
Python學習筆記整理Module1
-
程式語言介紹
- Python介紹
- Python安裝
- 第一個Python程式
- 變數
- 程式互動
- 格式化輸出
- 資料運算
- 資料型別
- 控制流程
- 進位制與字元編碼
程式語言介紹
程式語言的定義及作用:
程式設計的定義:‘動詞’即寫程式碼。
程式設計的作用:讓計算機以人類的思維執行某些事件。
程式語言的分類:
- 機器語言
- 組合語言
- 高階語言
機器語言與組合語言屬於低階語言.
機器語言:由於計算機只能識別二進位制碼,因此用二進位制碼0和1描述的指令為機器指令。全部由機器指令集合構成的語言稱之為機器語言。
- 優點:執行速度快
- 缺點:直觀性差,學習困難
組合語言:組合語言的實質性是與機器語言相同的都是對計算機硬體進行操作。不同的是指令採用英文縮寫的形式更方便記憶和識別。
高階語言:高階語言相比組合語言,不但將許多相關的機器指令合成為單條指令,比並且去掉了許多與操作有關與完成工作無關的繁瑣細節。例如堆疊,暫存器等。這樣就大大的簡化了程式中的機器指令,由於忽略了很多細節,so 學習起來更加方便,程式設計者也不需要太多的相關知識。
高階語言的分類:
- 編譯型
- 解釋型
編譯型:在程式執行前。把源程式翻譯成機器碼。因此其目標程式可以脫離其語言環境獨立執行。程式一旦修改,就必須修改原始檔程式編譯。
- 優點:執行速度快,可脫離環境單獨執行
- 缺點:可移植性(跨平臺)差,修改比較繁瑣
解釋型:目標程式由直譯器翻譯成機器語言才能執行,因此執行速度慢,且不可脫離環境單獨執行,由於不需要提前翻譯成機器語言,使用修改想比編譯型的語言方便許多
- 優點:可移植性強,修改方便
- 缺點:執行速度慢,需要語言環境才能執行
Python介紹
Python介紹:
創始人:吉多 範羅蘇姆(Guido van Rossum)
1989年聖誕節期間,Guido開始寫Python語言編譯器.他的初衷是創造一種c和shell之間簡單易學,功能全面可擴充套件的語言
Python的發展史:
1994年:Python1.0
2000年:Python2.0
2004年:Python2.4同時Django誕生
2006年:Python2.5
2008年:Python2.6
2008年:Python3.0
2009年:Python3.1
2010年:Python2.7(過渡版本支援到2020年)同時支援2.x和3.x的特性
2011年:Python3.2
2012年:Python3.3
2014年:Python3.4
2015年:Python3.5
Python直譯器:
- CPython:
這個直譯器是c語言開發的,所以叫cpython.在命令列下執行python就是啟動cpython直譯器
- IPython:
Ipython是基於cpython之上的一個互動式直譯器,也是就說,ipython只是在互動上有所增強,但只是程式碼是和cpytho完全一樣的。
- Pypy:
pypy是另一個python直譯器,它的目標是執行速度。pypy採用JIT技術,對python程式碼進行動態編譯,所以可以顯著提高python程式碼執行速度.
- Jython:
Jython是執行在Java平臺上的python直譯器,可以直接把python程式碼編譯成Java位元組碼執行.
- IronPython:
IronPython和Jython類似,只不過ironpython是執行在微軟.net平臺上的python直譯器,可以直接把python程式碼編譯成.net位元組碼
Python安裝:
下載地址:https://www.python.org/downloads/windows/
Windows:
預設下一步
驗證是否安裝成功:win+r 輸入cmd 出現以下字元即表明安裝成功
C:\Users\67525>python Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>>
錯誤提示:不是內部命令
解決辦法:配置path環境
計算機(此電腦)鼠表右鍵 --> 屬性 --> 高階系統設定 -->高階 (環境變數) --> 在path中新增 Python的安裝路徑
Linux or Mac:
一般自帶Python2.7 or Python2.6,需要可其他版本自行安裝。
安裝其他版本已python3.6為例:
需要先下載python3.6.的原始碼包
# tar -zxvf Python-3.6.1.tgz # cd Python-3.6.1 # ./configure # make && make instal
檢查是否安裝成功:
# python3 -V Python 3.6.1
第一個Pthon程式
1.新建檔案Hello.py 編輯以下內容:O
1 print('Hello World!')
在cmd下輸入 Python Hello.py
2.在Python互動器下
D:\>python Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> print('hello world') hello world >>>
變數:
變數的作用:就是把程式運算的中間結果存放到記憶體裡,以便後面的程式碼繼續呼叫
變數名的定義規則:
- 變數名是字母下劃線及數字的任意組和
- 變數名的首位字元不可為數字
- 以下關鍵字不可以用作變數名
定義變數名要避免的幾種方式:
- 變數名為中文或拼音
- 變數名過長
- 變數名詞不達意
變數的賦值
1 number = 5 2 name = 'xuange'
變數的命名習慣
#駝峰體 AgeOfOldBoy = 56 NumberOfStudents = 80 #下劃線 age_of_oldboy = 56 number_of_studnets = 80
常量
常量:即不可變得量,在Python中並沒有特定的語法來宣告常量,只需把常量名全部使用大寫即可.
常量的定義:
PI = 3.1415826
print(PI)
使用者互動及註釋
作用:接收使用者輸入的值,預設型別為字串
語法:
#語法 name = input('name:')
特定條件下需要接收密碼可用模組中的getpass模組
import getpass passwd = getpass.getpass('passwd:')
註釋
#這是單行註釋 ''' 這是多行註釋 '''
註釋原則:只需要在不容易理解的地方加入註釋即可,不需要全部都加註釋。可以使用中文或者英文,禁止使用拼音
格式化輸出
作用:按照指定格式列印內容。
佔位符:
- %s 字串型別
- %d 數字型別
- %f 浮點數型別
常見的三種字串格式方式:
1 ##常見的幾種方法 2 name = input('Name:') 3 age = input('Age:') 4 job = input('Jbo:') 5 salary = input('Salary:') 6 #方法一 7 info = ''' 8 -------info %s ------- 9 Name: %s 10 Age: %s 11 Job: %s 12 Salary: %s 13 ------ the end --------- 14 ''' % (name, name, age, job, salary) 15 print(info) 16 # 方法二 17 info = ''' 18 ----- info {_name} 19 Name: {_name} 20 Age: {_age} 21 Job: {_job} 22 Salay: {_salary} 23 '''.format(_name=name, _age=age, _job=job, _salary=salary) 24 print(info) 25 #方法三 26 info = ''' 27 ------info {0} ---- 28 Name :{0} 29 Age:{1} 30 Job:{2} 31 Salary: {3} 32 ''' .format(name, age, job, salary) 33 print(info) 34 #一種縮寫 35 b = 'bbb' 36 print(f'aaaa{b}')
資料運算
- 算數運算子
- 比較運算子
- 賦值運算子
- 邏輯運算子
- 成員運算
- 身份運算
- 位運算
算數運算子
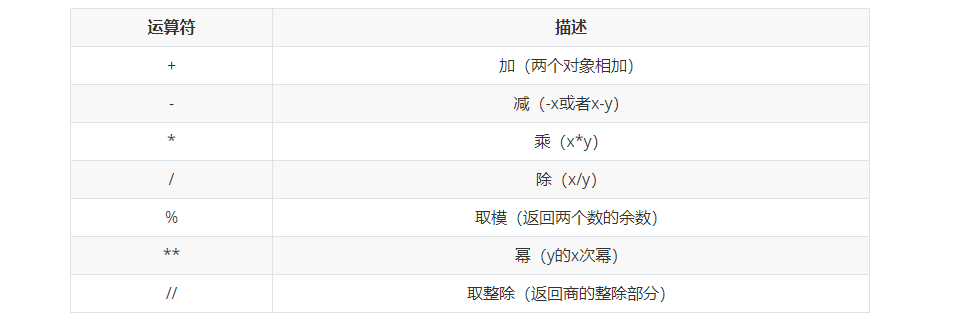
1 #例子: 2 >>> a = 10 3 >>> b = 5 4 >>> c = a+b 5 >>> c 6 15 7 >>> c = a-b 8 >>> c 9 5 10 >>> c = a*b 11 >>> c 12 50 13 >>> c = a/b 14 >>> c 15 2.0 16 >>> c = a % b 17 >>> c 18 0 19 >>> c = a ** b 20 >>> c 21 100000 22 >>> c = a //b 23 >>> c 24 2
比較運算:
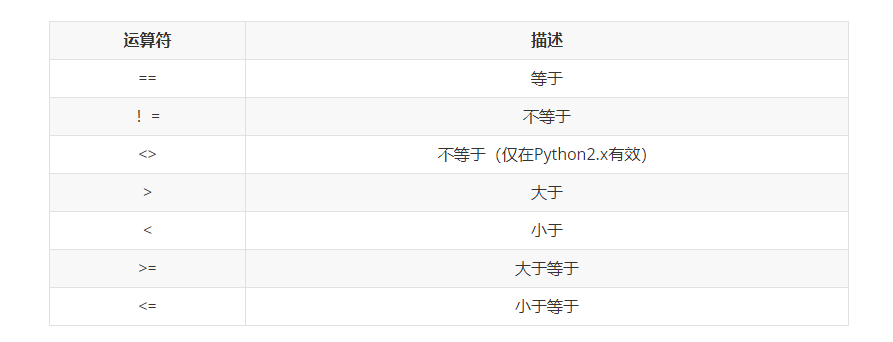
#例子: >>> a = 5 >>> b = 3 >>> a == b False >>> a !=b True >>> a > b True >>> a < b False >>> a >= b True >>> a <= b False >>>
賦值運算

#
例子:
>>> a = 5
>>> b = 3
>>> b += a #b = b+a
>>> b
8
>>> b -= a #b= b-a
>>> b
3
>>> b *= a #b = b*a
>>> b
15
>>> b /= a #b = b/a
>>> b
3.0
>>> b %= a #b = b%a
>>> b
3.0
>>> b **= a #b = b**a
>>> b
243.0
>>> b //= a #b = b//a
>>> b
48.0
>>>
邏輯運算

例子 >>> a = 15 >>> b = 20 >>> a == 15 and b ==20 #所有條件都滿足才會為true True >>> a < 20 and b >20 False >>> a < 20 or b > 20 # 一個條件成立就為true True >>> not a< 20 #取反 False
成員運算

#例子: >>> list = [1,2,3,5,6,7] >>> 1 in list True >>> 4 in list False >>> 1 not in list False >>> 4 not in list True >>>
身份運算

#例子: #如果id(a)等於id(b) 則返回True ,反之返回 False >>> a = 5 >>> b = a >>> a is b True # 如果 id(a)不等於id(b)則返回True, 反之返回False >>> a = 7 >>> a is not b True >>>
位運算:
暫時沒搞明白,先不寫~~~
資料型別
- 基礎資料型別
- 資料集
基礎資料型別
數字
- 整數
- 浮點數
- 複數
整數
整型: 在32位機器上取值範圍為 -2* *31 ~ 2 * *31-1 ,64位機器上取值範圍為:-2 ** 63 ~ 2 * *63-1
長整型:在Python3中沒有整型和長整型之分
浮點數
浮點數:浮點數是屬於有理數中特定子集的數字表示,在計算機中用以表示任意某個實數。
科學計演算法:
就是把一個數字以a*10n次冪的方式表現出來。計算機一般把10的幾次冪用中的10以e或者E來表示.且a>=1,a<10
浮點數的精度問題:
由於在計算機內部整數和浮點數的記憶體儲存方式不同,整數運算永遠是精確的,而浮點數運算則會有四捨五入的誤差。
Python預設的是17位精度,也就是小數點後16位,但這個精度越往後越不準.
計算高精度的浮點數方法:
from decimal import * getcontext() getcontext().prec = 20 a = Decimal(1)/Decimal(3) print(a)
也可以使用字串格式化的方式來表示:
>>> a =('%.30f'%(1.0/3)) >>> a '0.333333333333333314829616256247' >>>
複數
複數是指能寫成如下形式的數a+bi,a和b為實數i是虛數。在複數a+bi中,a為複數的實部,b為複數的虛部,i為虛數的單位,當虛部等於0時,這個複數就是實數,當虛部不等0時,這個數就是虛數
#例子 >>> a = (-5+4j) >>> a (-5+4j) >>> type(a) <class 'complex'> >>>
其中-5,4為實數,j為虛數.
字串
字串特性及定義:有序不可修改的字元集合,由一對單,雙,三引號包含 包含的內容即字串
字串作用:用於儲存文字資訊
字串的操作方法:
1 s = 'hello world' 2 3 s.capitalize() #返回首字母為大寫的字串 4 s.casefold() 5 s.center() #以該字串為中心填充該字串 引數:長度 ,以什麼字元填充(預設空格) 6 s.count() #檢視該字串某個字元出現的次數 引數:檢視的字元,起始,結束(預設為空) 7 s.encode() #以指定編碼格式編碼字串 引數:編碼(預設UTF-8),設定不同錯誤的處理方案。預設為 'strict',意為編碼錯誤引起一個UnicodeError. 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通過 codecs.register_error() 註冊的任何值。 8 s.endswith() #檢查字串是否以 obj 結束. 引數:該引數可以是一個元素或是字串,起始位置,結束位置 9 s.expandtabs() #擴充套件tab建 引數:tab鍵長度(預設:8個空格) 10 s.find() #堅持字串中是否包含子字串str 引數:檢索的字串,起始位置,結束位置 11 s.format() #字串格式化 引數: 12 s.index() #檢測字串是否包含子字串str 引數:檢索的字串。起始位置,結束位置 13 s.isalnum() #如果字串至少有一個字元並且所有字元都是字母或數字則返 回 True,否則返回 False 14 s.isalpha() #如果字串至少有一個字元並且所有字元都是字母則返回 True, 否則返回 False 15 s.isdecimal() #如果字串中只有十進位制字元,返回True,否則返回False 16 s.isdigit() #如果字串只包含數字則返回 True 否則返回 False 17 s.isidentifier() #如果字串是有效的表示符則返回 True 否則返回False 18 s.islower() #如果字串中包含至少一個區分大小寫的字元,並且所有這些(區分大小寫的)字元都是小寫,則返回 True,否則返回 False 19 s.isnumeric() #如果字串中只包含數字字元,則返回 True,否則返回 False 20 s.isprintable() #如果該字串可以列印返回True 否則返回False 21 s.isspace() #如果如果字串中只包含空格,則返回 True,否則返回 False. 22 s.istitle() #如果字串是標題化的則返回 True,否則返回 False 23 s.isupper() #如果字串中包含至少一個區分大小寫的字元,並且所有這些(區分大小寫的)字元都是大寫,則返回 True,否則返回 False 24 s.join() #以指定字串分割符分割串 引數:要連線的元素序列 25 s.ljust() #回一個原字串左對齊,填充至指定長度 引數:長度,以什麼填充(預設空格) 26 s.lower() #將字串中所有的大寫轉為小寫 27 s.lstrip() #截掉字串左邊的空格或指定字元。 引數:指定擷取的字元(預設空格) 28 s.maketrans() #建立字元對映轉換表 引數:intab:要代替的字元組成的子字串 outtab:要代替的字元組成的字串 29 s.partition() #在字串中以seq為分隔符,分割字串 引數:seq 分割方法 30 s.replace() #將,某個字元替換為另一個字元 引數:舊的字元,新的字元,替換次數(預設全部替換) 31 s.rfind() #類似find(),區別就是從右邊開始查詢 引數:查詢的字串,起始位置,結束位置 32 s.rindex() #類似index(),區別就是從右邊開始查詢 引數:查詢的字串,起始位置,結束位置 33 s.rjust() #與ljust()方法相似,區別就是右對齊,填充字串。 引數:長度,以什麼填充(預設空格) 34 s.rpartition() #在字串中以seq為分隔符,中字串右邊開始分割字串 引數:seq 分割符 35 s.rsplit() #以str為分割符擷取字串,從右邊開始擷取 引數:分隔符,分割次數 36 s.rstrip() # 截掉字串右邊的空格或指定字元。 引數:指定擷取的字元(預設空格) 37 s.split() # 以 str 為分隔符擷取字串 引數:分割符 分割次數 38 s.splitlines() #以按照行('\r', '\r\n', \n')分隔,返回一個包含各行作為元素的列表 引數:keepends 預設為False 為True則保留換行符 39 s.startwith() #檢測字串是否已str開頭 引數:檢索的字串,可選引數-設定起始位置,可選引數設定結束位置 40 s.strip() #去除字串兩邊的空格 引數:移除指定的序列 41 s.swapcase() #字串中的字元大小寫互換 42 s.title() #將字串轉換成標題格式 43 s.translate() #以指定錶轉換字串的字元(一般與maketrans配合使用) 引數:翻譯表,要過濾的字元 44 s.upper() #將字串中的小寫轉換為大寫 45 s.zfill() #返回長度為width的字串,原字串右對齊,前面以0填充 引數:長度 46 ###補充 47 len(s) #返回字串的長度
布林
作用:用來進行邏輯判斷
分為真或假(True False)
>>> a =3 >>> b = 5 >>> a > b False >>> a < b True
資料集
- 列表
- 字典
- 元組
- 集合
列表
列表的定義:有序的
列表的特性:有序可修改的資料集合
列表的建立
l1 = [1, 2, 3] # 建立空列表 l2 = [] l3 = list()
列表的操作


C:\Users\67525>python Python 3.6.6 (v3.6.6:4cf1f54eb7, Jun 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> l = [1,2,3,4,5,6,7,8] >>> # 訪問列表中的值 ... >>> l[1] 2 >>> # 取索引 ... >>> l.index(5) 4 >>> # 切片 ... >>> l[1:5] [2, 3, 4, 5] >>> # 新增 ... >>> l.append(8) >>> l [1, 2, 3, 4, 5, 6, 7, 8, 8] >>> l.insert(5,'5') >>> l [1, 2, 3, 4, 5, '5', 6, 7, 8, 8] >>> #修改 ... >>> l[0] = 0 >>> l [0, 2, 3, 4, 5, '5', 6, 7, 8, 8] >>> #刪除 >>> l.pop() 8 >>> l [0, 2, 3, 4, 5, '5', 6, 7, 8] >>> l.remove('5') >>> l [0, 2, 3, 4, 5, 6, 7, 8] >>> l.pop() 8 >>> l [0, 2, 3, 4, 5, '5', 6, 7, 8] >>> l.remove('5') >>> l [0, 2, 3, 4, 5, 6, 7, 8] >>> # 迴圈 >>> for i in l: ... print(i) ... 0 2 3 4 5 8 >>> # 排序 ... >>> l = ['a','c','B','e','F','d','m','N','@'] >>> l ['a', 'c', 'B', 'e', 'F', 'd', 'm', 'N', '@'] >>> l.sort() >>> l ['@', 'B', 'F', 'N', 'a', 'c', 'd', 'e', 'm'] >>> # 倒序 ... >>> l.reverse() >>> l ['m', 'e', 'd', 'c', 'a', 'N', 'F', 'B', '@'] >>>View Code
列表的方法詳解:
l = [1,23,3,4,5,6,7] l2 =['a','b'] l.append('追加') #追加一個值 引數:要追加的值 l.copy() #淺copy l.count(23) #檢視某個值在該列表中出現的次數 引數: 要檢視的值 l.extend(l2) #拼接列表 引數:要拼接的列表 l.index(3) #取列表中某個值得索引 引數:要取索引的值,起始位置,結束位置 l.insert(5,'插入') #插入一個值 引數:要插入的位置,要插入的值 l.pop() #取列表最後一個值,並刪除 引數:可選項,某個值得索引 l.remove() #刪除指定的值 引數:要刪除的值 l.reverswe() #倒序 l.sort() #排序 #引數 排序方法(預設Ascii碼)可選引數 ,是否倒序預設為false l.clear() #清空
深淺copy
l1 = [1,2,3,4,5] l2 = l1
該方法 l2則是完全指向了l1的記憶體地址,所以修改任意列表,其他列表也會跟著受影響。
淺copy:copy一份獨立的列表(如果有子列表子列表不獨立)。
列表的記憶體地址是獨立的,列表中的值的記憶體也是獨立的. 淺copy,則會給新的列表開闢新的記憶體地址,列表中的值則會使用原列表的記憶體地址,如果修改則會像字串一樣在對修改的值開闢一塊新的記憶體地址,因此兩個列表之間互相影響。 如果copy的列表中包含子列表(巢狀列表),由於子列表是兩個列表共享的,因此子列表並不是有單獨的記憶體地址,,所以修改子列表中的值,兩個列表都會受影響。
深copy:copy一份完全獨立的列表(包括子列表)
import copy l1 = [1,2,3,[4,5]] l2 = copy.deepcopy(l1)
字典
字典的特性:key-value結構、key必須可hash且必須為不可變資料型別而且唯一、可存放多個值
可修改、無序、查詢速度快
#建立字典 >>> dict={1:2,3:4,5:6,7:9,8:5} >>> dict {1: 2, 3: 4, 5: 6, 7: 9, 8: 5} #新增>>> >>> dict['test']=1 >>> dict {1: 2, 3: 4, 5: 6, 7: 9, 8: 5, 'test': 1} #修改 >>> dict['test'] = 3 >>> dict {1: 2, 3 4, 5: 6, 7: 9, 8: 5, 'test': 3} #查詢 >>> dict.get('test') 3 >>> dict['test'] #次方法如果一個key不存在就會報錯,而get方法則返回None 3 #迴圈 >>> for key in dict: ... print(key,dict[key]) ... 1 2 3 4 5 6 7 9 8 5 test 3
字典的方法詳解:
dict.clear() #清空字典 dict.copy() #淺copy dict.fromkeys() #建立一個新的字典,以指定的元素做字典的key,val為字典所有建對應的初始值 引數:字典鍵值列表,可選引數 鍵值序列的初始值 dict.get() #返回指定key的值,如果值不在字典中返回default值 引數:字典的鍵值 key不存在時返回的值 dict.keys() #返回列表的所有key dict.pop() #刪除字典給定鍵 key 所對應的值,返回值為被刪除的值。key值必須給出。 否則,返回default值。 引數:要刪除的鍵值,返回值 dict.popitem() #隨機返回並刪除字典中的一對鍵和值(一般刪除末尾對)。如果字典已經為空,卻呼叫了此方法,就報出KeyError異常 dict.setdefault() #與get()方法類似, 如果鍵不已經存在於字典中,將會新增鍵並將值設為預設值 引數:查詢的鍵值,返回的值 dict.update() #把字典引數 dict2 的 key/value(鍵/值) 對更新到字典 dict 裡。 引數:要新增的字典(dict2) dict.values() #返回列表裡所有的value
元組
元組的定義:與列表類似,由於不可變的特性被稱為只讀列表
元組的特性:有序不可變,如果元組中包含其他可變元素,這些可變元素可以改變
元組的操作:
name=('alex','test','shadan')
其他操作
t = (1,2,3,4,2,5,6) print(t.index(2,3,5)) print(t.count(2)) # t.index方法:取索引值 引數:要取索引的元組引數 , 從哪裡開始 , 到哪裡結束 # t.count方法:檢視某個引數在該元組中的個數 引數:取值物件 #切片 t1 = t[2::2] print(t1)
集合
集合的作用:去重,測試兩組資料之間的交集、差集、並集等關係。
集合的特點:無序且不重複的資料集合確定性(元素必須可hash)
集合的操作:
1 #集合的建立 2 >>> set = {1,2,3,4,5} 3 >>> set2 ={2,3,5,7,8} 4 #新增 5 >>> set.add(9) 6 >>> set 7 {1, 2, 3, 4, 5, 9} 8 >>> set.update([8,5,0]) 9 >>> set 10 {0, 1, 2, 3, 4, 5, 8, 9} 11 #刪除 12 >>> set.discard(8) 13 >>> set 14 {0, 1, 2, 3, 4, 5, 9} 15 >>> set.pop() 16 0 17 >>> set 18 {1, 2, 3, 4, 5, 9} 19 >>> set = {1,4,7,2,5,8,} 20 >>> set 21 {1, 2, 4, 5, 7, 8} 22 >>> set.remove(4) 23 >>> set
集合的關係測試:
#取交集 >>> set.intersection(set2) {2, 3, 5} >>> set&set2 {2, 3, 5} #取差集 >>> set.difference(set2) {1, 4, 9} >>> set-set2 {1, 4, 9} #取並集 >>> set.union(set2) {1, 2, 3, 4, 5, 7, 8, 9} >>> set | set2 {1, 2, 3, 4, 5, 7, 8, 9} #取對稱差集 >>> set.symmetric_difference(set2) {1, 4, 7, 8, 9} >>> set^set2 {1, 4, 7, 8, 9}
集合的方法詳解:
set = {1,2,3,4,5}
set.add() #新增一個值到該集合 引數:新增的元素
set.clear() #清空該集合
set.copy() #拷貝一個集合
set.difference() #取差集 引數:要取差集的集合
set.difference_update() #方法用於移除兩個集合中都存在的元素。 引數:用於計算差集的集合
set.discard() #刪除指定的集合元素,如果該元素更不存不會報錯 引數:要刪除的元素
set.intersection() #取交集 引數:要取交集的集合,其他要取交集的集合(可選引數)多個用逗號隔開
set.intersection_update() #方法用於移除兩個或更多集合中都不重疊的元素。 引數:要查詢相同元素的集合,其他要查詢相同元素的集合(可選項多個用逗號分隔)
set.isdisjoint() #判斷兩個集合是否包含相同元素 引數:要比較的集合
set.issubset() #判斷另一個集合是是否包含次集合 引數
set.issuperset() #判斷集合的所有元素是否都包含在指定集合中。 引數:要查詢的集合
set.pop() #隨機刪除一個元素
set.remove() #刪除一個指定的元素,如果該元素不存在則報錯 引數:要刪除的元素
set.symmetric_diffetrence() #返回兩個集合中不重複的元素集合 引數:要計算的集合
set.symmetric_diffetrence_update() #移除當前集合中在另外一個指定集合相同的元素,並將另外一個指定集合中不同的元素插入到當前集合中 #引數:要判斷的集合
set.union() #取並集 引數:要取並集的集合,可選多個集合用逗號分隔
set.update() #給集合新增元素 引數:新增的元素,可以是集合
控制流程
分支:判斷在特定的條件下執行特定的事件
- 單分支
- 雙分支
- 多分支
- 空語句(pass)
單分支
#語法: if 條件: 要執行的事件
雙分支:
#語法: if 條件: 要執行的事件 else: 要執行的事件
多分支:
if 條件: 要執行的事件 elif 條件:
要執行的事件 elif 條件:
要執行的事件 ... else:
要執行的事件
空語句:
pass
作用:為了保持程式的完整性,pass不做任何事情,一般用作佔位語句.
#語法
if 條件: pass else: 要執行的事件
迴圈:重複執行某些特定事件
- while迴圈
- 死迴圈
- while else
- for迴圈
while迴圈:
# 語法 while 條件: 要執行的事物
死迴圈dead loop:
# 語法
while 條件用於為真: 要執行的事物
while else:
作用:判斷迴圈是否被終止,在while條件為False的情況下執行else語句
while 條件: 要執行的事物 else: 要執行的事物
for迴圈
for i in range(10): print(i)
i 為臨時變數 range 可替換為列表或字典等..
for迴圈與while迴圈的區別:while迴圈可以是死迴圈而for迴圈不可以
迴圈終止語句
- break
- continue
break:完全終止迴圈,跳出迴圈體,執行迴圈體後面的語句
while 條件: if 條件: break else: 要執行的事物
continue:終止本次迴圈,執行後面的語句
while 條件: if 條件: continue else: 要執行的事物
進位制與字元編碼
進位制
- 二進位制
- 八進位制
- 十進位制
- 十六進位制
二進位制:
二進位制的定義:由於計算機只能識別0和1,所以0和1組成的二進位制碼就是二進位制數,最大可表現的10進位制數為
2**位數-1
二進位制的表現方式:01
二進位制與十進位制之間的運算:
填位法:
把165轉換為二機制
128 64 32 16 8 4 2 1 1 0 1 0 0 1 1 0
python自帶的方法
#引數:要轉換的數字 #例子 >>> bin(155) '0b10011011' >>>
八進位制
表現方式:12345678
八進位制與十進位制之間的運算
>>> oct(55) '0o67' >>>
十六進位制
表現方式:0123456789ABCDEF
十六進位制與二進位制之間的運算
取四合一法:https://jingyan.baidu.com/article/47a29f24292608c0142399cb.html
python自帶的方法
#python自帶的轉換方法 >>> hex(99) '0x63' >>>
字元編碼
二進位制與文字之間的關係:由於計算機只能識別二進位制碼,因此要識別文字需要特定的方法吧文字轉換為二進位制
ASCII:(American Standard Code for Information lnterchange)美國標準資訊轉換碼
ASCll碼的作用:把文字轉換為十進位制數
文字與二級制之間的轉換:
通過Ascll碼 把 *Xuange*轉換為二進位制 #十進位制 42 88 117 91 110 103 101 42 #二進位制 * 00101010 X 01011000 u 01110101 a 01011011 n 01101110 g 01100111 e 01100101 * 00101010
計算機如何區分字元間的二級制碼?
由於Ascll碼中最大的二級制數是255,而255轉換為二級制最多佔8位,所以表示每一個字元ASCII碼錶對應關係的二進位制數表示,不夠則以為0填充。
計算機種的儲存單位:
在二進位制中每一個0或1所佔的空間都為1bit,8bit等於1個位元組(bytes),位元組是計算機中最小的容量單位.
容量單位間的轉換:
8bit = 1B(bytes) bytes:位元組
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
字元編碼的發展:
由於Ascii碼不支援中文,所以要想使計算機識別中文就得另行僻徑。
GB2312:又稱國標碼,由國家標準局釋出。1981年5月1日實施,共收錄漢字6736個。
GBK1.0:1995年釋出GBK1.0,gbk編碼能夠同時表示簡體和繁體字,該編碼標準相容GB2312,共收錄漢字21003個,同時包含中日韓文中所有的漢字。
GB18030:2000年釋出,是對GBK編碼的擴充,覆蓋中文,日文,朝鮮語和中國少數名族文字,其中共收錄27484個漢字。同時相容GBK和GB2312編碼
BIG5編碼:1984年釋出,臺灣地區使用
為了解決各個國家編碼不互通的問題,ISO標準組織擬訂了UniCode編碼。
Unicode編碼:國際標準字符集,它將世界各種語言的沒個字元定義唯一編碼,以滿足跨語言、跨平臺的文字資訊轉換。Unicode(統一碼,萬國碼)規定每個字元和符號最少由16位來表示(2個位元組),即:2**16 =65536
UTF-8,是對uincode編碼的壓縮和優化,它不使用最少2個位元組,而是將所有的字元和符號分類:ASCII碼中的內容用1個位元組儲存,歐洲的字元用2個位元組儲存。東亞的字元用3個字元儲存
在Python中使用字元編碼
因為預設不支援中文,所以在python2中想要使用中文需要指定字元便碼.
報錯:
[email protected]:~$ python hello.py File "hello.py", line 2 SyntaxError: Non-ASCII character '\xe4' in file hello.py on line 2, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
解決:在標頭檔案指定字元編碼
#! -*- coding:utf-8 -*- #coding=utf-8
結果:
#指定字元編碼後 [email protected]:~$ python hello.py 你好 世界!
在python3中預設的字元編碼為utf-8,所以不需要考慮編碼的問題。
Windows中文版預設編碼:GBK
Mac oS/ Linux 預設編碼:UTF-8
編碼的一些補充
utf是UNincode編碼設計的一種在儲存和傳輸時節省空間的編碼方案.
字元編碼的儲存問題:以某種編碼儲存,必須以儲存的編碼方式開啟
在程式碼執行的過程中,python3會自動的把程式碼內容變成Unicode型別。而python2不會自動轉換,所以需要把內容重新解碼才可以正常顯示。
由於Windows中的預設編碼是GBK,而python2直譯器的預設編碼為ASCII,由於python2並不會把檔案內容變成Unicode。所以我們要手動的把內容變成Unicode。
UTF-8 --> decode 解碼 --> Unicode
Unicode --> encode 編碼 --> GBK / UTF-8 ..