預設的最大堆大小為實體記憶體的四分之一。
例如,如果您的計算機具有128 MB的實體記憶體,則最大堆大小為64 MB,並且大於或等於1 GB的實體記憶體會導致最大堆大小為256 MB。
除非程式建立足夠的物件,否則JVM實際上不會使用最大堆大小。在JVM初始化期間分配一個小得多的數量,稱為初始堆大小。此數量至少為8 MB,然後為實體記憶體的1/64,直到實體記憶體大小為1 GB。
分配給年輕代的最大空間量是總堆大小的三分之一。
伺服器JVM預設初始和最大堆大小
預設的初始和最大堆大小在伺服器JVM上的工作方式與在客戶端JVM上的工作方式類似,只是預設值可以更高。在32位JVM上,如果有4 GB或更多實體記憶體,則預設最大堆大小最多可達1 GB。在64位JVM上,如果存在128 GB或更多實體記憶體,則預設最大堆大小最多可為32 GB。您可以通過直接指定這些值來設定更高或更低的初始和最大堆; 見下一節。
指定初始和最大堆大小
您可以使用標誌-Xms(初始堆大小)和-Xmx(最大堆大小)指定初始和最大堆大小。如果您知道應用程式需要多少堆才能正常工作,則可以設定-Xms和-Xmx使用相同的值。如果沒有,JVM將首先使用初始堆大小,然後增加Java堆,直到它在堆使用和效能之間找到平衡。
其他引數和選項可能會影響這些預設值。要驗證預設值,請使用該-XX:+PrintFlagsFinal選項並MaxHeapSize在輸出中查詢。例如,在Linux或Solaris上,您可以執行以下命令:
java -XX:+ PrintFlagsFinal -version | grep MaxHeapSize
- 過多的GC時間和OutOfMemoryError
如果在垃圾收集(GC)中花費了太多時間,那麼並行收集器會丟擲OutOfMemoryError:如果在垃圾收集中花費了超過98%的總時間並且恢復了不到2%的堆,則丟擲OutOfMemoryError。此功能旨在防止應用程式由於堆太小長時間執行,同時沒有什麼進展。如有必要,可以通過-XX:-UseGCOverheadLimit在命令列中新增選項來禁用此功能。
- 測量
並行收集器的詳細垃圾收集器輸出與序列收集器的輸出基本相同。
7 常見的併發收集器
Java Hotspot VM在JDK 8中有兩個主要是併發的收集器:
• 併發標記掃描(CMS)收集器:此收集器適用於垃圾收集停頓較短,並可以與垃圾收集共享處理器資源的應用程式。
• Garbage-First垃圾收集器:這種伺服器式收集器適用於具有大記憶體的多處理器機器。它以高概率滿足垃圾收集停頓時間目標,同時實現高吞吐量。
- 併發的開銷
大多數併發收集器交換處理器資源(否則可供應用程式使用)以縮短major收集停頓時間。最明顯的開銷是在收集的併發部分期間使用一個或多個處理器。在N處理器系統上,收集的併發部分將使用可用處理器的K / N,其中1 <= K <= ceiling { N / 4}。(K的精確選擇和界限可能會發生變化。)除了在併發階段使用處理器之外,還會產生額外的開銷以實現併發。因此,雖然併發收集器的垃圾收集停頓通常要短得多,但應用程式吞吐量也往往略低於其他收集器。
在具有多個處理核心的計算機上,在收集的併發部分期間處理器可用於應用程式執行緒,因此併發垃圾收集器執行緒不會“停頓”應用程式。這通常會導致停頓時間縮短,但應用程式可用的處理器資源也會減少,並且應該會有一些減速,特別是如果應用程式最大限度地使用所有處理核心。隨著N的增加,由於併發垃圾收集變得更小會減少處理器資源的使用,併發收集的益處增加。並行模式失敗在併發標記掃描(CMS)收集器部分會討論這種擴充套件的潛在限制。
因為在併發階段期間至少有一個處理器用於垃圾收集,所以併發收集器通常不會在單處理器(單核)機器上提供任何好處。但是,CMS(不是G1)有一個單獨的模式,可以在只有一個或兩個處理器的系統上實現低停頓; 參考增量模式在併發標記掃描(CMS)收集器的詳細資訊。此功能在Java SE 8中已棄用,可能會在以後的主要版本中刪除。
- 其他參考文獻
Garbage-First垃圾收集器:http://www.oracle.com/technetwork/java/javase/tech/g1-intro-jsp-135488.html
Garbage-First收集器調優:http://www.oracle.com/technetwork/articles/java/g1gc-1984535.html
8 併發標記掃描(CMS)收集器
併發標記掃描(CMS)收集器專為需要較短垃圾收集停頓,且能夠在應用程式執行時與垃圾收集器共享處理器資源的應用程式而設計的。通常,具有相對大的長壽命資料集(大型老年代)並在具有兩個或更多處理器的機器上執行的應用程式傾向於從該收集器的使用中受益。但是,對於任何停頓時間要求較低的應用程式,都應考慮使用此收集器。使用命令列選項啟用CMS收集器-XX:+UseConcMarkSweepGC。
與其他可用的收集器類似,CMS收集器是世代的,因此會發生minor和major收集。CMS收集器嘗試通過使用單獨的垃圾收集器執行緒在執行應用程式執行緒的同時跟蹤可訪問的物件來減少由於major收集而導致的停頓時間。在每個major收集週期中,CMS收集器會在收集開始時停頓所有應用程式執行緒,併到收集的中間位置再次停頓。第二次停頓往往是較長。在兩個停頓期間,多個執行緒用於執行收集工作。
- 併發模式失敗
CMS收集器使用一個或多個與應用程式執行緒同時執行的垃圾收集器執行緒,目標是在堆滿之前完成老年代的收集。如前所述,在正常操作中,CMS收集器在應用程式執行緒仍在執行時執行大部分跟蹤和掃描工作,因此應用程式執行緒只能看到短暫的停頓。但是,如果CMS收集器無法在老年代填滿之前完成對無法訪問的物件的回收,或者如果無法使用老年代中的可用空閒塊滿足分配,則應用程式將停頓,直到收集完成。
無法同時完成收集稱為併發模式失敗,這時需要調整CMS收集器的引數。如果併發收集被顯式垃圾收集(System.gc())中斷或者為診斷工具提供資訊所需的垃圾收集,則報告併發模式中斷。
- 過多的GC時間和OutOfMemoryError
如果在垃圾收集中花費了太多時間,CMS收集器會丟擲OutOfMemoryError:如果超過98%的總時間用於垃圾收集,並且回收的堆少於2%,則丟擲一個OutOfMemoryError。此功能旨在防止應用程式長時間執行,同時由於堆太小而進展很少或沒有。如有必要,可以通過-XX:-UseGCOverheadLimit在命令列中新增選項來禁用此功能。
該策略與並行收集器中的策略相同,只是執行併發收集所花費的時間不計入98%的時間限制。換句話說,只有在應用程式停止時執行的收集才會計入過多的GC時間。此類收集通常是由於併發模式失敗或顯式收集請求(例如,呼叫System.gc)造成的。
- 浮動垃圾
與Java HotSpot VM中的所有其他收集器一樣,CMS收集器是一個跟蹤收集器,至少可以識別堆中的所有可訪問物件。在Richard Jones和Rafael D. Lins的出版物“ Garbage Collection:Algorithms for Automated Dynamic Memory”中,它是一個增量更新收集器。由於應用程式執行緒和垃圾收集器執行緒在major收集期間併發執行,因此垃圾收集器執行緒跟蹤的物件隨後可能在收集過程結束時變得不可訪問。這些尚未回收的無法到達的物件被稱為浮動垃圾。
浮動垃圾量取決於併發收集週期的持續時間以及被應用程式引用(reference)更新的頻率(也稱為突變)。此外,由於年輕代和老年代是獨立收集的,因此每世代都是另一方的root源。一個粗略的指導方針是,嘗試將老年代增加20%來儲存浮動垃圾。這些浮動垃圾會在下一次的收集週期期間收集。
- 停頓
CMS收集器在併發收集週期中停頓兩次應用程式。第一個停頓是將根中可直接訪問的物件(例如,來自應用程式執行緒棧和暫存器的物件引用,靜態物件等)以及堆中的其他位置(例如,年輕代)標記為活動物件。第一次停頓被稱為初始標記停頓。第二次停頓在併發跟蹤階段結束時,查詢併發跟蹤遺漏的物件。這些物件是因為在CMS收集器完成跟蹤之後,應用程式執行緒更新了物件的引用而致的。第二次停頓被稱為備註停頓。
- 併發階段
可達物件圖的併發跟蹤發生在初始標記停頓和備註停頓之間。在該併發跟蹤階段期間,一個或多個併發垃圾收集器執行緒可能正在使用本供應用程式使用的處理器資源。因此,即使應用程式執行緒未停頓,應用程式吞吐量也會相應下降。備註停頓後,併發掃描階段會收集標識為無法訪問的物件。收集週期完成後,CMS收集器將處於等待,幾乎不消耗任何計算資源,直到下一個major收集週期開始。
- 啟動併發收集週期
使用序列收集器時,只要老年代滿就會發生major收集,並且在收集完成之前時停止所有應用程式執行緒。相反,併發集合的開始必須定時,以便收集可以在老年代變滿之前完成; 否則,由於併發模式失敗,應用程式將會有更長的停頓。
有幾種方法可以啟動併發收集。
CMS收集器根據最近的歷史記錄,維護對老年代用盡之前剩餘時間的估計,以及併發收集週期所需的時間。使用這些動態估計,開始併發收集週期,目的是在老年代用盡之前完成收集週期。這些估計值是為了安全起見而記錄的,因為併發模式失敗可能非常昂貴。
如果老年代的佔用率超過初始佔用率(老年代的百分比),則也開始併發收集。此初始佔用閾值的預設值約為92%,但該值可能會隨發行版的不同而有所變化。可以使用命令列選項手動調整此值-XX:CMSInitiatingOccupancyFraction=,其中是老年大小的整數百分比(0到100)。
- 停頓計劃
年輕代收集和老年代收集的停頓獨立發生。它們不重疊,但可能快速連續發生,使得來自一個收集的停頓,緊接著來自另一個收集,可以看起來是單個較長的停頓。為避免這種情況,CMS收集器會嘗試大致在上一次和下一次年輕代停頓之間中途安排備註停頓。目前沒有對初始標記停頓進行此排程,因為它通常比備註停頓短得多。
- 增量模式
請注意,增量模式在Java SE 8中已棄用,可能會在將來的主要版本中刪除。
CMS收集器可以在以遞增方式完成併發階段的模式中使用。回想一下,在併發階段,垃圾收集器執行緒正在使用一個或多個處理器。增量模式旨在通過週期性地停止併發階段以使處理器返給應用程式,來減少長併發階段的影響。這種模式,在此稱為i-cms,將收集器併發完成的工作劃分為在年輕代收集之間的小塊時間。當需要CMS收集器提供的低停頓時間的應用程式,並具有少量處理器(例如,1或2)的計算機上執行時,此功能非常有用。
併發收集週期通常包括以下步驟:
• 停止所有應用程式執行緒,標識可從根訪問的物件集,然後恢復所有應用程式執行緒。
• 在應用程式執行緒執行時,使用一個或多個處理器同時跟蹤可訪問的物件圖。
• 使用一個處理器同時回溯自上一步中的跟蹤以來修改的物件圖的部分。
• 停止所有應用程式執行緒並回溯自上次檢查後可能已修改的根和物件圖的部分,然後恢復所有應用程式執行緒。
• 併發的,使用一個處理器將無法訪問的物件掃描到用於分配的空閒列表。
• 併發的,使用一個處理器調整堆大小,併為下一個收集週期準備資料結構。
通常,CMS收集器在整個併發跟蹤階段使用一個或多個處理器,而不會主動放棄它們。類似地,一個處理器用於整個併發掃描階段,同樣不放棄它。對於具有響應時間限制的應用程式而言,這種開銷可能會造成太多中斷,尤其是在只有一個或兩個處理器的系統上執行時。增量模式通過將併發階段分解為短暫的活動突發來解決此問題,這些活動計劃在minor停頓之間發生。
i-cms模式使用佔空比來控制CMS收集器在主動放棄處理器之前允許執行的工作量。該佔空比是年輕代收集之間的時間百分比。i-cms模式可以根據應用程式的行為自動計算佔空比(推薦的方法,稱為自動調步),或者可以在命令列上將佔空比設定為固定值。
- 命令列選項
表8-1“i-cms的命令列選項”列出了控制i-cms模式的命令列選項。“推薦選項”部分提供了一組初始選項。
表8-1 i-cms的命令列選項
| 選項 | 描述 | 預設值,Java SE 5和更早版本 | 預設值,Java SE 6和更高版本 |
|---|---|---|---|
| -XX:+CMSIncrementalMode | 啟用增量模式。請注意,還必須啟用CMS收集器(使用-XX:+UseConcMarkSweepGC)才能使此選項生效。 | disabled | disabled |
| -XX:+CMSIncrementalPacing | 啟用自動調步。根據JVM執行時收集的統計資訊自動調整增量模式佔空比。 | disabled | disabled |
| -XX:CMSIncrementalDutyCycle= | 允許CMS收集器執行的minor收集之間的時間百分比(0到100)。如果CMSIncrementalPacing啟用,那麼這只是初始值。 | 50 | 10 |
| -XX:CMSIncrementalDutyCycleMin= | CMSIncrementalPacing啟用時佔空比下限的百分比(0到100)。 10 0 | ||
| -XX:CMSIncrementalSafetyFactor= | 用於在計算佔空比時新增保守性的百分比(0到100) | 10 | 10 |
| -XX:CMSIncrementalOffset= | 增量模式佔空比在minor收集之間的時間段內向右移動的百分比(0到100)。 | 0 | 0 |
| -XX:CMSExpAvgFactor= | 在計算CMS集合統計資訊的指數平均值時,用於對當前樣本進行加權的百分比(0到100)。 | 25 | 25 |
- 推薦選項
要在Java SE 8中使用i-cms,請使用以下命令列選項:
-XX:+ UseConcMarkSweepGC -XX:+ CMSIncrementalMode \
-XX:+ PrintGCDetails -XX:+ PrintGCTimeStamps
前兩個選項分別啟用CMS收集器和i-cms。最後兩個選項不是必需的; 它們只是將有關垃圾收集的診斷資訊寫入標準輸出,以便可以看到垃圾收集行為並在以後進行分析。
對於Java SE 5及更早版本,Oracle建議將以下內容用作i-cms的初始命令列選項集:
-XX:+ UseConcMarkSweepGC -XX:+ CMSIncrementalMode \
-XX:+ PrintGCDetails -XX:+ PrintGCTimeStamps \
-XX:+ CMSIncrementalPacing -XX:CMSIncrementalDutyCycleMin = 0
-XX:CMSIncrementalDutyCycle = 10
儘管控制i-cms自動調步的三個選項的值成為JavaSE6中的預設值,但建議JavaSE8使用相同的值。
- 基本故障排除
i-cms自動調步功能使用在程式執行時收集的統計資訊來計算佔空比,以便在堆變滿之前完成併發收集。但是,過去的行為並不是未來行為的完美預測因素,並且估算可能並不總是足夠準確以防止堆變滿。如果出現太多完全收集,請嘗試表8-2“排除i-cms自動起搏功能故障”中的步驟,一次嘗試一個。
表8-2排除i-cms自動調步功能故障
| 步驟 | 選項 |
|---|---|
| 1.增加安全係數。 | -XX:CMSIncrementalSafetyFactor= |
| 2.增加最小佔空比。 | -XX:CMSIncrementalDutyCycleMin= |
| 3.禁用自動調步並使用固定的佔空比。 | -XX:-CMSIncrementalPacing -XX:CMSIncrementalDutyCycle= |
測量
例8-1“CMS收集器的輸出”是CMS收集器的輸出,帶有選項-verbose:gc和-XX:+PrintGCDetails,刪除了一些小細節。請注意,CMS收集器的輸出中散佈著minor收集的輸出。
通常,許多minor收集在併發收集週期中發生。CMS-initial-mark表示併發收集週期的開始,CMS-concurrent-mark表示併發標記階段的結束,CMS-concurrent-sweep表示併發掃描階段的結束。之前未討論的是由CMS-concurrent-preclean表示的預清潔階段。預清理代表可以同時完成的工作,以準備備註階段CMS-remark。CMS-concurrent-reset表示最後階段,併為下一個併發集合做準備。
示例8-1 CMS收集器的輸出
[GC [1 CMS-initial-mark:13991K(20288K)] 14103K(22400K),0.0023781 secs]
[GC [DefNew:2112K-> 64K(2112K),0.0837052秒] 16103K-> 15476K(22400K),0.0838519秒]
...
[GC [DefNew:2077K-> 63K(2112K),0.0126205 secs] 17552K-> 15855K(22400K),0.0127482 secs]
[CMS-併發標記:0.267 / 0.374秒]
[GC [DefNew:2111K-> 64K(2112K),0.0190851 secs] 17903K-> 16154K(22400K),0.0191903 secs]
[CMS-concurrent-preclean:0.044 / 0.064 secs]
[GC [1 CMS-remark:16090K(20288K)] 17242K(22400K),0.0210460 secs]
[GC [DefNew:2112K-> 63K(2112K),0.0716116秒] 18177K-> 17382K(22400K),0.0718204秒]
[GC [DefNew:2111K-> 63K(2112K),0.0830392 secs] 19363K-> 18757K(22400K),0.0832943 secs]
...
[GC [DefNew:2111K-> 0K(2112K),0.0035190 secs] 17527K-> 15479K(22400K),0.0036052 secs]
[CMS-concurrent-sweep:0.291 / 0.662秒]
[GC [DefNew:2048K-> 0K(2112K),0.0013347 secs] 17527K-> 15479K(27912K),0.0014231 secs]
[CMS-concurrent-reset:0.016 / 0.016秒]
[GC [DefNew:2048K-> 1K(2112K),0.0013936秒] 17527K-> 15479K(27912K),0.0014814秒
]
初始標記停頓通常相對於minor收集停頓時間較短。併發階段(併發標記,併發預掃描和併發掃描)通常持續時間明顯長於minor集合停頓,如例8-1“CMS收集器的輸出”所示。但請注意,在這些併發階段期間不會停頓應用程式。備註停頓的長度通常與minor收集相當。備註停頓受某些應用程式特徵的影響(例如,高速率的物件修改可以增加此停頓)以及自上次minor收集以來的時間(例如,年輕代中的更多物件可能會增加此停頓)。
9 Garbage-First垃圾收集器
Garbage-First(G1)垃圾收集器是伺服器式垃圾收集器,針對具有大記憶體的多處理器機器。它嘗試以高概率滿足垃圾收集(GC)停頓時間目標,同時實現高吞吐量。全堆操作(例如全域性標記)與應用程式執行緒同時執行。這可以防止與堆或實時資料大小成比例的中斷。
G1收集器通過多種技術實現了高效能和停頓時間目標。
堆被分割槽為一組大小相等的堆區域,每個堆區域都是連續的虛擬記憶體範圍。G1執行併發全域性標記階段以確定整個堆中物件的活躍度。在標記階段完成之後,G1知道哪些區域會基本上是空的。它首先收集這些區域,這通常會產生大量的自由空間。這就是為什麼這種垃圾收集方法稱為Garbage-First。顧名思義,G1將其收集和壓縮活動集中在充滿可回收物件(即垃圾)的區域。G1使用停頓預測模型來滿足使用者定義的停頓時間目標,並根據指定的停頓時間目標選擇要收集的區域數。
G1將物件從堆的一個或多個區域複製到堆上的單個區域,並且在此過程中壓縮並釋放記憶體。這種操作在多處理器上並行執行,以減少停頓時間並提高吞吐量。因此,隨著每次垃圾收集,G1不斷努力減少碎片。這超出了以前兩種方法的能力。CMS(Concurrent Mark Sweep)垃圾收集不進行壓縮。並行壓縮僅執行整堆壓縮,這會導致相當長的停頓時間。
值得注意的是,G1不是實時收集器。它以高概率但不是絕對確定性滿足設定的停頓時間目標。根據以前收集的資料,G1估計在目標時間內可以收集多少個區域。因此,收集器具有收集區域的成本的相當準確的模型,並且它使用該模型來確定在停留在停頓時間目標內時要收集哪些區域和多少區域。
G1的重點是為要求有限GC延遲,並具有大堆的應用程式使用者提供解決方案。這意味著堆大小約為6GB或更大,並且穩定且可預測的停頓時間低於0.5秒。
如果應用程式具有以下一個或多個特徵,那麼正在使用CMS或並行壓縮執行的應用程式將從切換到G1中受益。
• 超過50%的Java堆被活動資料佔用。
• 物件分配率或升級率差異很大。
• 該應用程式正在經歷不希望的長垃圾收集或壓縮停頓(超過0.5到1秒)。
G1計劃作為併發標記掃描收集器(CMS)的長期替代品。將G1與CMS進行比較揭示了G1將成為更好的解決方案。一個區別是G1是壓縮收集器,此外,G1提供比CMS收集器更可預測的垃圾收集停頓,並允許使用者指定所需的停頓目標。
與CMS一樣,G1專為需要較短GC停頓的應用而設計。
G1將堆分成固定大小的區域(灰色框),如圖9-1“堆分割槽G1”所示。
圖9-1 G1的堆分割槽
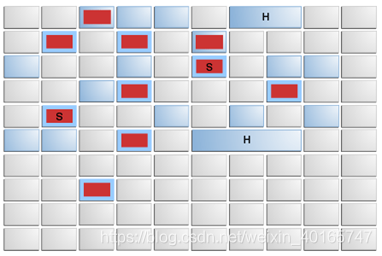
“圖9-1按G1分類堆”的描述
G1在邏輯意義上是世代的。一組空區域被指定為邏輯年輕代。在圖中,年輕一代是淺藍色的。
分配的邏輯是,當年輕代充滿時,這組地區被垃圾收集(一個年輕代收集)。在某些情況下,年輕區域之外的區域(深藍色的舊區域)可以同時進行垃圾收集。這被稱為混合收集。在該圖中,收集的區域用紅色框標記。該圖說明了一個混合收集,因為正在收集年輕地區和舊地區。垃圾收集是一個壓縮集合,它將活動物件複製到選定的最初為空的區域。基於倖存物體的年齡,可以將物體複製到倖存者區域(標記為“S”)或舊區域(未具體示出)。標有“H”的區域包含大於半個區域且經過特殊處理的巨大物體; 請參見
Garbage-First垃圾收集器中的Humongous物件和Humongous分配。
- 分配(撤離)失敗
與CMS一樣,G1收集器在應用程式繼續執行時執行其收集的一部分,並且存在一個風險,即應用程式分配物件的速度快於垃圾收集器可以恢復可用空間。與併發標記掃描(CMS)收集器的併發模式失敗類似。在G1中,G1正在將活動資料從一個區域(撤離)複製到另一個區域時發生失敗(Java堆耗盡)。複製以壓縮活動資料。如果在收集垃圾期間無法找到空閒區域,則會發生分配失敗(因為沒有空間來分配來自撤離區域的活動物件),這時會stop-the-world( STW)進行全收集。
- 浮動垃圾
物件可能在G1收集期間死亡而不被收集。G1使用一種名為snapshot-at-the-beginning(SATB)的技術來保證垃圾收集器找到所有活動物件。SATB宣告在併發標記開始時存在的任何物件(整個堆上的標記)被認為是用於收集目的的活動物件。SATB允許浮動垃圾的方式類似於CMS增量更新。
- 停頓
G1停頓應用程式以將活動物件複製到新區域。這些停頓可以是隻收集年輕區域的年輕收集停頓,也可以是年輕人和舊區域被撤離的混合收集停頓。與CMS一樣,在應用程式停止時,有一個最終標記或備註停頓以完成標記。雖然CMS也有初始標記停頓,但G1會將初始標記工作作為撤離停頓的一部分。G1在收集的末尾有一個清理階段,部分是STW,部分是併發的。清理階段的STW部分識別空區域並確定作為下一個集合的候選的舊區域。
- 卡表和併發階段
如果垃圾收集器不收集整個堆(增量集合),則垃圾收集器需要知道從堆的未收集部分到正在收集的堆的部分中的指標。這通常用於分代垃圾收集器,其中堆的未收集部分通常是老年代,並且堆的收集部分是年輕代。用於儲存此資訊的資料結構(老年代指標指向年輕代物件)是一個記憶集。卡表是一個特定型別的記憶集。Java HotSpot VM使用位元組陣列作為卡表。每個位元組稱為一個卡。卡對應於堆中的一系列地址。Dirtying一個卡意味著將位元組值更改為髒值,髒值可能包含一個新指標,該指標是卡所包含的從老年代到年輕代的地址範圍。
處理一個卡意味著檢視卡,以檢視是否存在舊代到年輕代指標並且可能對該資訊做某事,例如將其轉移到另一資料結構。
G1具有併發標記階段,標記從應用程式中找到的活動物件。併發標記從撤離停頓(初始標記工作完成)結束延伸到備註。併發清理階段將收集清空的區域新增到空閒區域列表中,並清除這些區域的記憶集。此外,根據需要執行併發清洗執行緒處理已被應用程式寫入弄髒並且可能具有跨區域引用的卡表條目。
- 啟動併發收集週期
如前所述,年輕和老年區域會被混合收集。為了收集老年區域,G1對堆中的活動物件進行了完整標記。這種標記是通過並行標記階段完成的。當整個Java堆的佔用率達到引數值InitiatingHeapOccupancyPercent時,將啟動併發標記階段。使用命令列選項設定此引數