
高並發Haproxy壓力測試與優化之道
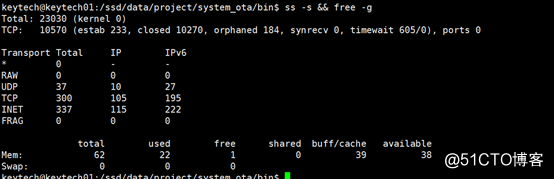
先觀察上面截圖,可以看到兩個關鍵信息:
? 這臺機器已經建立了 2.3 萬個 TCP 連接
? 使用內存大約在 22G。
測試目標
我們要測試的組件是 HAProxy 1.6 版。生產環境是在 4 核 30 G 的機器上運行該軟件,當前所有的連接都是非 SSL 的。
測試目標有兩方面:
- 當將整個負載從非 SSL 連接轉移到 SSL 連接時,CPU 使用率增加的百分比。CPU 的使用率肯定會增加,這是由於 5 次握手的加長和數據包加密的開銷所帶來。
- 其次,希望能夠測試單個 HAProxy 每秒請求數和最大並發連接數的上限組件和配置
? 使用多臺客戶端機器來執行 HAProxy 壓力測試。
? 有各種配置的 HAProxy 1.6 的機器
? 4核,30G
? 16核,30G
? 16核,64G
? 相關後端服務器,用於支持所有並發訪問。
HTTP 和 MQTT
我們的整個基礎設施支持兩種協議:
? HTTP
? MQTT
在我們的技術棧中,沒有使用 HTTP 2.0,因此在 HTTP 上沒有長連的功能。所以在生產環境中,單個 HAProxy 機器(上行 + 下行)的最大數量的 TCP 連接在(2 * 150k)左右。雖然並發連接數量相當低,但每秒請求的數量卻相當高。
另一方面,MQTT 是一種不同的通信方式。它提供高質量的服務參數和持久的連接性。因此,可以在 MQTT 通道上使用雙向長連通信。對於支持 MQTT(底層 TCP)連接的 HAProxy,在高峰時段會看到每臺機器上大約有 600 - 700k 個 TCP 連接。
有很多工具可以幫助我們輕松地測試 HTTP 服務器,並且提供了高級功能,如結果匯總,將文本轉換為圖形等。然而,針對 MQTT,我們找不到任何壓力測試工具。我們確實有一個自己開發的工具,但是它不夠穩定,不足以支持這種負載。
所以我們決定使用客戶端測試 HTTP 負載,並在 MQTT 服務器使用相同配置。
初始化設置
考慮到相關內容對於進行類似的壓力測試或調優的人來說有幫助,本文提供了很多相關細節,篇幅稍微有些長。
? 我們采用了一臺 16 核 30G 機器來運行 HAProxy,考慮到 HAProxy 的 SSL 產生的 CPU 巨大開銷,因此沒有直接使用目前生產環境。
? 對於客戶端,我們最終使用 Apache Bench。使用 ab 的原因是因為它是一個大家熟悉和穩定的負載測試工具,它也提供了很好的測試結果匯總,這正是我們所需要的。
ab 工具提供了許多有用的參數用於我們的負載測試,如:
? -c,指定訪問服務器的並發請求數。
? -n,顧名思義,指定當前負載運行的請求總數。
? -p,包含 POST 請求的正文(要測試的內容)。
如果仔細觀察這些參數,您會發現通過調整所有這三個參數可以進行很多排列組合。示例 ab 請求將看起來像這樣
ab -S -p post_smaller.txt -T application/json -q -n 100000 -c 3000 http://test.haproxy.in:80/ping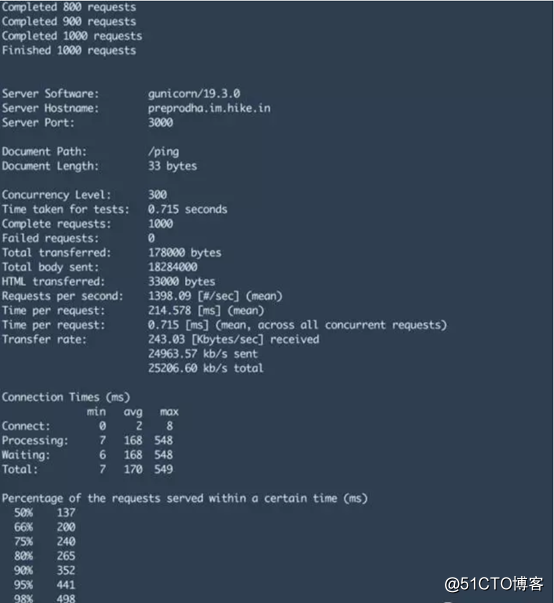
我們感興趣的數字是:
? 99% 的返回請求的響應延遲時間。
? Time per request:每個請求的時間
? No. of failed requests:失敗請求數。
? Requests per second: 每秒請求量
ab 的最大問題是它不提供控制每秒發起請求量,因此我們不得不調整 -c 並發級別以獲得所需的每秒鐘請求數,並導致很多後文提到的問題和錯誤。
實現haproxy301域名跳轉:
1、redirect prefix http://oldboy.blog.51.com code 301 if www.9888.cn #當訪問www.9888.cn時跳轉至http://oldboy.blog.51.com
實現haproxy基於URL地址目錄做7層跳轉
比如根據目錄進行過濾轉發:
1、acl oldboy_java path_beg /java/
2、acl oldboy_php path_beg /php/
3、use_backend webserver if oldboy_java #如果是java就找webserver這個池
4、use_backend webserver if oldboy_php
實現haproxy基於擴展名做7層跳轉:
1、acl oldboy_pic path_end .gif .png .jpg .css .js
2、use_backend nginxpools if olboy_static or oldboy_pic
實現haproxy基於user_agent做7層跳轉
1、acl iphone_users hdr_sub(user-agent) -i iphone
2、redirect prefix http://www.51cto.com if iphone users
3、acl android_users hdr_sub(user-agent) -i android
4、redirect prefix http://www.baidu.com if android_users
實現haproxy基於ip和端口過濾
1、acl valid_ip src 192.168.1.0/24
2、block if !valid_ip #如果不符合valid_ip的規則就block拒絕掉
讓haproxy錯誤頁面優雅的顯示
errorfile 403 /tec/haproxy/errorfiles/403forbild.html
基於HTTP的直接IP URL方式的健康檢查:
1.>第一種HEAD配置方法option httpchk HEAD /check.html HTTP/1.0 這種檢測方式就相當於通過curl -i http://127.0.0.1/check.html 或者 wget http://127.0.0.1/check.html訪問地址。 **check.html文件必須在網站根目錄下創建 健康檢查的頻率、時間等參數: maxconn 控制節點的並發連接的 weight 12 權重,權重越大,請求越多2.>第二種GET配置方式
GET後端server的web頁面
option httpchk GET /index.html HTTP/1.0
backup 和allbackups參數:
server web1 10.10.100.66:80 check inter 2000 fall 3 weight 30
server web2 10.10.100.67:80 check inter 2000 fall 3 weight 30
server web3 10.10.100.68:80 check inter 2000 fall 3 weight 30 backup當web1和web2服務停止後,web3再提供服務,這樣可以達到高可用的目的
option allbackups
server web1 10.10.100.66:80 check inter 2000 fall 3 weight 30
server web2 10.10.100.67:80 check inter 2000 fall 3 weight 30
server web3 10.10.100.68:80 check inter 2000 fall 3 weight 30 backup
server web4 10.10.100.69:80 check inter 2000 fall 3 weight 30 backup加上 option allbackups後,當web1和web2掛掉後,web3和web4都啟動起來提供服務,不加allbackups則只有一臺提供服務.
haproxy下的RS無法記錄客戶端真實ip的問題
在haproxy配置文件裏加入如下參數:
listen www
option forwardfor 提示:參數最好放在listen www裏面 然後在nginx日誌格式中加"$http_x_forwarded_for"
關於haproxy日誌輸出的問題:
CentoS6.5下HAProxy日誌配置詳解:
syslog這個服務,在Centos5.x中的目錄為:/etc/init.d/syslog
而到了Centos6.x中變成了:/etc/init.d/rsyslog
在配置前,我們先來了解下日誌的level: local0~local7 16~23保留為本地使用
emerg 0 系統不可用
alert 1 必須馬上采取行動的事件
crit 2 關鍵的事件
err 3 錯誤事件
warning 4 警告事件
notice 5 普通但重要的事件
info 6 有用的信息
debug 7 調試信息
vim haproxy.conf(在default處添加如下信息)
########################################
defaults
log global
option httplog
log 127.0.0.1 local3
########################################
vim /etc/rsyslog.conf(添加如下內容)
local3.* /var/log/haproxy.log
vim /etc/sysconfig/rsyslog
把SYSLOGD_OPTIONS="-m 0"
改成 SYSLOGD_OPTIONS="-r -m 0"
相關解釋說明:
-r: 打開接受外來日誌消息的功能,其監控514 UDP端口;
-x: 關閉自動解析對方日誌服務器的FQDN信息,這能避免DNS不完整所帶來的麻煩;
-m: 修改syslog的內部mark消息寫入間隔時間(0為關閉),例如240為每隔240分鐘寫入一次"--MARK--"信息;
-h: 默認情況下,syslog不會發送從遠端接受過來的消息到其他主機,而使用該選項,則把該開關打開,所有接受到的信息都可根據syslog.conf中定義的@主機轉發過去.
配置完畢後關閉sellinux然後重啟rsyslog和haproxy 即可.
/etc/init.d/rsyslog restart
haproxy實現負載均衡的方式:
haproxy + heartbeat
haproxy + keepalive
haproxy 的配置文件由兩部分組成:全局設定和對代理的設定,共分為五段:global,defaults,frontend,backend,listen
1.global: (全局配置主要用於設定義全局參數,屬於進程級的配置,通常和操作系統配置有關)
2.default : (配置默認參數,這些參數可以被用到frontend,backend,Listen組件)
在此部分中設置的參數值,默認會自動引用到下面的frontend、backend、listen部分中,因引,某些參數屬於公用的配置,只需要在defaults部分添加一次即可。而如果frontend、backend、listen部分也配置了與defaults部分一樣的參數,Defaults部分參數對應的值自動被覆蓋。
3.frontend:( 接收請求的前端虛擬節點,Frontend可以更加規則直接指定具體使用後端的backend)
frontend是在haproxy 1.3版本以後才引入的一個組件,同時引入的還有backend組件。通過引入這些組件,在很大程度上簡化了haproxy配置文件的復雜性。forntend可以根據ACL規則直接指定要使用的後端backend
4.backend : (後端服務集群的配置,真實服務器,一個Backend對應一個或者多個實體服務器)
在HAProxy1.3版本之前,HAProxy的所有配置選項都在這個部分中設置。為了保持兼容性,haproxy新的版本依然保留了listen組件配置試。兩種配置方式任選一中
5.Listen : (Fronted和backend的組合體) 比如haproxy實例狀態監控部分配置
global部分配置說明
通常主要定義全局配置主要用於設定義全局參數,屬於進程級的配置,通常和操作系統配置有關。
global
log 127.0.0.1 local3 #定義haproxy日誌輸出設置
log 127.0.0.1 local1 notice
#log loghost local0 info #定義haproxy 日誌級別
ulimit-n 82000 #設置每個進程的可用的最大文件描述符
maxconn 20480 #默認最大連接數
chroot /usr/local/haproxy #chroot運行路徑
uid 99 #運行haproxy 用戶 UID
gid 99 #運行haproxy 用戶組gid
daemon #以後臺形式運行harpoxy
nbproc 1 #設置進程數量
pidfile /usr/local/haproxy/run/haproxy.pid #haproxy 進程PID文件
#debug #haproxy調試級別,建議只在開啟單進程的時候調試
#quiet
log:全局的日誌配置,local0是日誌輸出設置,info表示日誌級別(err,waning,info,debug);
maxconn:設定每個HAProxy進程可接受的最大並發連接數,此選項等同於linux命令選項”ulimit -n”;
chroot:修改haproxy的工作目錄至指定的目錄並在放棄權限之前執行chroot()操作,可以提升haproxy的安全級別,不過需要註意的是要確保指定的目錄為空目錄且任何用戶均不能有寫權限;
daemon:讓haproxy以守護進程的方式工作於後臺,其等同於“-D”選項的功能,當然,也可以在命令行中以“-db”選項將其禁用;
nbproc:指定啟動的haproxy進程個數,只能用於守護進程模式的haproxy;默認只啟動一個進程,鑒於調試困難等多方面的原因,一般只在單進程僅能打開少數文件描述符的場景中才使用多進程模式;
pidfile:將haproxy的進程寫入pid文件;
ulimit-n:設定每進程所能夠打開的最大文件描述符數目,默認情況下其會自動進行計算,因此不推薦修改此選項;
stats socket <path>定義統計信息保存位置;
如要設置haproxy的日誌內容,可參考以下配置:
capture request header Host len 40
capture request header Content-Length len 10
capture request header Referer len 200
capture response header Server len 40
capture response header Content-Length len 10
capture response header Cache-Control len 8
defaults部分配置說明用於設置配置默認參數,這些參數可以被用到frontend,backend,Listen組件;
此部分中設置的參數值,默認會自動引用到下面的frontend、backend、listen部分中,因引,某些參數屬於公用的配置,只需要在defaults部分添加一次即可。而如果frontend、backend、listen部分也配置了與defaults部分一樣的參 數,Defaults部分參數對應的值自動被覆蓋;
defaults
log global #引入global定義的日誌格式
mode http #所處理的類別(7層代理http,4層代理tcp)
maxconn 50000 #最大連接數
option httplog #日誌類別為http日誌格式
option httpclose #每次請求完畢後主動關閉http通道
option dontlognull #不記錄健康檢查日誌信息
option forwardfor #如果後端服務器需要獲得客戶端的真實ip,需要配置的參數,
可以從http header 中獲取客戶端的IP
retries 3 #3次連接失敗就認為服務器不可用,也可以通過後面設置
option redispatch #《---上述選項意思是指serverID 對應的服務器掛掉後,強制定向到其他健康的服務器, 當使用了 cookie時,
haproxy將會將其請求的後端服務器的serverID插入到cookie中,以保證會話的SESSION持久性;而此時,如果
後端的服務器宕掉了,但是客戶端的cookie是不會刷新的,如果設置此參數,將會將客戶的請求強制定向到另外一個
後端server上,以保證服務的正常---》
stats refresh 30 #設置統計頁面刷新時間間隔
option abortonclose #當服務器負載很高的時候,自動結束掉當前隊列處理比較久的連接
balance roundrobin #設置默認負載均衡方式,輪詢方式
#balance source #設置默認負載均衡方式,類似於nginx的ip_hash
#contimeout 5000 #設置連接超時時間
#clitimeout 50000 #設置客戶端超時時間
#srvtimeout 50000 #設置服務器超時時間
timeout http-request 10s #默認http請求超時時間
timeout queue 1m #默認隊列超時時間
timeout connect 10s #默認連接超時時間
timeout client 1m #默認客戶端超時時間
timeout server 1m #默認服務器超時時間
timeout http-keep-alive 10s #默認持久連接超時時間
timeout check 10s #設置心跳檢查超時時間mode http:設置haproxy的運行模式,有三種{http|tcp|health}。註意:如果haproxy中還要使用4層的應用(mode tcp)的話,不建議在此定義haproxy的運行模式。
設置HAProxy實例默認的運行模式有tcp、http、health三種可選:
tcp模式:在此模式下,客戶端和服務器端之前將建立一個全雙工的連接,不會對七層報文做任何檢查,默認為tcp模式,經常用於SSL、SSH、SMTP等應用。
http模式:在此模式下,客戶端請求在轉發至後端服務器之前將會被深度分板,所有不與RFC格式兼容的請求都會被拒絕。
health:已基本不用了。
log global:設置日誌繼承全局配置段的設置。
option httplog:表示開始打開記錄http請求的日誌功能。
option dontlognull:如果產生了一個空連接,那這個空連接的日誌將不會記錄。
option http-server-close:打開http協議中服務器端關閉功能,使得支持長連接,使得會話可以被重用,使得每一個日誌記錄都會被記錄。
option forwardfor except 127.0.0.0/8:如果上遊服務器上的應用程序想記錄客戶端的真實IP地址,haproxy會把客戶端的IP信息發送給上遊服務器,在HTTP請求中添加”X-Forwarded-For”字段,但當是haproxy自身的健康檢測機制去訪問上遊服務器時是不應該把這樣的訪問日誌記錄到日誌中的,所以用except來排除127.0.0.0,即haproxy身。
option redispatch:當與上遊服務器的會話失敗(服務器故障或其他原因)時,把會話重新分發到其他健康的服務器上,當原來故障的服務器恢復時,會話又被定向到已恢復的服務器上。還可以用”retries”關鍵字來設定在判定會話失敗時的嘗試連接的次數。
retries 3:向上遊服務器嘗試連接的最大次數,超過此值就認為後端服務器不可用。
option abortonclose:當haproxy負載很高時,自動結束掉當前隊列處理比較久的鏈接。
timout http-request 10s:客戶端發送http請求的超時時間。
timeout queue 1m:當上遊服務器在高負載響應haproxy時,會把haproxy發送來的請求放進一個隊列中,timeout queue定義放入這個隊列的超時時間。
timeout connect 5s:haproxy與後端服務器連接超時時間,如果在同一個局域網可設置較小的時間。
timeout client 1m:定義客戶端與haproxy連接後,數據傳輸完畢,不再有數據傳輸,即非活動連接的超時時間。
timeout server 1m:定義haproxy與上遊服務器非活動連接的超時時間。
timeout http-keep-alive 10s:設置新的http請求連接建立的最大超時時間,時間較短時可以盡快釋放出資源,節約資源。
timeout check 10s:健康檢測的時間的最大超時時間。
maxconn 3000:最大並發連接數。
contimeout 5000:設置成功連接到一臺服務器的最長等待時間,默認單位是毫秒,新版本的haproxy使用timeout connect替代,該參數向後兼容。
clitimeout 3000:設置連接客戶端發送數據時的成功連接最長等待時間,默認單位是毫秒,新版本haproxy使用timeout client替代。該參數向後兼容。
srvtimeout 3000:設置服務器端回應客戶度數據發送的最長等待時間,默認單位是毫秒,新版本haproxy使用timeout server替代。該參數向後兼容。
balance roundrobin:設置負載算法為:輪詢算法rr
balance :用來定義負載均衡算法
1.roundrobin:基於權重進行的輪叫算法,在服務器的性能分布經較均勻時這是一種最公平的,最合量的算法。
2.static-rr:也是基於權重時行輪叫的算法,不過此算法為靜態方法,在運行時調整其服務權重不會生效。
3.source:是基於請求源IP的算法,此算法對請求的源IP時行hash運算,然後將結果與後端服務器的權理總數相除後轉發至某臺匹配的後端服務器,這種方法可以使用一個客戶端IP的請求始終轉發到特定的後端服務器。
4.leastconn:此算法會將新的連接請求轉發到具有最少連接數目的後端服務器。在會話時間較長的場景中推薦使用此算法。例如數據庫負載均衡等。此算法不適合會話較短的環境,如基於http的應用。
5.uri:此算法會對部分或整個URI進行hash運算,再經過與服務器的總權重要除,最後轉發到某臺匹配的後端服務器上。
6.uri_param:此算法會椐據URL路徑中的參數時行轉發,這樣可以保證在後端真實服務器數量不變時,同一個用戶的請求始終分發到同一臺機器上。
7.hdr:此算法根據httpd頭時行轉發,如果指定的httpd頭名稱不存在,則使用roundrobin算法進行策略轉發。
8.rdp-cookie(name):示根據據cookie(name)來鎖定並哈希每一次TCP請求。
frontend部分配置說明
frontend是在haproxy 1.3版本以後才引入的一個組件,同時引入的還有backend組件。通過引入這些組件,在很大程度上簡化了haproxy配置文件的復雜性。frontend根據任意 HTTP請求頭內容做ACL規則匹配,然後把請求定向到相關的backend
frontend http_80_in
bind 0.0.0.0:80 #設置監聽端口,即haproxy提供的web服務端口,和lvs的vip 類似
mode http #http 的7層模式
log global #應用全局的日誌設置
option httplog #啟用http的log
option httpclose #每次請求完畢後主動關閉http通道,HAproxy不支持keep-alive模式
option forwardfor #如果後端服務器需要獲得客戶端的真實IP需要配置此參數,將可以從HttpHeader中獲得客戶端IP
default_backend wwwpool #設置請求默認轉發的後端服務池
frontend http_80_in:定義一個名為http_80_in的frontend。
bind 0.0.0.0:80:定義haproxy前端部分監聽的端口。
mode http:定義為http模式。
log global:繼承global中log的定義。
option forwardfor:使後端server獲取到客戶端的真實IP。
backend部分配置說明
用來定義後端服務集群的配置,真實服務器,一個Backend對應一個或者多個實體服務器
backend wwwpool #定義wwwpool服務器組。
mode http #http的7層模式
option redispatch
option abortonclose
balance source #負載均衡的方式,源哈希算法
cookie SERVERID #允許插入serverid到cookie中,serverid後面可以定義
option httpchk GET /test.html #心跳檢測
server web1 10.1.1.2:80 cookie 2 weight 3 check inter 2000 rise 2 fall 3 maxconn 8
listen部分配置說明
常常用於狀態頁面監控,以及後端server檢查,是Fronted和backend的組合體。
如下為haproxy訪問狀態監控頁面配置:
listen admin_status #Frontend和Backend的組合體,監控組的名稱,按需自定義名稱
bind 0.0.0.0:8888 #監聽端口
mode http #http的7層模式
log 127.0.0.1 local3 err #錯誤日誌記錄
stats refresh 5s #每隔5秒自動刷新監控頁面
stats uri /admin?stats #監控頁面的url訪問路徑
stats realm itnihao\ welcome #監控頁面的提示信息
stats auth admin:admin #監控頁面的用戶和密碼admin,可以設置多個用戶名
stats auth admin1:admin1 #監控頁面的用戶和密碼admin1
stats hide-version #隱藏統計頁面上的HAproxy版本信息
stats admin if TRUE #手工啟用/禁用,後端服務器(haproxy-1.4.9以後版本)
haproxy日誌中的 CD SD問題:增大下邊兩個配置的時間;
timeout client 8h
timeout server 8h
碰到with 或者別的狀態時修改
timeout http-keep-alive 10s
timeout check 10s
timeout http-request 10s
timeout queue 1m
timeout connect 10s
高並發Haproxy壓力測試與優化之道