
Hadoop到底是什麼(對一些現有文件進行整合)
大資料是個鋪天蓋地的詞,而談論大資料又不可避免地要提到Hadoop,Hadoop到底是什麼玩意,以及有何功用。
Hadoop是Apache軟體基金會管理的開源軟體平臺,但Hadoop到底是什麼呢?簡單來說,Hadoop是在分散式伺服器叢集上儲存海量資料並執行分散式分析應用的一種方法。Hadoop被設計成一種非常“魯棒”的系統,即使某臺伺服器甚至叢集宕機了,執行其上的大資料分析應用也不會中斷。此外Hadoop的效率也很高,因為它並不需要你在網路間來回搗騰資料。
以下是Apache的正式定義:
Apache Hadoop軟體庫是一個框架,允許在叢集伺服器上使用簡單的程式設計模型對大資料集進行分散式處理。Hadoop被設計成能夠從單臺伺服器擴充套件到數以千計的伺服器,每臺伺服器都有本地的計算和儲存資源。Hadoop的高可用性並不依賴硬體,其程式碼庫自身就能在應用層偵測並處理硬體故障,因此能基於伺服器叢集提供高可用性的服務。
如果更深入地分析,我們發現Hadoop還有更加精彩的特性。首先,Hadoop幾乎完全是模組化的,這意味著你們能用其他軟體工具抽換掉Hadoop的模組。這使得Hadoop的架構異常靈活,同時又不犧牲其可靠性和高效率。
Hadoop的產生
隨著我們網路的發達,科技的發達,我們網路上產生的資料越來越多,越來越大,那麼大到什麼地步,有10000G那麼大嗎?告訴你比那個大多了!那有1000T那麼大嗎?比那個也大多了,已經是單一的伺服器解決不了的,那麼我們不是可以多用幾臺伺服器就解決了?一臺一臺伺服器分別寫入和讀取資料是很麻煩的。
接著分散式檔案系統就應運而生了,它可以管轄很多伺服器用來儲存資料,通過這個檔案系統儲存資料時,我們就感覺在操作一臺伺服器一樣。分散式檔案系統管理的是一個伺服器叢集。在這個叢集中,資料儲存在叢集的節點(即叢集中的伺服器)中,但是該檔案系統把伺服器的差異給遮蔽了,我們的資料分佈在不同的伺服器中,分佈在不同節點上的資料可能是屬於同一個檔案,為了組織眾多的檔案,把檔案放到不同的資料夾中,資料夾可以一級一級的包含。這種組織形式稱為名稱空間(namespace)。名稱空間管理著叢集中的所有檔案。名稱空間的職責和正真儲存真實資料的職責是不一樣的。負責名稱空間職責的節點稱為主節點(master node),負責儲存真實資料的職責的單稱為從節點(slave node)。主節點負責管理檔案系統的檔案結構,從節點負責儲存真實的資料,我們把這樣的結構稱為主從式結構(master-slave)。使用者操作時也應該先和主節點打交道,查詢資料在哪些從節點上儲存,然後才從從節點儲存,然後再從從節點讀取。在主節點中,為了加快使用者的訪問速度,會把整個名稱空間資訊都放在記憶體中,當儲存的檔案越多時,那麼主節點就需要越多的記憶體空間。在從節點儲存資料時,有的原始資料可能很大,有的可能很小,如果大小不一樣的檔案不容易管理,那麼抽象出一個獨立的儲存檔案單位,稱為:塊(block)。然後資料存放在叢集中,可能網路原因或者伺服器硬體原因造成訪問失敗,所以又才用了副本機制(replication),把資料同時備份到多臺伺服器中,這樣資料就更安全了。
Hadoop如何進行資料處理
對資料進行處理時,我們會把資料讀取到記憶體中進行處理。如果我們對海量資料讀取到記憶體中進行處理,比如資料大小是100T,我們要統計檔案中一共有多少個單詞。要想到檔案載入到記憶體中幾乎是不可能的,要想把資料載入到記憶體中幾乎也是不可能的。隨著技術發展,即使伺服器有100T記憶體,這樣的伺服器也很昂貴,即使資料能夠載入到內容,那麼載入100T也是需要很長時間的。那麼這就是我們遇到的問題,那麼我們怎麼處理呢?是否可以把程式程式碼放到存放資料的伺服器上呢?(移動計算)因為程式程式碼相對於原始資料來說很小,幾乎是可以忽略不計的,所以省下了原始資料的傳輸的時間。現在資料是存放在分散式的檔案系統中,100T的資料可能存放在很多伺服器上,那麼就可以把程式碼分發到這些伺服器上,在這些伺服器上同時進行,也就是平行計算,這樣就大大縮短了程式執行的時間。分散式計算需要的是最終的結果,程式程式碼在很多伺服器上執行後會產生很多的結果,因此需要一段程式碼對這些中間結果進行彙總。Hadoop中的分散式計算一般分為兩個階段完成的,第一階段負責讀取各資料節點中的原始資料,進行初步處理,對各個節點的資料求單詞書。然後把處理結果傳輸到第二階段,對中間結果進行彙總,產生最終的結果。
在分散式計算中,程式程式碼應該允許放在哪些資料節點上,哪些節點執行第一階段的程式碼,哪些節點執行第二階段的程式碼;第一階段程式碼執行完畢後,傳輸到第二階段程式碼所在節點;如果中間執行失敗了,怎麼辦?等等問題,都需要管理。執行這些管理職責程式碼的節點稱為主節點(master node),執行第一二階段程式程式碼的節點稱為從節點(slave node)。使用者的程式碼應該提交給主節點,由主節點負責把程式碼分配到不同的節點執行。
Hadoop分散式檔案系統(HDFS)
如果提起Hadoop你的大腦一片空白,那麼請牢記住這一點:Hadoop有兩個主要部分:一個數據處理框架和一個分散式資料儲存檔案系統(HDFS)。
HDFS就像Hadoop系統的籃子,你把資料整整齊齊碼放在裡面等待資料分析大廚出手變成性感的大餐端到CEO的桌面上。當然,你可以在Hadoop進行資料分析,也可以見gHadoop中的資料“抽取轉換載入”到其他的工具中進行分析。
在hadoop中,分散式儲存系統統稱為HDFS(hadoop distributed file system)。其中,主節點為名位元組點(namenode),namenode就是master,namenode一是管理檔案系統檔案的元資料資訊(包括檔名稱、大小、位置、屬性、建立時間、修改時間等等),二是維護檔案到塊的對應關係和塊到節點的對應關係,三是維護使用者對檔案的操作資訊(檔案的增刪改查);從節點稱為資料節點(datanode),datanode就是slave,datanode主要是儲存資料的。master只有一個,slave可以有多個,這就是master/slave模式
資料處理框架和MapReduce
顧名思義,資料處理框架是處理資料的工具。具體來說Hadoop的資料處理框架是基於Java的系統——MapReduce,你聽到MapReduce的次數會比HDFS還要多,這是因為:
1.MapReduce是真正完成資料處理任務的工具
2.MapReduce往往會把它的使用者逼瘋
在常規意義上的關係型資料庫中,資料通過SQL(結構化查詢語言)被找到並分析,非關係型資料庫也使用查詢語句,只是不侷限於SQL而已,於是有了一個新名詞NoSQL。
有一點容易搞混的是,Hadoop並不是一個真正意義上的資料庫:它能儲存和抽取資料,但並沒有查詢語言介入。Hadoop更多是一個數據倉庫系統,所以需要MapReduce這樣的系統來進行真正的資料處理。
MapRduce執行一系列任務,其中每項任務都是單獨的Java應用,能夠訪問資料並抽取有用資訊。使用MapReduce而不是查詢語言讓Hadoop資料分析的功能更加強大和靈活,但同時也導致技術複雜性大幅增加。
目前有很多工具能夠讓Hadoop更容易使用,例如Hive,可以將查詢語句轉換成MapReduce任務。但是MapReduce的複雜性和侷限性(單任務批處理)使得Hadoop在更多情況下都被作為資料倉庫使用而非資料分析工具。
Hadoop的另外一個獨特之處是:所有的功能都是分散式的,而不是傳統資料庫的集中式系統。
在hadoop中,分散式計算部分稱為Mapreduce。其中,主節點稱為作業節點(jobtracker),jobtracker就是master,jobtracker和namenode必須在同一臺伺服器上;從節點稱為從節點(tasktracker),tasktracker就是slave,tasktracker必須執行在datanode上。master只有一個,slave可以有多個,這就是master/slave模式。在任務節點中,執行第一段的程式碼稱為map任務,執行第二段程式碼稱為reduce任務。
窮人的ETL
實際上大多數採用Hadoop的公司都沒有將Hadoop用於大資料分析,而是把Hadoop作為一種廉價的海量儲存和ETL(抽取、轉換、載入)系統。
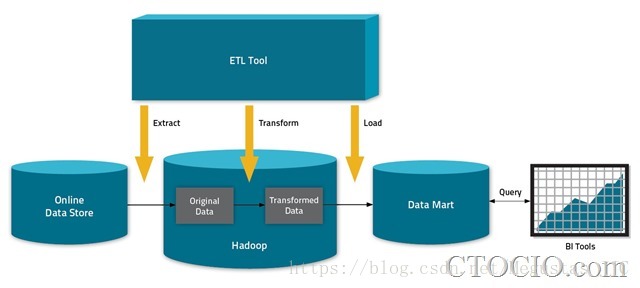
雖然被打上了“大資料分析工具”的標籤,但在大多數企業眼裡,Hadoop是“窮人的ETL”。目前確實有個別企業將Hadoop用於執行激動人心的分析工作,但這只是個案。Cloudera曾提出Hadoop的三大應用模式:Transform、Active Archive和Exploration,但是業內人士分析,目前至少有75%的部署Hadoop的企業還都只是停留在前兩個模式中:將Hadoop作為廉價的ETL方案,或者用作垃圾資料填埋場(儲存大量價值很低的資料)
企業採用Hadoop需要經歷三個發展階段,從一開始用來儲存海量資料,到對資料進行處理和轉換,到最終開始分析這些資料。