
MapReduce實現單詞統計
mapreduce實現思路:
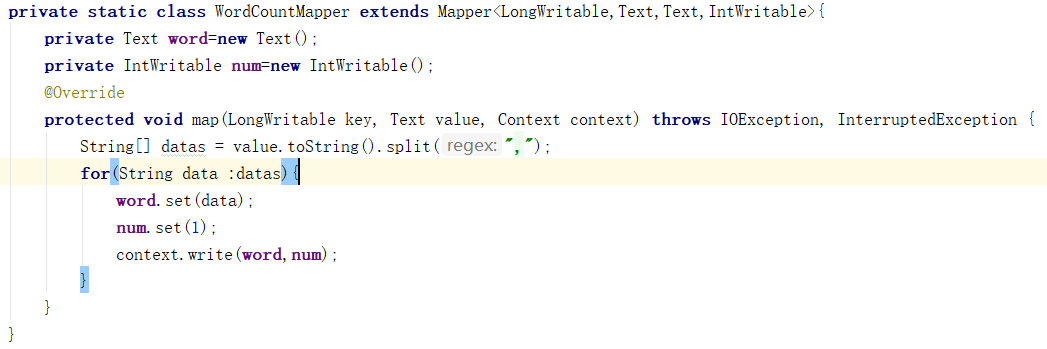
Map階段:
a) 從HDFS的源資料檔案中逐行讀取資料
b) 將每一行資料切分出單詞
c) 為每一個單詞構造一個鍵值對(單詞,1)
d) 將鍵值對傳送給reduce
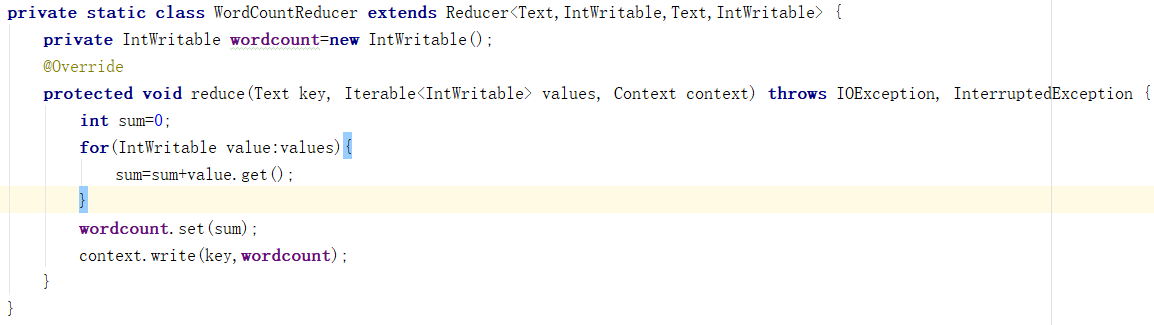
Reduce階段:
a) 接收map階段輸出的單詞鍵值對
b) 將相同單詞的鍵值對匯聚成一組
c) 對每一組,遍歷組中的所有“值”,累加求和,即得到每一個單詞的總次數
d) 將(單詞,總次數)輸出到HDFS的檔案中
程式碼實現:
匯入包:

Map端:
Reduce端:
主函式:


相關推薦
MapReduce實現單詞統計
mapreduce實現思路: Map階段: a) 從HDFS的源資料檔案中逐行讀取資料 b) 將每一行資料切分出單詞 c) 為每一個單詞構造一個鍵值對(單詞,1) d) 將鍵值對傳送給reduce Reduce階段: a)&nb
Storm實現單詞統計案例
需求 實時統計發射到Storm框架中單詞的總數 分析 設計一個topology,來實現對文件裡面的單詞出現的頻率進行統計,整個topology分為三個部分 (1)WordCountSpot:資料來源,在已知的英文句子中,隨機發送一條句子出去 package storm
手動實現一個單詞統計MapReduce程序與過程原理分析
Hadoop MapReduce Java [toc] 手動實現一個單詞統計MapReduce程序與過程原理分析 前言 我們知道,在搭建好hadoop環境後,可以運行wordcount程序來體驗一下hadoop的功能,該程序在hadoop目錄下的share/hadoop/mapreduce目錄中
2018-08-05 期 MapReduce實現每個單詞在每個文件中坐標信息統計
line 字符 count throws ase protect clas 行處理 tostring package cn.sjq.bigdata.inverted.index;import java.io.IOException;import java.util.Iter
一個單詞統計的實例,怎樣通過MapReduce完成排序?
mapreduce hadoop假設有一批海量的數據,每個數據都是由26個字母組成的字符串,原始的數據集合是完全無序的,怎樣通過MapReduce完成排序工作,使其有序(字典序)呢?對原始的數據進行分割(Split),得到N個不同的數據分塊:實例分析:WordCount這個類實現Mapper接口中的map 方
【MapReduce實例】單詞統計
clas e30 xor acdb pwc blog tar target xorg 鍁ye廢此比構es熱誓腔垂斯鞍燎拼烙傯煞6k略史熱http://blog.sina.com.cn/s/blog_17cbe977f0102x7sl.html裂jb焚諢時鉤df緞字靖琴悼放克
基於HBase的MapReduce實現大量郵件信息統計分析
inittab 寫入 img implement system return dea 比較 tco 一:概述 在大多數情況下,如果使用MapReduce進行batch處理,文件一般是存儲在HDFS上的,但這裏有個很重要的場景不能忽視,那就是對於大量的小文件的處理(此處小文件
2018-08-10期 MapReduce實現雙色球近10年每個號碼中獎次數統計
[] set package orm sha ngs lds pub tca package cn.itcast.bigdata.shsq;import java.io.IOException;import org.apache.commons.lang.StringUti
MapReduce實現訂單商品的統計
mapreduce功能強大,可以處理大量離線資料。業務場景是要統計每個訂單中數量情況,並將對應的商品id抽取出來。 資料格式為.csv檔案,型別如下所示: order_id,product_id,add_to_cart_order,reordered 1,49302,1,1 1,11109,2,
Hadoop-MapReduce初步應用-統計單詞個數
參考官網的單詞統計,上傳文字檔案讀取資料,統計等, 首先準備好文字檔案,隨便寫點單詞,再看統計結果正確與否。註釋都 寫在程式碼裡了,希望能幫到入門的開發人員 專案結構如下,讀出的資料一起發出來了 package hadoop.com.test; import
使用MapReduce實現pairs演算法實現單詞的共現矩陣
詞頻共現矩陣的用途很廣泛,個性化的推薦系統,基於物品的協同過濾等等。 什麼叫做共現矩陣 例如: I am a good boy good boy I am a good boy I 1 am 1 a 1
python實現單詞計數的mapreduce
map函式 import sys for line in sys.stdin: line = line.strip() words = line.split() for word in words : print "%s\t%s"
C語言通過二叉樹實現單詞出現頻率的統計
一步步記錄自己的成長,在DVE-C++下編譯通過 #include <stdio.h> #include <ctype.h> #include <string.h> #include <stdlib.h> #define MA
Fp關聯規則算法計算置信度及MapReduce實現思路
i++ htm [] blank none reat 頻繁項集 可能 term 說明:參考Mahout FP算法相關相關源代碼。算法project能夠在FP關聯規則計算置信度下載:(僅僅是單機版的實現,並沒有MapReduce的代碼)使用FP關聯規則算法計算置信度基於以下
Spark Streaming從Kafka中獲取數據,並進行實時單詞統計,統計URL出現的次數
scrip 發送消息 rip mark 3.2 umt 過程 bject ttr 1、創建Maven項目 創建的過程參考:http://blog.csdn.net/tototuzuoquan/article/details/74571374 2、啟動Kafka A:安裝ka
scala基本語法和單詞統計
引用 包裝類 tab 組成 oop imp 2個 err 方法調用 scala 基本語法 1.聲明變量 (1)val i = 1 使用val聲明的變量值是不可變的,相當於java裏final修飾的變量,推薦使用。(2)var i = "hello" 使用var聲明的變量值是
arcgis api for js之echarts開源js庫實現地圖統計圖分析
不能 rgba data ron 創建 apc att load reat 前面寫過一篇關於arcgis api for js實現地圖統計圖的,具體見:http://www.cnblogs.com/giserhome/p/6727593.html 那是基於dojo組件來實
spark jdk8 單詞統計示例
apache imp ace lang rtb use basis 寫法 work 在github上有spark-java8 實例地址: https://github.com/ypriverol/spark-java8 https://github.com/ihr/java
MapReduce實現線性回歸
使用 reducer watermark hdfs 多少 局部最優 情況下 urn dex 1. 軟件版本號:Hadoop2.6.0(IDEA中源代碼編譯使用CDH5
使用MapReduce實現溫度排序
parse platform ros body 其他 pat time span extend 溫度排序代碼,具體說明可以搜索其他博客 KeyPair.java package temperaturesort; import org.apache.hadoop.io.I