
Mask R-CNN 論文筆記
論文題目:Mask R-CNN
論文連結:論文連結
論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結
一、Mask R-CNN是什麼,可以做哪些任務?
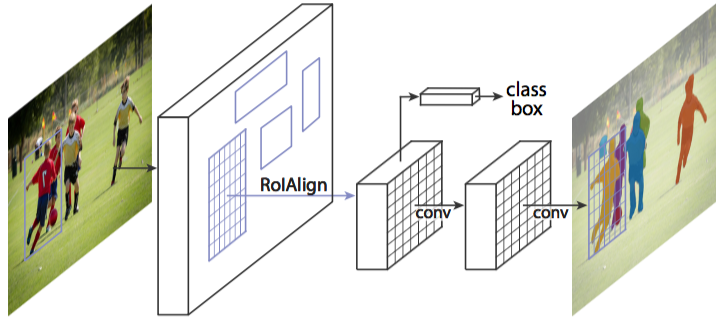
圖1 Mask R-CNN整體架構
Mask R-CNN是一個例項分割(Instance segmentation)演算法,可以用來做“目標檢測”、“目標例項分割”、“目標關鍵點檢測”。
1. 例項分割(Instance segmentation)和語義分割(Semantic segmentation)的區別與聯絡
聯絡:語義分割和例項分割都是目標分割中的兩個小的領域,都是用來對輸入的圖片做分割處理;
區別:

圖2 例項分割與語義分割區別
1. 通常意義上的目標分割指的是語義分割,語義分割已經有很長的發展歷史,已經取得了很好地進展,目前有很多的學者在做這方面的研究;然而例項分割是一個從目標分割領域獨立出來的一個小領域,是最近幾年才發展起來的,與前者相比,後者更加複雜,當前研究的學者也比較少,是一個有研究空間的熱門領域,如圖1所示,這是一個正在探索中的領域;
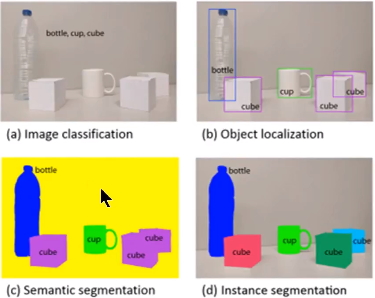
圖3 例項分割與語義分割區別
2. 觀察圖3中的c和d圖,c圖是對a圖進行語義分割的結果,d圖是對a圖進行例項分割的結果。兩者最大的區別就是圖中的"cube物件",在語義分割中給了它們相同的顏色,而在例項分割中卻給了不同的顏色。即例項分割需要在語義分割的基礎上對同類物體進行更精細的分割。
注:很多部落格中都沒有完全理解清楚這個問題,很多人將這個演算法看做語義分割,其實它是一個例項分割演算法。
2. Mask R-CNN可以完成的任務

圖4 Mask R-CNN進行目標檢測與例項分割

圖5 Mask R-CNN進行人體姿態識別
總之,Mask R-CNN是一個非常靈活的框架,可以增加不同的分支完成不同的任務,可以完成目標分類、目標檢測、語義分割、例項分割、人體姿勢識別等多種任務,真不愧是一個好演算法!
3. Mask R-CNN預期達到的目標
- 高速
- 高準確率(高的分類準確率、高的檢測準確率、高的例項分割準確率等)
- 簡單直觀
- 易於使用
4. 如何實現這些目標
高速和高準確率:為了實現這個目的,作者選用了經典的目標檢測演算法Faster-rcnn和經典的語義分割演算法FCN。Faster-rcnn可以既快又準的完成目標檢測的功能;FCN可以精準的完成語義分割的功能,這兩個演算法都是對應領域中的經典之作。Mask R-CNN比Faster-rcnn複雜,但是最終仍然可以達到5fps的速度,這和原始的Faster-rcnn的速度相當。由於發現了ROI Pooling中所存在的畫素偏差問題,提出了對應的ROIAlign策略,加上FCN精準的畫素MASK,使得其可以獲得高準確率。
簡單直觀:整個Mask R-CNN演算法的思路很簡單,就是在原始Faster-rcnn演算法的基礎上面增加了FCN來產生對應的MASK分支。即Faster-rcnn + FCN,更細緻的是 RPN + ROIAlign + Fast-rcnn + FCN。
易於使用:整個Mask R-CNN演算法非常的靈活,可以用來完成多種任務,包括目標分類、目標檢測、語義分割、例項分割、人體姿態識別等多個任務,這將其易於使用的特點展現的淋漓盡致。我很少見到有哪個演算法有這麼好的擴充套件性和易用性,值得我們學習和借鑑。除此之外,我們可以更換不同的backbone architecture和Head Architecture來獲得不同效能的結果。
二、Mask R-CNN框架解析
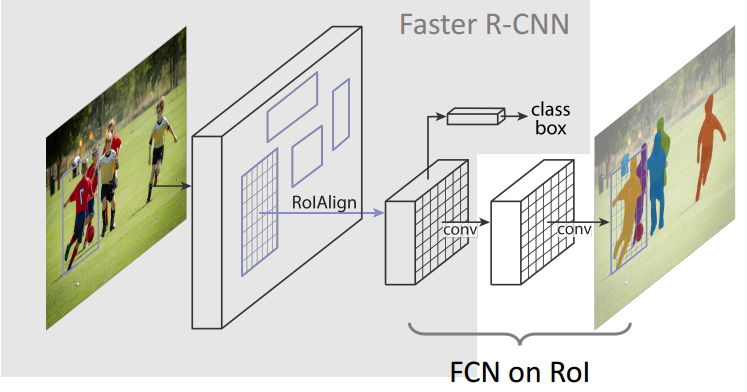
圖6 Mask R-CNN演算法框架
1. Mask R-CNN演算法步驟
- 首先,輸入一幅你想處理的圖片,然後進行對應的預處理操作,或者預處理後的圖片;
- 然後,將其輸入到一個預訓練好的神經網路中(ResNeXt等)獲得對應的feature map;
- 接著,對這個feature map中的每一點設定預定個的ROI,從而獲得多個候選ROI;
- 接著,將這些候選的ROI送入RPN網路進行二值分類(前景或背景)和BB迴歸,過濾掉一部分候選的ROI;
- 接著,對這些剩下的ROI進行ROIAlign操作(即先將原圖和feature map的pixel對應起來,然後將feature map和固定的feature對應起來);
- 最後,對這些ROI進行分類(N類別分類)、BB迴歸和MASK生成(在每一個ROI裡面進行FCN操作)。
2. Mask R-CNN架構分解
在這裡,我將Mask R-CNN分解為如下的3個模組,Faster-rcnn、ROIAlign和FCN。然後分別對這3個模組進行講解,這也是該演算法的核心。
3. Faster-rcnn(該演算法請參考該連結,我進行了詳細的分析)
4. FCN
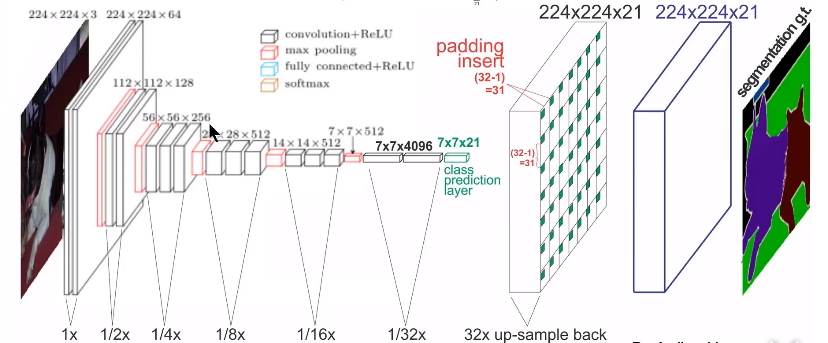
圖7 FCN網路架構
FCN演算法是一個經典的語義分割演算法,可以對圖片中的目標進行準確的分割。其總體架構如上圖所示,它是一個端到端的網路,主要的模快包括卷積和去卷積,即先對影象進行卷積和池化,使其feature map的大小不斷減小;然後進行反捲積操作,即進行插值操作,不斷的增大其feature map,最後對每一個畫素值進行分類。從而實現對輸入影象的準確分割。具體的細節請參考該連結。
5. ROIPooling和ROIAlign的分析與比較
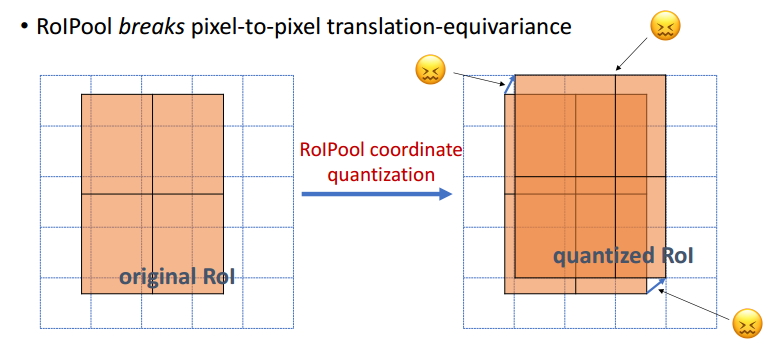 圖8
ROIPooling和ROIAlign的比較
如圖8所示,ROI Pooling和ROIAlign最大的區別是:前者使用了兩次量化操作,而後者並沒有採用量化操作,使用了線性插值演算法,具體的解釋如下所示。
圖8
ROIPooling和ROIAlign的比較
如圖8所示,ROI Pooling和ROIAlign最大的區別是:前者使用了兩次量化操作,而後者並沒有採用量化操作,使用了線性插值演算法,具體的解釋如下所示。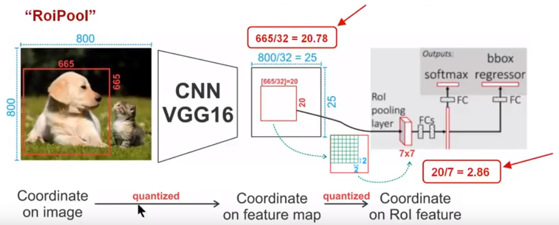
圖9 ROI Pooling技術
如圖9所示,為了得到固定大小(7X7)的feature map,我們需要做兩次量化操作:1)影象座標 — feature map座標,2)feature map座標 — ROI feature座標。我們來說一下具體的細節,如圖我們輸入的是一張800x800的影象,在影象中有兩個目標(貓和狗),狗的BB大小為665x665,經過VGG16網路後,我們可以獲得對應的feature map,如果我們對卷積層進行Padding操作,我們的圖片經過卷積層後保持原來的大小,但是由於池化層的存在,我們最終獲得feature map 會比原圖縮小一定的比例,這和Pooling層的個數和大小有關。在該VGG16中,我們使用了5個池化操作,每個池化操作都是2Pooling,因此我們最終獲得feature map的大小為800/32 x 800/32 = 25x25(是整數),但是將狗的BB對應到feature map上面,我們得到的結果是665/32 x 665/32 = 20.78 x 20.78,結果是浮點數,含有小數,但是我們的畫素值可沒有小數,那麼作者就對其進行了量化操作(即取整操作),即其結果變為20 x 20,在這裡引入了第一次的量化誤差;然而我們的feature map中有不同大小的ROI,但是我們後面的網路卻要求我們有固定的輸入,因此,我們需要將不同大小的ROI轉化為固定的ROI feature,在這裡使用的是7x7的ROI feature,那麼我們需要將20 x 20的ROI對映成7 x 7的ROI feature,其結果是 20 /7 x 20/7 = 2.86 x 2.86,同樣是浮點數,含有小數點,我們採取同樣的操作對其進行取整吧,在這裡引入了第二次量化誤差。其實,這裡引入的誤差會導致影象中的畫素和特徵中的畫素的偏差,即將feature空間的ROI對應到原圖上面會出現很大的偏差。原因如下:比如用我們第二次引入的誤差來分析,本來是2,86,我們將其量化為2,這期間引入了0.86的誤差,看起來是一個很小的誤差呀,但是你要記得這是在feature空間,我們的feature空間和影象空間是有比例關係的,在這裡是1:32,那麼對應到原圖上面的差距就是0.86 x 32 = 27.52。這個差距不小吧,這還是僅僅考慮了第二次的量化誤差。這會大大影響整個檢測演算法的效能,因此是一個嚴重的問題。好的,應該解釋清楚了吧,好累!
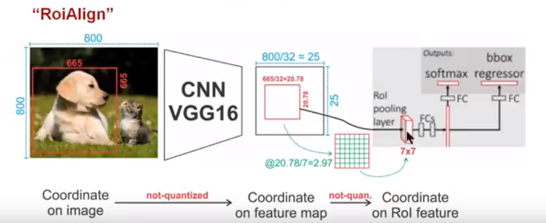
圖10 ROIAlign技術
如圖10所示,為了得到為了得到固定大小(7X7)的feature map,ROIAlign技術並沒有使用量化操作,即我們不想引入量化誤差,比如665 / 32 = 20.78,我們就用20.78,不用什麼20來替代它,比如20.78 / 7 = 2.97,我們就用2.97,而不用2來代替它。這就是ROIAlign的初衷。那麼我們如何處理這些浮點數呢,我們的解決思路是使用“雙線性插值”演算法。雙線性插值是一種比較好的影象縮放演算法,它充分的利用了原圖中虛擬點(比如20.56這個浮點數,畫素位置都是整數值,沒有浮點值)四周的四個真實存在的畫素值來共同決定目標圖中的一個畫素值,即可以將20.56這個虛擬的位置點對應的畫素值估計出來。厲害哈。如圖11所示,藍色的虛線框表示卷積後獲得的feature map,黑色實線框表示ROI feature,最後需要輸出的大小是2x2,那麼我們就利用雙線性插值來估計這些藍點(虛擬座標點,又稱雙線性插值的網格點)處所對應的畫素值,最後得到相應的輸出。這些藍點是2x2Cell中的隨機取樣的普通點,作者指出,這些取樣點的個數和位置不會對效能產生很大的影響,你也可以用其它的方法獲得。然後在每一個橘紅色的區域裡面進行max pooling或者average pooling操作,獲得最終2x2的輸出結果。我們的整個過程中沒有用到量化操作,沒有引入誤差,即原圖中的畫素和feature map中的畫素是完全對齊的,沒有偏差,這不僅會提高檢測的精度,同時也會有利於例項分割。這麼細心,做科研就應該關注細節,細節決定成敗。
we propose an RoIAlign layer that removes the harsh quantization of RoIPool, properly aligning the extracted features with the input. Our proposed change is simple: we avoid any quantization of the RoI boundaries or bins (i.e., we use x=16 instead of [x=16]). We use bilinear interpolation [22] to compute the exact values of the input features at four regularly sampled locations in each RoI bin, and aggregate the result (using max or average), see Figure 3 for details. We note that the results are not sensitive to the exact sampling locations, or how many points are sampled, as long as no quantization is performed。

圖11 雙線性插值
6. LOSS計算與分析
由於增加了mask分支,每個ROI的Loss函式如下所示:
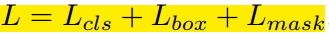
其中Lcls和Lbox和Faster r-cnn中定義的相同。對於每一個ROI,mask分支有Km*m維度的輸出,其對K個大小為m*m的mask進行編碼,每一個mask有K個類別。我們使用了per-pixel sigmoid,並且將Lmask定義為the average binary cross-entropy loss 。對應一個屬於GT中的第k類的ROI,Lmask僅僅在第k個mask上面有定義(其它的k-1個mask輸出對整個Loss沒有貢獻)。我們定義的Lmask允許網路為每一類生成一個mask,而不用和其它類進行競爭;我們依賴於分類分支所預測的類別標籤來選擇輸出的mask。這樣將分類和mask生成分解開來。這與利用FCN進行語義分割的有所不同,它通常使用一個per-pixel sigmoid和一個multinomial cross-entropy loss ,在這種情況下mask之間存在競爭關係;而由於我們使用了一個per-pixel sigmoid 和一個binary loss ,不同的mask之間不存在競爭關係。經驗表明,這可以提高例項分割的效果。
一個mask對一個目標的輸入空間佈局進行編碼,與類別標籤和BB偏置不同,它們通常需要通過FC層而導致其以短向量的形式輸出。我們可以通過由卷積提供的畫素和畫素的對應關係來獲得mask的空間結構資訊。具體的來說,我們使用FCN從每一個ROI中預測出一個m*m大小的mask,這使得mask分支中的每個層能夠明確的保持m×m空間佈局,而不將其摺疊成缺少空間維度的向量表示。和以前用fc層做mask預測的方法不同的是,我們的實驗表明我們的mask表示需要更少的引數,而且更加準確。這些畫素到畫素的行為需要我們的ROI特徵,而我們的ROI特徵通常是比較小的feature map,其已經進行了對其操作,為了一致的較好的保持明確的單畫素空間對應關係,我們提出了ROIAlign操作。
三、Mask R-CNN細節分析
1. Head Architecture
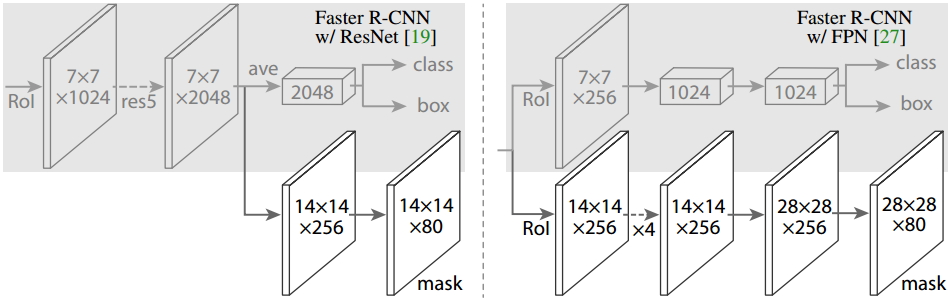
圖12 Head Architecture
如上圖所示,為了產生對應的Mask,文中提出了兩種架構,即左邊的Faster R-CNN/ResNet和右邊的Faster R-CNN/FPN。對於左邊的架構,我們的backbone使用的是預訓練好的ResNet,使用了ResNet倒數第4層的網路。輸入的ROI首先獲得7x7x1024的ROI feature,然後將其升維到2048個通道(這裡修改了原始的ResNet網路架構),然後有兩個分支,上面的分支負責分類和迴歸,下面的分支負責生成對應的mask。由於前面進行了多次卷積和池化,減小了對應的解析度,mask分支開始利用反捲積進行解析度的提升,同時減少通道的個數,變為14x14x256,最後輸出了14x14x80的mask模板。而右邊使用到的backbone是FPN網路,這是一個新的網路,通過輸入單一尺度的圖片,最後可以對應的特徵金字塔,如果想要了解它的細節,請參考該連結。得到證實的是,該網路可以在一定程度上面提高檢測的精度,當前很多的方法都用到了它。由於FPN網路已經包含了res5,可以更加高效的使用特徵,因此這裡使用了較少的filters。該架構也分為兩個分支,作用於前者相同,但是分類分支和mask分支和前者相比有很大的區別。可能是因為FPN網路可以在不同尺度的特徵上面獲得許多有用資訊,因此分類時使用了更少的濾波器。而mask分支中進行了多次卷積操作,首先將ROI變化為14x14x256的feature,然後進行了5次相同的操作(不清楚這裡的原理,期待著你的解釋),然後進行反捲積操作,最後輸出28x28x80的mask。即輸出了更大的mask,與前者相比可以獲得更細緻的mask。

圖13 BB輸出的mask結果
如上圖所示,影象中紅色的BB表示檢測到的目標,我們可以用肉眼可以觀察到檢測結果並不是很好,即整個BB稍微偏右,左邊的一部分畫素並沒有包括在BB之內,但是右邊顯示的最終結果卻很完美。
2. Equivariance in Mask R-CNN
Equivariance 指隨著輸入的變化輸出也會發生變化。
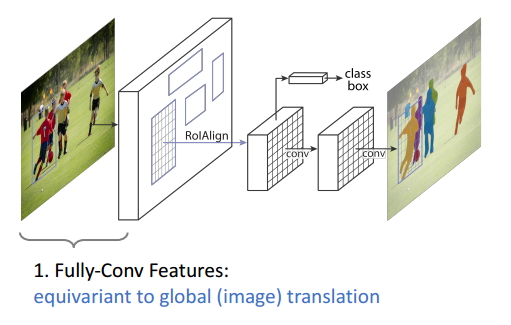 圖14
Equivariance 1
即全卷積特徵(Faster R-CNN網路)和影象的變換具有同變形,即隨著影象的變換,全卷積的特徵也會發生對應的變化;
圖14
Equivariance 1
即全卷積特徵(Faster R-CNN網路)和影象的變換具有同變形,即隨著影象的變換,全卷積的特徵也會發生對應的變化;
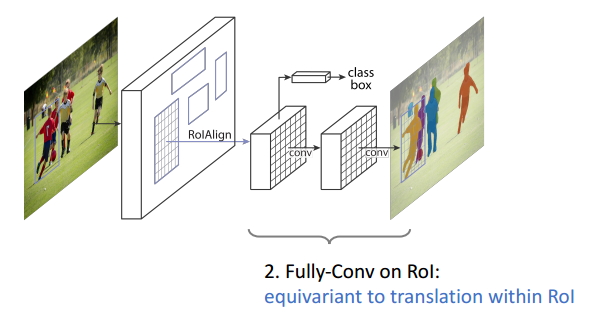
圖15 Equivariance2 在ROI上面的全卷積操作(FCN網路)和在ROI中的變換具有同變性;
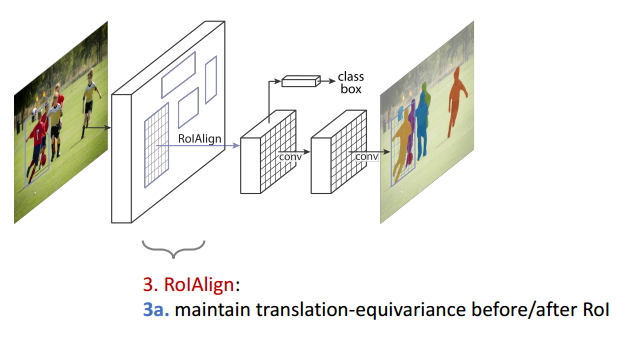
圖16 Equivariance3
ROIAlign操作保持了ROI變換前後的同變性;

圖17 ROI中的全卷積
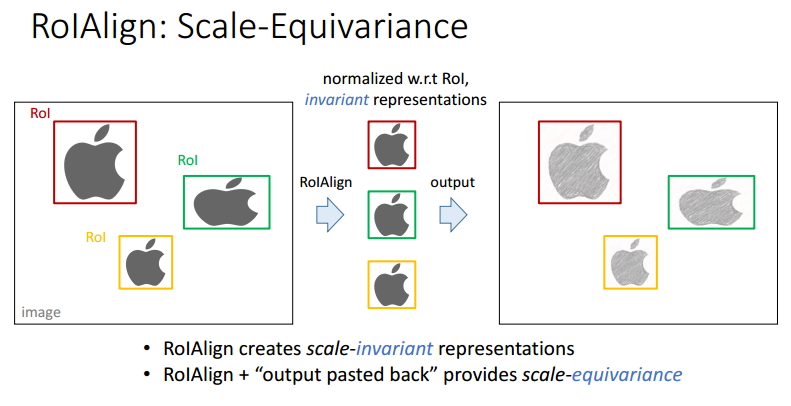
圖18 ROIAlign的尺度同變性

圖19 Mask R-CNN中的同變性總結
3. 演算法實現細節

圖20 演算法實現細節
觀察上圖,我們可以得到以下的資訊:
- Mask R-CNN中的超引數都是用了Faster r-cnn中的值,機智,省時省力,效果還好,別人已經替你調節過啦,哈哈哈;
- 使用到的預訓練網路包括ResNet50、ResNet101、FPN,都是一些效能很好地網路,尤其是FPN,後面會有分析;
- 對於過大的圖片,它會將其裁剪成800x800大小,影象太大的話會大大的增加計算量的;
- 利用8個GPU同時訓練,開始的學習率是0.01,經過18k次將其衰減為0.001,ResNet50-FPN網路訓練了32小時,ResNet101-FPN訓練了44小時;
- 在Nvidia Tesla M40 GPU上面的測試時間是195ms/張;
- 使用了MS COCO資料集,將120k的資料集劃分為80k的訓練集、35k的驗證集和5k的測試集;
四、效能比較
1. 定量結果分析
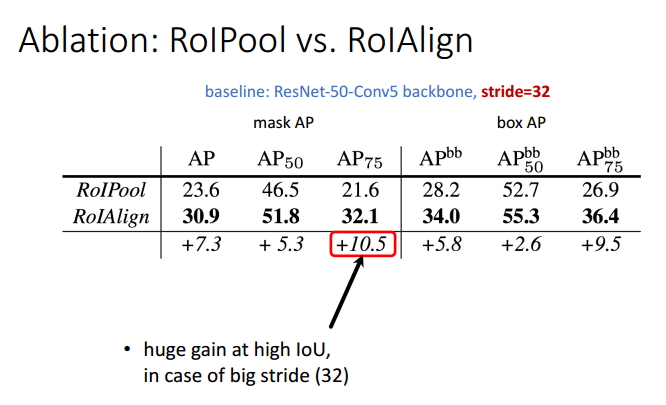
表1 ROI Pool和ROIAlign效能比較
由前面的分析,我們就可以定性的得到一個結論,ROIAlign會使得目標檢測的效果有很大的效能提升。根據上表,我們進行定量的分析,結果表明,ROIAlign使得mask的AP值提升了10.5個百分點,使得box的AP值提升了9.5個百分點。

表2 Multinomial和Binary loss比較
根據上表的分析,我們知道Mask R-CNN利用兩個分支將分類和mask生成解耦出來,然後利用Binary Loss代替Multinomial Loss,使得不同類別的mask之間消除了競爭。依賴於分類分支所預測的類別標籤來選擇輸出對應的mask。使得mask分支不需要進行重新的分類工作,使得效能得到了提升。

表3 MLP與FCN mask效能比較
如上表所示,MLP即利用FC來生成對應的mask,而FCN利用Conv來生成對應的mask,僅僅從引數量上來講,後者比前者少了很多,這樣不僅會節約大量的記憶體空間,同時會加速整個訓練過程(因此需要進行推理、更新的引數更少啦)。除此之外,由於MLP獲得的特徵比較抽象,使得最終的mask中丟失了一部分有用資訊,我們可以直觀的從右邊看到差別。從定性角度來講,FCN使得mask AP值提升了2.1個百分點。
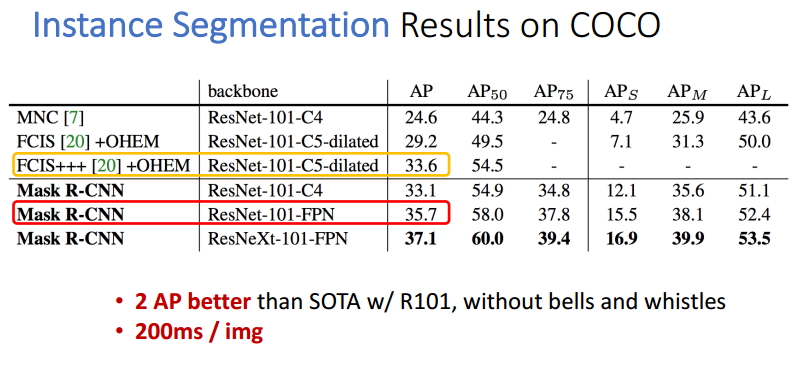
表4 例項分割的結果
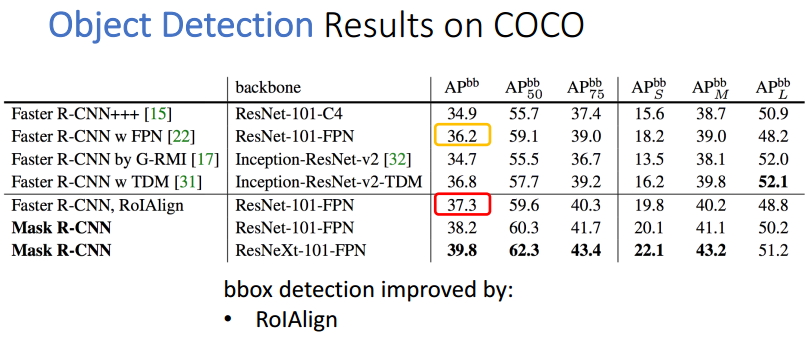
表5 目標檢測的結果
觀察目標檢測的表格,我們可以發現使用了ROIAlign操作的Faster R-CNN演算法效能得到了0.9個百分點,Mask R-CNN比最好的Faster R-CNN高出了2.6個百分點。
2. 定性結果分析
 圖21 例項分割結果1
圖21 例項分割結果1
 圖22 例項分割結果2
圖22 例項分割結果2
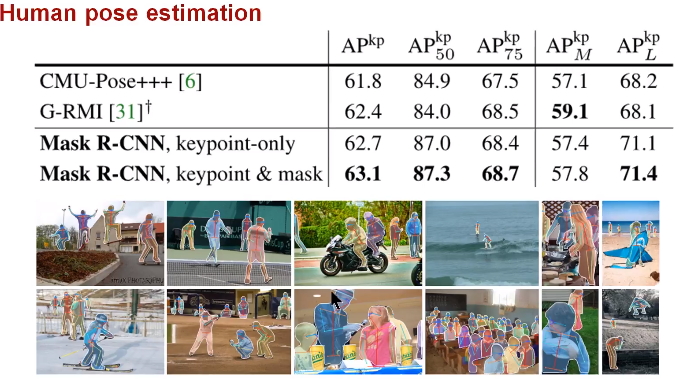 圖23 人體姿勢識別結果
圖23 人體姿勢識別結果
 圖24 失敗檢測案例1
圖24 失敗檢測案例1
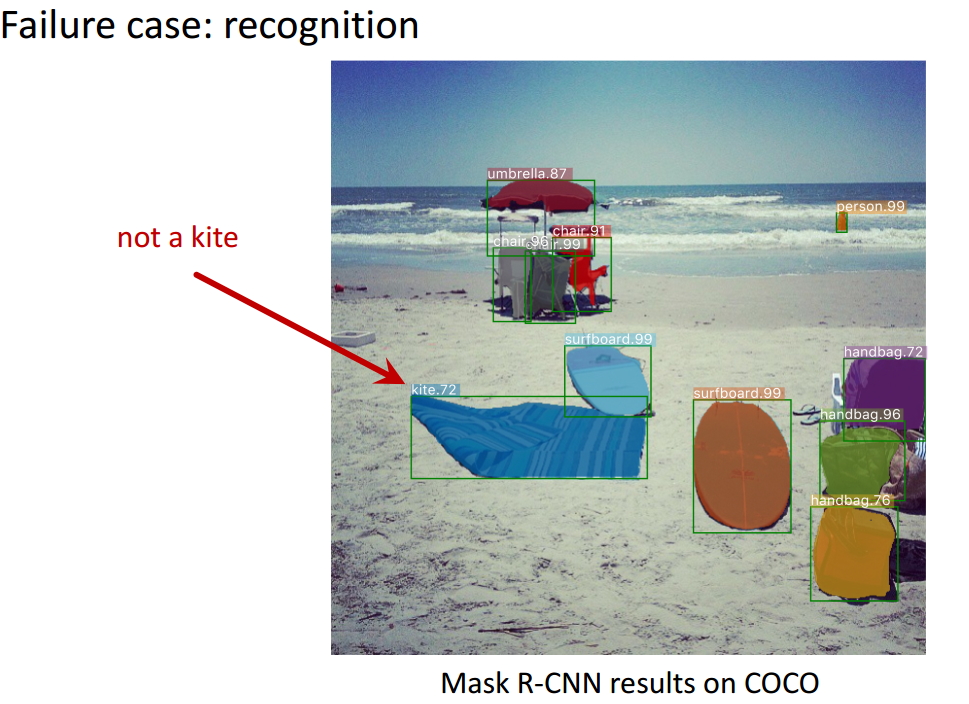 圖25 失敗檢測案例2
五、總結
圖25 失敗檢測案例2
五、總結
Mask R-CNN論文的主要貢獻包括以下幾點:
- 分析了ROI Pool的不足,提升了ROIAlign,提升了檢測和例項分割的效果;
- 將例項分割分解為分類和mask生成兩個分支,依賴於分類分支所預測的類別標籤來選擇輸出對應的mask。同時利用Binary Loss代替Multinomial Loss,消除了不同類別的mask之間的競爭,生成了準確的二值mask;
- 並行進行分類和mask生成任務,對模型進行了加速。
參考文獻:
[1] 何鎧明大神在ICCV2017上在的Slides,視訊連結
[2] Ardian Umam對Mask R-CNN的講解,視訊連結
注意事項:
[1] 該部落格是本人原創部落格,如果您對該部落格感興趣,想要轉載該部落格,請與我聯絡(qq郵箱:[email protected]),我會在第一時間回覆大家,謝謝大家。
[2] 由於個人能力有限,該部落格可能存在很多的問題,希望大家能夠提出改進意見。
[3] 如果您在閱讀本部落格時遇到不理解的地方,希望可以聯絡我,我會及時的回覆您,和您交流想法和意見,謝謝。
論文題目:Mask R-CNN
論文連結:論文連結
論文程式碼:Facebook程式碼連結;Tensorflow版本程式碼連結; Keras and TensorFlow版本程式碼連結;MxNet版本程式碼連結
一、Mask R-CNN是什麼,可以做哪些任務?
圖1 Mask R-CNN整體架構
Mask R-CNN是一個例項分割(Instance segmentation)演算法,可以用來做“目標檢測”、“目標例項分割”、“目標關鍵點檢測”。
1. 例項分割(Instance segmentation)和語義分割(Semantic segmentation)的區別與聯絡
聯絡:語義分割和例項分割都是目標分割中的兩個小的領域,都是用來對輸入的圖片做分割處理;
區別:
圖2 例項分割與語義分割區別
1. 通常意義上的目標分割指的是語義分割,語義分割已經有很長的發展歷史,已經取得了很好地進展,目前有很多的學者在做這方面的研究;然而例項分割是一個從目標分割領域獨立出來的一個小領域,是最近幾年才發展起來的,與前者相比,後者更加複雜,當前研究的學者也比較少,是一個有研究空間的熱門領域,如圖1所示,這是一個正在探索中的領域;
圖3 例項分割與語義分割區別
2. 觀察圖3中的c和d圖,c圖是對a圖進行語義分割的結果,d圖是對a圖進行例項分割的結果。兩者最大的區別就是圖中的"cube物件",在語義分割中給了它們相同的顏色,而在例項分割中卻給了不同的顏色。即例項分割需要在語義分割的基礎上對同類物體進行更精細的分割。
注:很多部落格中都沒有完全理解清楚這個問題,很多人將這個演算法看做語義分割,其實它是一個例項分割演算法。
2. Mask R-CNN可以完成的任務
圖4 Mask R-CNN進行目標檢測與例項分割
圖5 Mask R-CNN進行人體姿態識別
總之,Mask R-CNN是一個非常靈活的框架,可以增加不同的分支完成不同的任務,可以完成目標分類、目標檢測、語義分割、例項分割、人體姿勢識別等多種任務,真不愧是一個好演算法!
3. Mask R-CNN預期達到的目標
- 高速
- 高準確率(高的分類準確率、高的檢測準確率、高的例項分割準確率等)
- 簡單直觀
- 易於使用
4. 如何實現這些目標
高速和高準確率:為了實現這個目的,作者選用了經典的目標檢測演算法Faster-rcnn和經典的語義分割演算法FCN。Faster-rcnn可以既快又準的完成目標檢測的功能;FCN可以精準的完成語義分割的功能,這兩個演算法都是對應領域中的經典之作。Mask R-CNN比Faster-rcnn複雜,但是最終仍然可以達到5fps的速度,這和原始的Faster-rcnn的速度相當。由於發現了ROI Pooling中所存在的畫素偏差問題,提出了對應的ROIAlign策略,加上FCN精準的畫素MASK,使得其可以獲得高準確率。
簡單直觀:整個Mask R-CNN演算法的思路很簡單,就是在原始Faster-rcnn演算法的基礎上面增加了FCN來產生對應的MASK分支。即Faster-rcnn + FCN,更細緻的是 RPN + ROIAlign + Fast-rcnn + FCN。
易於使用:整個Mask R-CNN演算法非常的靈活,可以用來完成多種任務,包括目標分類、目標檢測、語義分割、例項分割、人體姿態識別等多個任務,這將其易於使用的特點展現的淋漓盡致。我很少見到有哪個演算法有這麼好的擴充套件性和易用性,值得我們學習和借鑑。除此之外,我們可以更換不同的backbone architecture和Head Architecture來獲得不同效能的結果。
二、Mask R-CNN框架解析
圖6 Mask R-CNN演算法框架
1. Mask R-CNN演算法步驟
- 首先,輸入一幅你想處理的圖片,然後進行對應的預處理操作,或者預處理後的圖片;
- 然後,將其輸入到一個預訓練好的神經網路中(ResNeXt等)獲得對應的feature map;
- 接著,對這個feature map中的每一點設定預定個的ROI,從而獲得多個候選ROI;
- 接著,將這些候選的ROI送入RPN網路進行二值分類(前景或背景)和BB迴歸,過濾掉一部分候選的ROI;
- 接著,對這些剩下的ROI進行ROIAlign操作(即先將原圖和feature map的pixel對應起來,然後將feature map和固定的feature對應起來);
- 最後,對這些ROI進行分類(N類別分類)、BB迴歸和MASK生成(在每一個ROI裡面進行FCN操作)。
2. Mask R-CNN架構分解
在這裡,我將Mask R-CNN分解為如下的3個模組,Faster-rcnn、ROIAlign和FCN。然後分別對這3個模組進行講解,這也是該演算法的核心。
3. Faster-rcnn(該演算法請參考該連結,我進行了詳細的分析)
4. FCN
圖7 FCN網路架構
FCN演算法是一個經典的語義分割演算法,可以對圖片中的目標進行準確的分割。其總體架構如上圖所示,它是一個端到端的網路,主要的模快包括卷積和去卷積,即先對影象進行卷積和池化,使其feature map的大小不斷減小;然後進行反捲積操作,即進行插值操作,不斷的增大其feature map,最後對每一個畫素值進行分類。從而實現對輸入影象的準確分割。具體的細節請參考該連結。
5. ROIPooling和ROIAlign的分析與比較
圖8
ROIPooling和ROIAlign的比較
如圖8所示,ROI Pooling和ROIAlign最大的區別是:前者使用了兩次量化操作,而後者並沒有採用量化操作,使用了線性插值演算法,具體的解釋如下所示。圖9 ROI Pooling技術
如圖9所示,為了得到固定大小(7X7)的feature map,我們需要做兩次量化操作:1)影象座標 — feature map座標,2)feature map座標 — ROI feature座標。我們來說一下具體的細節,如圖我們輸入的是一張800x800的影象,在影象中有兩個目標(貓和狗),狗的BB大小為665x665,經過VGG16網路後,我們可以獲得對應的feature map,如果我們對卷積層進行Padding操作,我們的圖片經過卷積層後保持原來的大小,但是由於池化層的存在,我們最終獲得feature map 會比原圖縮小一定的比例,這和Pooling層的個數和大小有關。在該VGG16中,我們使用了5個池化操作,每個池化操作都是2Pooling,因此我們最終獲得feature map的大小為800/32 x 800/32 = 25x25(是整數),但是將狗的BB對應到feature map上面,我們得到的結果是665/32 x 665/32 = 20.78 x 20.78,結果是浮點數,含有小數,但是我們的畫素值可沒有小數,那麼作者就對其進行了量化操作(即取整操作),即其結果變為20 x 20,在這裡引入了第一次的量化誤差;然而我們的feature map中有不同大小的ROI,但是我們後面的網路卻要求我們有固定的輸入,因此,我們需要將不同大小的ROI轉化為固定的ROI feature,在這裡使用的是7x7的ROI feature,那麼我們需要將20 x 20的ROI對映成7 x 7的ROI feature,其結果是 20 /7 x 20/7 = 2.86 x 2.86,同樣是浮點數,含有小數點,我們採取同樣的操作對其進行取整吧,在這裡引入了第二次量化誤差。其實,這裡引入的誤差會導致影象中的畫素和特徵中的畫素的偏差,即將feature空間的ROI對應到原圖上面會出現很大的偏差。原因如下:比如用我們第二次引入的誤差來分析,本來是2,86,我們將其量化為2,這期間引入了0.86的誤差,看起來是一個很小的誤差呀,但是你要記得這是在feature空間,我們的feature空間和影象空間是有比例關係的,在這裡是1:32,那麼對應到原圖上面的差距就是0.86 x 32 = 27.52。這個差距不小吧,這還是僅僅考慮了第二次的量化誤差。這會大大影響整個檢測演算法的效能,因此是一個嚴重的問題。好的,應該解釋清楚了吧,好累!
圖10 ROIAlign技術
如圖10所示,為了得到為了得到固定大小(7X7)的feature map,ROIAlign技術並沒有使用量化操作,即我們不想引入量化誤差,比如665 / 32 = 20.78,我們就用20.78,不用什麼20來替代它,比如20.78 / 7 = 2.97,我們就用2.97,而不用2來代替它。這就是ROIAlign的初衷。那麼我們如何處理這些浮點數呢,我們的解決思路是使用“雙線性插值”演算法。雙線性插值是一種比較好的影象縮放演算法,它充分的利用了原圖中虛擬點(比如20.56這個浮點數,畫素位置都是整數值,沒有浮點值)四周的四個真實存在的畫素值來共同決定目標圖中的一個畫素值,即可以將20.56這個虛擬的位置點對應的畫素值估計出來。厲害哈。如圖11所示,藍色的虛線框表示卷積後獲得的feature map,黑色實線框表示ROI feature,最後需要輸出的大小是2x2,那麼我們就利用雙線性插值來估計這些藍點(虛擬座標點,又稱雙線性插值的網格點)處所對應的畫素值,最後得到相應的輸出。這些藍點是2x2Cell中的隨機取樣的普通點,作者指出,這些取樣點的個數和位置不會對效能產生很大的影響,你也可以用其它的方法獲得。然後在每一個橘紅色的區域裡面進行max pooling或者average pooling操作,獲得最終2x2的輸出結果。我們的整個過程中沒有用到量化操作,沒有引入誤差,即原圖中的畫素和feature map中的畫素是完全對齊的,沒有偏差,這不僅會提高檢測的精度,同時也會有利於例項分割。這麼細心,做科研就應該關注細節,細節決定成敗。
we propose an RoIAlign layer that removes the harsh quantization of RoIPool, properly aligning the extracted features with the input. Our proposed change is simple: we avoid any quantization of the RoI boundaries or bins (i.e., we use x=16 instead of [x=16]). We use bilinear interpolation [22] to compute the exact values of the input features at four regularly sampled locations in each RoI bin, and aggregate the result (using max or average), see Figure 3 for details. We note that the results are not sensitive to the exact sampling locations, or how many points are sampled, as long as no quantization is performed。
圖11 雙線性插值
6. LOSS計算與分析
由於增加了mask分支,每個ROI的Loss函式如下所示:
其中Lcls和Lbox和Faster r-cnn中定義的相同。對於每一個ROI,mask分支有Km*m維度的輸出,其對K個大小為m*m的mask進行編碼,每一個mask有K個類別。我們使用了per-pixel sigmoid,並且將Lmask定義為the average binary cross-entropy loss 。對應一個屬於GT中的第k類的ROI,Lmask僅僅在第k個mask上面有定義(其它的k-1個mask輸出對整個Loss沒有貢獻)。我們定義的Lmask允許網路為每一類生成一個mask,而不用和其它類進行競爭;我們依賴於分類分支所預測的類別標籤來選擇輸出的mask。這樣將分類和mask生成分解開來。這與利用FCN進行語義分割的有所不同,它通常使用一個per-pixel sigmoid和一個multinomial cross-entropy loss ,在這種情況下mask之間存在競爭關係;而由於我們使用了一個per-pixel sigmoid 和一個binary loss ,不同的mask之間不存在競爭關係。經驗表明,這可以提高例項分割的效果。
一個mask對一個目標的輸入空間佈局進行編碼,與類別標籤和BB偏置不同,它們通常需要通過FC層而導致其以短向量的形式輸出。我們可以通過由卷積提供的畫素和畫素的對應關係來獲得mask的空間結構資訊。具體的來說,我們使用FCN從每一個ROI中預測出一個m*m大小的mask,這使得mask分支中的每個層能夠明確的保持m×m空間佈局,而不將其摺疊成缺少空間維度的向量表示。和以前用fc層做mask預測的方法不同的是,我們的實驗表明我們的mask表示需要更少的引數,而且更加準確。這些畫素到畫素的行為需要我們的ROI特徵,而我們的ROI特徵通常是比較小的feature map,其已經進行了對其操作,為了一致的較好的保持明確的單畫素空間對應關係,我們提出了ROIAlign操作。
三、Mask R-CNN細節分析
1. Head Architecture
圖12 Head Architecture
如上圖所示,為了產生對應的Mask,文中提出了兩種架構,即左邊的Faster R-CNN/ResNet和右邊的Faster R-CNN/FPN。對於左邊的架構,我們的backbone使用的是預訓練好的ResNet,使用了ResNet倒數第4層的網路。輸入的ROI首先獲得7x7x1024的ROI feature,然後將其升維到2048個通道(這裡修改了原始的ResNet網路架構),然後有兩個分支,上面的分支負責分類和迴歸,下面的分支負責生成對應的mask。由於前面進行了多次卷積和池化,減小了對應的解析度,mask分支開始利用反捲積進行解析度的提升,同時減少通道的個數,變為14x14x256,最後輸出了14x14x80的mask模板。而右邊使用到的backbone是FPN網路,這是一個新的網路,通過輸入單一尺度的圖片,最後可以對應的特徵金字塔,如果想要了解它的細節,請參考該連結。得到證實的是,該網路可以在一定程度上面提高檢測的精度,當前很多的方法都用到了它。由於FPN網路已經包含了res5,可以更加高效的使用特徵,因此這裡使用了較少的filters。該架構也分為兩個分支,作用於前者相同,但是分類分支和mask分支和前者相比有很大的區別。可能是因為FPN網路可以在不同尺度的特徵上面獲得許多有用資訊,因此分類時使用了更少的濾波器。而mask分支中進行了多次卷積操作,首先將ROI變化為14x14x256的feature,然後進行了5次相同的操作(不清楚這裡的原理,期待著你的解釋),然後進行反捲積操作,最後輸出28x28x80的mask。即輸出了更大的mask,與前者相比可以獲得更細緻的mask。
圖13 BB輸出的mask結果
如上圖所示,影象中紅色的BB表示檢測到的目標,我們可以用肉眼可以觀察到檢測結果並不是很好,即整個BB稍微偏右,左邊的一部分畫素並沒有包括在BB之內,但是右邊顯示的最終結果卻很完美。
2. Equivariance in Mask R-CNN
Equivariance 指隨著輸入的變化輸出也會發生變化。
圖14
Equivariance 1
即全卷積特徵(Faster R-CNN網路)和影象的變換具有同變形,即隨著影象的變換,全卷積的特徵也會發生對應的變化;
圖15 Equivariance2 在ROI上面的全卷積操作(FCN網路)和在ROI中的變換具有同變性;
圖16 Equivariance3
ROIAlign操作保持了ROI變換前後的同變性;
圖17 ROI中的全卷積
圖18 ROIAlign的尺度同變性
圖19 Mask R-CNN中的同變性總結
3. 演算法實現細節
圖20 演算法實現細節
觀察上圖,我們可以得到以下的資訊:
- Mask R-CNN中的超引數都是用了Faster r-cnn中的值,機智,省時省力,效果還好,別人已經替你調節過啦,哈哈哈;
- 使用到的預訓練網路包括ResNet50、ResNet101、FPN,都是一些效能很好地網路,尤其是FPN,後面會有分析;
- 對於過大的圖片,它會將其裁剪成800x800大小,影象太大的話會大大的增加計算量的;
- 利用8個GPU同時訓練,開始的學習率是0.01,經過18k次將其衰減為0.001,ResNet50-FPN網路訓練了32小時,ResNet101-FPN訓練了44小時;
- 在Nvidia Tesla M40 GPU上面的測試時間是195ms/張;
- 使用了MS COCO資料集,將120k的資料集劃分為80k的訓練集、35k的驗證集和5k的測試集;
四、效能比較
1. 定量結果分析
表1 ROI Pool和ROIAlign效能比較
由前面的分析,我們就可以定性的得到一個結論,ROIAlign會使得目標檢測的效果有很大的效能提升。根據上表,我們進行定量的分析,結果表明,ROIAlign使得mask的AP值提升了10.5個百分點,使得box的AP值提升了9.5個百分點。
表2 Multinomial和Binary loss比較
根據上表的分析,我們知道Mask R-CNN利用兩個分支將分類和mask生成解耦出來,然後利用Binary Loss代替Multinomial Loss,使得不同類別的mask之間消除了競爭。依賴於分類分支所預測的類別標籤來選擇輸出對應的mask。使得mask分支不需要進行重新的分類工作,使得效能得到了提升。
表3 MLP與FCN mask效能比較
如上表所示,MLP即利用FC來生成對應的mask,而FCN利用Conv來生成對應的mask,僅僅從引數量上來講,後者比前者少了很多,這樣不僅會節約大量的記憶體空間,同時會加速整個訓練過程(因此需要進行推理、更新的引數更少啦)。除此之外,由於MLP獲得的特徵比較抽象,使得最終的mask中丟失了一部分有用資訊,我們可以直觀的從右邊看到差別。從定性角度來講,FCN使得mask AP值提升了2.1個百分點。
表4 例項分割的結果
表5 目標檢測的結果
觀察目標檢測的表格,我們可以發現使用了ROIAlign操作的Faster R-CNN演算法效能得到了0.9個百分點,Mask R-CNN比最好的Faster R-CNN高出了2.6個百分點。
2. 定性結果分析
圖21 例項分割結果1
圖22 例項分割結果2
圖23 人體姿勢識別結果
圖24 失敗檢測案例1
圖25 失敗檢測案例2
五、總結
Mask R-CNN論文的主要貢獻包括以下幾點:
- 分析了ROI Pool的不足,提升了ROIAlign,提升了檢測和例項分割的效果;
- 將例項分割分解為分類和mask生成兩個分支,依賴於分類分支所預測的類別標籤來選擇輸出對應的mask。同時利用Binary Loss代替Multinomial Loss,消除了不同類別的mask之間的競爭,生成了準確的二值mask;
- 並行進行分類和mask生成任務,對模型進行了加速。
參考文獻:
[1] 何鎧明大神在ICCV2017上在的Slides,視訊連結
[2] Ardian Umam對Mask R-CNN的講解,視訊連結
注意事項:
[1] 該部落格是本人原創部落格,如果您對該部落格感興趣,想要轉載該部落格,請與我聯絡(qq郵箱:[email protected]),我會在第一時間回覆大家,謝謝大家。
[2] 由於個人能力有限,該部落格可能存在很多的問題,希望大家能夠提出改進意見。
[3] 如果您在閱讀本部落格時遇到不理解的地方,希望可以聯絡我,我會及時的回覆您,和您交流想法和意見,謝謝。