
Grafana教程(prometheus 基本查詢語法)
prometheus原理可以參考:https://blog.csdn.net/luanpeng825485697/article/details/82318204
k8s上的部署可以參考: https://blog.csdn.net/luanpeng825485697/article/details/83755430
一、Data Source — 資料來源
Grafana支援多種不同的時序資料庫資料來源,Grafana對每種資料來源提供不同的查詢方法,而且能很好的支援每種資料來源的特性。
Grafana預設支援的資料來源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch
Grafana支援同時繫結多套資料來源,根據自己需求管理即可。
資料來源新增入口:
http://<ip>:3000/datasources/new
新增InfluxDB資料來源

其中主要需要關注的是Name、Type、HTTP Settings,以及InfluxDB Details
| 配置項 | ken.io 的解釋 |
|---|---|
| Name | 資料來源名稱,建議以資料來源型別+用途命名 |
| Type | 資料來源型別,選擇對應的InfluxDB即可 |
| URL | 填寫InfluxDB對應的API地址即可,如果Grafana跟InfluxDB不在同一臺機器,將localhost換成IP即可 |
| Access | API訪問方式,一共有Direct和Proxy兩個選項。建議選擇Proxy |
| Access-Direct | 瀏覽器直連資料來源API,然後由Grafana解析返回的資料 |
| Access-Proxy | Grafana後端通過API訪問資料來源,然後返回給瀏覽器展示 |
| Database | InfluxDB資料來源對應資料庫名稱 |
| User | InfluxDB資料來源賬號密碼 |
資料來源新增/更新成功後會有如下提示:
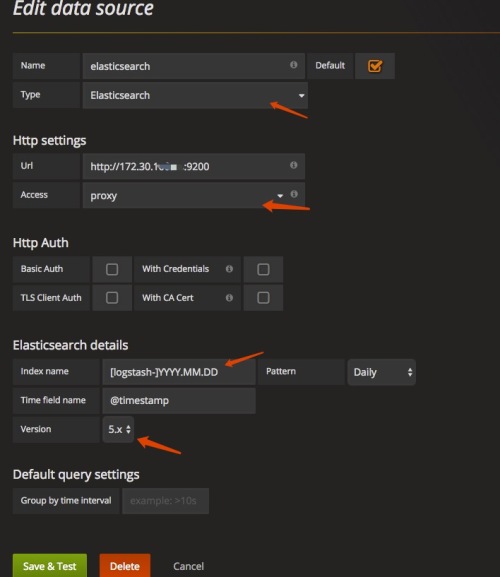
新增elasticsearch資料來源
預設Grafana是安裝了ES外掛的,如果沒裝需要安裝相應data source外掛。
點選Data Sources–>+ Add data source–> Type–>elasticsearch
Metric查詢編輯器
Elasticsearch查詢編輯器允許選擇多個指標和組由多個條款或過濾器。在右邊使用加號和減號圖示來新增/刪除索引或按子句分組。有些度量值和組子句都有選項,單擊選項文字以展開檢視並按選項編輯公制或組。
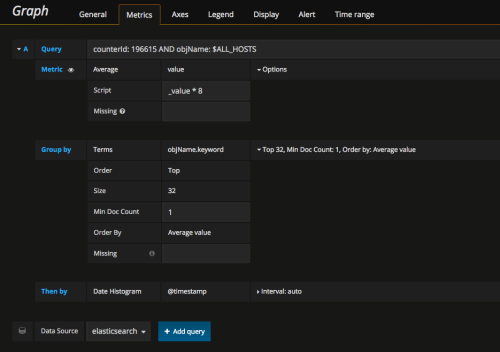
Query:Lucence查詢語法,跟kibana的查詢一樣,詳情請查閱ES的官方文件。
Metric:計量的標準,可以取最大、最小、平均值或者count條目數等,Options可以進行指令碼的計算,這裡我把value的值乘以8,來進行網路Byte和bite的換算。
Group by:排序標準。可以以時間軸進行排序,也可以以自定義的term進行排序。需要這裡需要注意一點,ES裡如果需要以自定義的字串term進行排序,會報錯:“Fielddata is disabled on text fields by default.”; 解決辦法是用"keyword"進行排序,需要手動加入字尾’.keyword’,參考文件如下:https://www.elastic.co/guide/en/elasticsearch/reference/current/fielddata.html
Query裡也可以用變數來代替,變數是在templating裡預先定義好的。後面再詳細介紹templating的概念。
二、Organization — 組織
Grafana為了支援多種部署模式支援多組織,包括使用一個單一的Grafana例項為多個潛在的不受信任的組織提供的服務。
在許多情況下,Grafana將部署一個單一的組織。
每個組織可以有一個或多個數據源。
所有的儀表板是由一個特定的組織擁有的。
三、User — 使用者
使用者在Grafana與賬戶是一個概念。
一個使用者可以屬於一個或多個組織,可以通過角色來分配不同的許可權。
Grafana支援多種使用者認證的方式。
更多的使用者管理詳情,可以看 文件的User Auth 部分。
四、Row — 行
行是Grafana在儀表盤介面的邏輯分割槽器,用於將多個面板連線在一起。
行一般是12個單位寬度。
單位寬度是Grafana為了支援不同解析度的螢幕所採取的一種策略,這樣Grafana可以在不同解析度的顯示器上擁有良好的展示效果。
五、Panel — 面板
面板是Grafana最基本的展示單位。
每個面板提供一個查詢編輯器(依賴於面板中選擇的資料來源),允許您利用查詢編輯器來編輯出一個完美的展示影象。
面板提供各種各樣的樣式和格式選項,而且支援拖拽來在儀表盤上重排,並且可以調整大小。
目前有四個面板型別:影象,狀態,面板列表,表格 等型別,而且也支援文字型別。
面板(或整個儀表板)可以以多種方式輕鬆共享,既可以通過連結分享,也可以匯出JSON等文字檔案。
六、Query Editor — 語句管理
Query Editor 顧名思義,就是語句管理,每個面板都提供一個Query Editor,我們可以通過編寫語句來控制面板展示不同的圖表。
七、Dashboard — 儀表盤
儀表盤是Grafana裡面最重要的展示部分。
儀表盤可以視為一組一個或多個面板組成的一個集合,來展示各種各樣的面板。
儀表盤也可以通過 註釋 來標記出各種各樣的事件。
儀表盤也支援通過多種不同的方式來共享,支援通過連結的方式共享或者匯出JSON等格式的檔案。
儀表盤還可以使用 模板 來允許使用者互動式的選擇資料來展示。
儀表盤由行(Row)+圖表面板(Panel)組成。
Panel主要支援:Graph,Singlestat,Dashlist,Table和Text。
儀表盤(Dashboard)新增入口:
http://<ip>:3000/dashboard/new
新增儀表盤(Dashboard)

點選設定(齒輪圖示)對儀表盤(Dashboard)進行設定
通常只需要關注Name這個選項即可,填寫完畢後,點選儲存按鈕儲存
或者使用快捷鍵(Ctrl+S)儲存設定/完成建立
新增面板(Panel)
儀表盤(Dashboard)建立完成後,只有一個空行
將滑鼠移動到行左上角的選單圖示,就會顯示行操作選單

這裡我們選擇Add Panel即可
這裡我們以曲線圖(Graph)為例

圖表面板配置
滑鼠單擊圖表標題可以撥出圖表選單
點選Edit進入編輯檢視,預設是Metric設定

主要配置項說明
| 配置項 | ken.io 的說明 |
|---|---|
| DataSource | 選擇Grafana已配置的資料來源 |
| FROM-Default | 預設Schema,保持不變即可 |
| FROM-measurement | 對應的InfluxDB的表名 |
| WHERE | WHERE條件,根據自己需求選擇 |
| SELECT-Field | 對應選的欄位,可根據需求增減 |
| SELECT-mean() | 選擇的欄位對應的InfluxDB的函式 |
| GroupBY-time() | 根據時間分組 |
| GROUPBY-fill() | 當不存在資料時,以null為預設值填充 |
以下是配置示例:
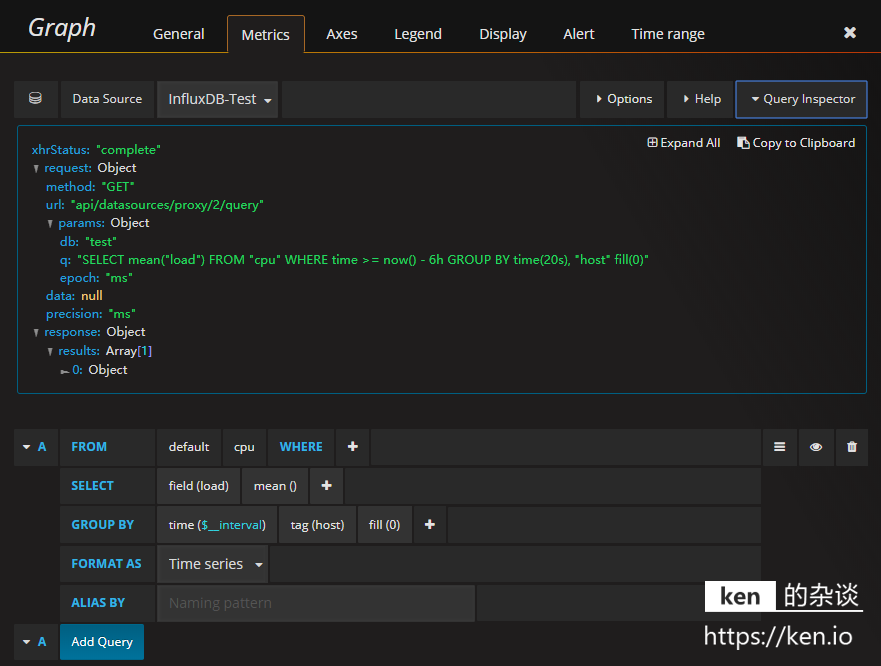
所有的配置項都會被解析生API請求的語法,具體解析的內容可以通過查詢檢查器(Query Inspector)檢視
接下來配置通用配置項(General)
ken.io 這裡只將Title設定為CPU-Load不做其他調整
圖表面板的配置完成後,不要忘記儲存儀表盤(Dashboard)
grafana映象重新封裝
由於官方grafana映象支援的資料來源或者展示面板不夠豐富,所以我們需要重新封裝映象
Dockerfile檔案內容如下
FROM grafana/grafana:latest
# 時鐘圖
Run grafana-cli plugins install grafana-clock-panel
# 餅圖
Run grafana-cli plugins install grafana-piechart-panel
# 氣泡圖
Run grafana-cli plugins install digrich-bubblechart-panel
#
Run grafana-cli plugins install raintank-worldping-app
# json資料
Run grafana-cli plugins install grafana-simple-json-datasource
#zabbix報警
Run grafana-cli plugins install alexanderzobnin-zabbix-app
prometheus 基本查詢語法
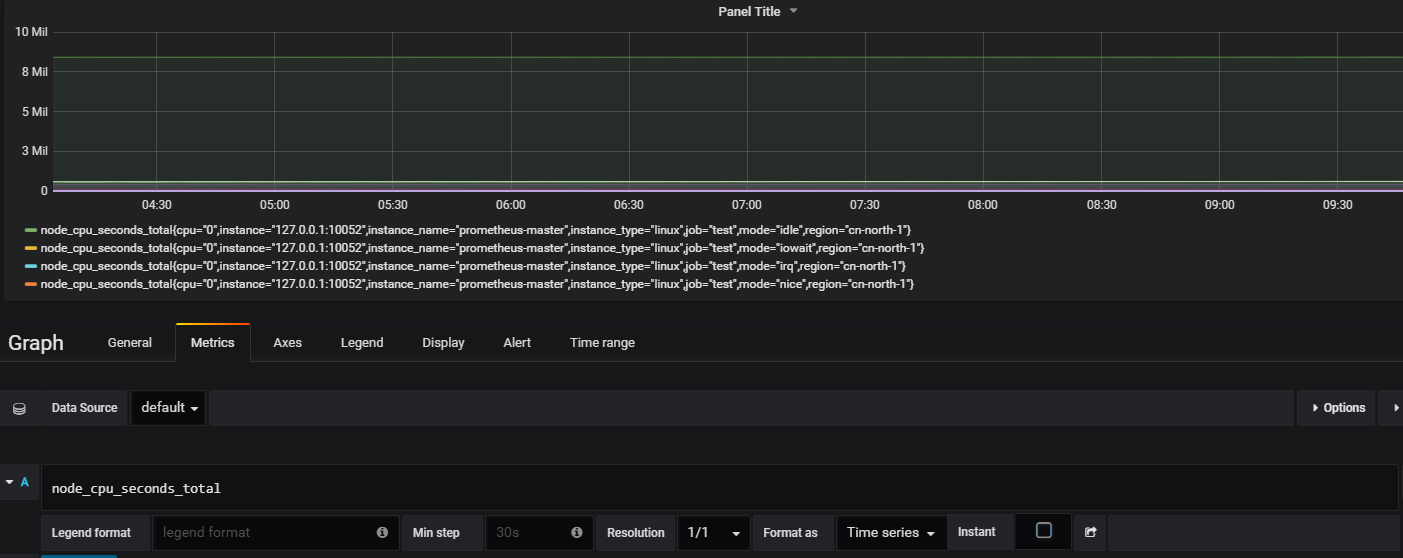
1,檢視指標
直接輸入指標名字就行了,grafana會自動補全
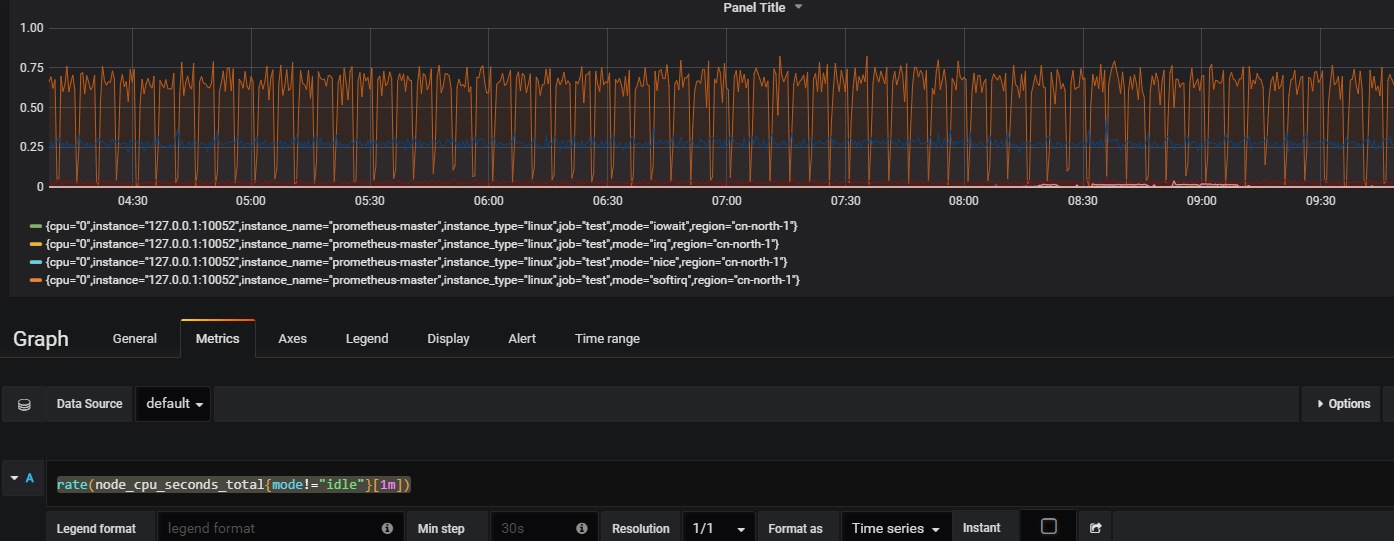
2,檢視某個指標的使用率,比如cpu使用率
用到rate函式,rate用來計算兩個間隔時間內發生的變化率。如
rate(指標名{篩選條件}[時間間隔])
比如檢視1分鐘內非idle的cpu使用率
rate(node_cpu_seconds_total{mode!=“idle”}[1m])
3,求和演算法
函式為sum,比如上面得到各個指標的cpu使用率,如果我想計算總的cpu使用率怎麼辦?
sum(rate(node_cpu_seconds_total{mode!=“idle”}[1m])) by (instance_name)
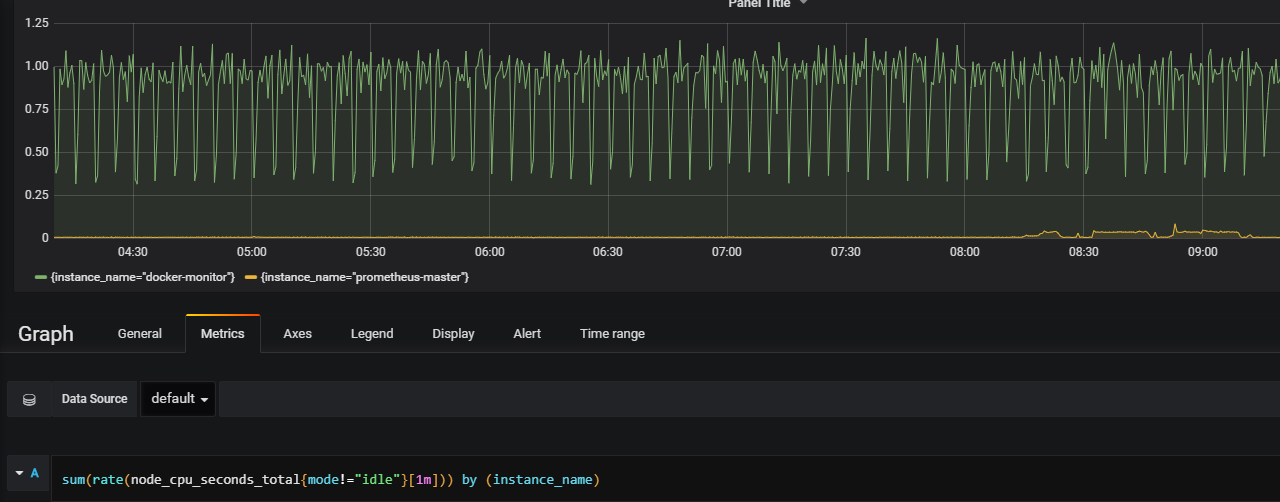
by的含義表示將結果根據instance_name來進行區分。跟mysql語句中 group by差不多。
參考官網:https://prometheus.io/docs/prometheus/latest/querying/basics/
八、總結
以上只是對Grafana裡的基本概念做了一個簡單的介紹,主要目的是幫助大家建立起對Grafana的基本印象,在以後的使用中,能做到心中有數。
參考:https://ken.io/note/grafana-quickstart-influxdb-datasource-graph
https://www.kancloud.cn/huyipow/prometheus/525003