
MapReduce實現訂單商品的統計
阿新 • • 發佈:2018-11-19
mapreduce功能強大,可以處理大量離線資料。業務場景是要統計每個訂單中數量情況,並將對應的商品id抽取出來。
資料格式為.csv檔案,型別如下所示:
order_id,product_id,add_to_cart_order,reordered 1,49302,1,1 1,11109,2,1 1,10246,3,0 1,49683,4,0 1,43633,5,1 1,13176,6,0 1,47209,7,0 1,22035,8,1 36,39612,1,0 36,19660,2,1 36,49235,3,0 36,43086,4,1 36,46620,5,1 36,34497,6,1 36,48679,7,1 36,46979,8,1 38,11913,1,0 38,18159,2,0 38,4461,3,0 38,21616,4,1 38,23622,5,0 38,32433,6,0 38,28842,7,0 38,42625,8,0 38,39693,9,0
生成的結果格式
1 49302_11109_10246_49683_43633_13176_47209_22035 8
36 39612_19660_49235_43086_46620_34497_48679_46979 8
38 11913_18159_4461_21616_23622_32433_28842_42625_39693 9sed 1d order_products.csv > order_produc.csvmap函式:對資料進行轉換
import sys for line in sys.stdin: id_list = line.strip().split(',') if len(id_list) != 4: continue order_id, product_id = id_list[0], id_list[1] print '%s\t%s\t%d'%(order_id, product_id, 1)
reduce函式:對資料歸併
import sys cur_order_id = None cur_product_id = '' sum_cnt = 0 for line in sys.stdin: order_id, product_id, count = line.strip().split('\t') if cur_order_id == None: cur_order_id = order_id if cur_order_id != order_id: print '%s\t%s\t%d'%(cur_order_id, cur_product_id, sum_cnt) cur_order_id = order_id sum_cnt = 0 cur_product_id = '' sum_cnt += int(count) if cur_product_id == '': cur_product_id = product_id #判斷條件,若product_id只有一個,避免出現_product_id的情況 else: cur_product_id = cur_product_id + '_' + product_id print '%s\t%s\t%d'%(cur_order_id, cur_product_id, sum_cnt)
本地除錯程式碼
cat order_produc.csv |python map.py | sort -k1 | python red.py 跑完之後的部分結果
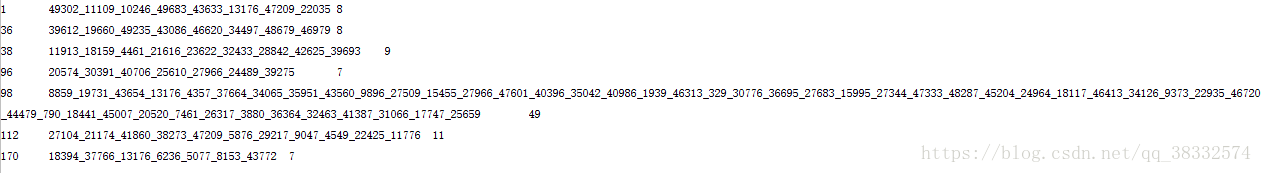
思考與拓展:
(1)上述資料可以作為跑模型的訓練資料。
(2)針對這些資料可以計算商品的相似度。
(3)若有的訂單數量很多,可以將對應的使用者關聯出來,做成user_id,product_id的形式。
(4)對訂單求最大值、最小值、平均值,可以描述出使用者的消費水平。
(5)可以通過訂單數量對資料進行篩選,如有的數量為1,沒有什麼實際意義,可以將這些記錄刪除。