
【python 爬蟲】BeautifulSoup4 庫的介紹使用
有部分內容為北理嵩天老師的爬蟲教程的個人學習筆記,結合其他部落格整理學習。
前言:資訊標記形式
html是將聲音、影象、音訊嵌入到文字中,是Internet上的主要資訊組織、傳遞形式,通過預定義的標籤< >…</ >將不同型別的資訊組織起來。國際上標準的資訊標記形式有XML JSON YAML 三種。
XML 擴充套件標記語言
標籤形式類似html,應用在Internet主流資訊互動和傳遞。
有內容有一對兒標籤加內容屬性< name>…< /name>,無內容直接省略用一對肩括號表示< name />。可加註釋。
例項:
< title>標題名< /title>
< body>數值為多少< /body>
JSON
JavaScript面向物件屬性。用在程式對介面處理的地方,經過傳輸後作為程式碼的一部分,並被程式直接執行,才可以發揮它資料型別的意義和優勢。
屬於有資料型別的鍵(key)值(value)對。
“name”:“王老五”
一個鍵可能對應多個值,用 [ ] 表示
“name” : [“王老五”,“王老六”]
鍵值對可以巢狀使用。把鍵值對放進新鍵值對的值部分,用 { } 表示。
“key” : { “zikey” : [ “w” , “z”] }
採用有型別的鍵值對,裡面的值是數字型別時就不用加 " " 符號
例項:

YAML
無 ‘’ ‘’ 引號的鍵值對形式,一般用在系統配置檔案,有註釋,簡單易讀。
用 縮排 表示 所屬關係
name :
value
key:
zikey : value
用 - 減號表示 value 值的並列關係。
用 # 表示註釋
name: #comment
-王老五
-王老六

提取網頁中資訊標記的幾種方式
1、完全解析標記形式,再去按標記提取關鍵資訊。(準確、繁瑣、速度慢)
2、無視標記形式,直接進行搜尋。(過程簡單,快、提取結果準確性不好)
3、兩種方法結合。
例項:尋找一個頁面內包含的所有url連結。
#BS4openfile.py
from bs4 import BeautifulSoup
html = '''
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
'''
soup = BeautifulSoup(html,"html.parser")
for link in soup.find_all('a'):
print(link.get('href'))
>>>
http://www.icourse163.org/course/BIT-268001
http://www.icourse163.org/course/BIT-1001870001
1、安裝
該第三方庫可以對html 和 xml 頁面進行解析,提取相關資訊。
管理員許可權啟動cmd命令,使用pip 安裝BeautifulSoup4
pip install BeautifulSoup4
獲取一個html頁面,並對它進行beautifulsoup解析。
import requests
from bs4 import BeautifulSoup
#呼叫時將BeautifulSoup4庫縮寫為bs4進行呼叫,若為pycharm環境需要再安裝一下bs4包
r = requests.get("http://python123.io/ws/demo.html")
print(r.text)
demo = r.text
soup = BeautifulSoup(demo, "html.parser") #後面引數為直譯器型別,需要其他時需單獨安裝
#soup = BeautifulSoup(open("檔案.html"), "html.parser") #開啟儲存在本地的html檔案形式
print(soup.prettify()) #prettify()方法為文字內容增加換行符,屬於一種格式化的輸出方法
其他解析器:

2、基本元素
html檔案中的內容由肩括號和具體的標籤以及標籤屬性構成,屬性由鍵值對錶示。
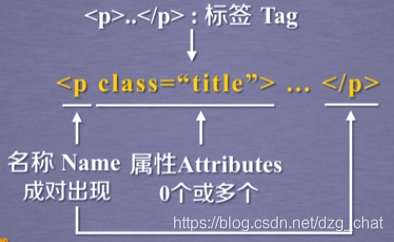
BS4庫的基本元素:

以一段html程式碼為例,我們開啟上面出現的網址:https://python123.io/ws/demo.html ,右鍵檢視原始碼:
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>
</body></html>
2.1 Tag標籤
以指定的解析器開啟上面的網頁原始碼:
#BS4openfile.py
from bs4 import BeautifulSoup
html = '''
那段原始碼
'''
soup = BeautifulSoup(html,"html.parser")
print(soup.prettify()) #格式化輸出
輸出顯示:
========== RESTART: D:/MathElectric/python/BS4openhtml.py ===============
<html>
<head>
<title>
This is a python demo page
</title>
</head>
<body>
<p class="title">
<b>
The demo python introduces several python courses.
</b>
</p>
<p class="course">
Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">
Basic Python
</a>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">
Advanced Python
</a>
.
</p>
</body>
</html>
>>>
這裡面 < html>… < /html>、< body>…< /body>、< p>…< /p>、< a>…< /a>都是標籤。
2.2 標籤名
列印顯示html的指定標籤時:
print(soup.title) ##顯示全部標籤
>>> <title>This is a python demo page</title>
print(soup.tag)
print(soup.tag.name) #只獲取標籤名
print(soup.title.name)
>>> title
標籤存在一級一級包含關係,如title標籤就在head標籤內,head標籤就是title標籤的父標籤。獲取某標籤的父標籤及其父標籤的名字:
print(soup.title.parent)
>>>
<head><title>This is a python demo page</title></head> #注意顯示的是整個標籤全部
print(soup.title.parent.name) #僅顯示標籤名
>>>
head
2.3 標籤屬性
標籤的屬性:
print(soup.p.attrs) #返回一個 字典 包含所有屬性
>>>
{'class': ['title']}
print(soup.p.attrs['class']) #也可以單獨取某個屬性,還可以對屬性進行修改、刪除
>>>
['title']
soup.p.attrs['class'] = "NewClass"
2.4 標籤內容string
標籤的string 屬性:NavigableString , 顯示標籤的內容
print(soup.title.string) #顯示標籤的具體內容
>>>
This is a python demo page
2.5 標籤的註釋
標籤的comment註釋:
from bs4 import BeautifulSoup
newsoup = BeautifulSoup("<b><!--This is a comment--></b><p>This is not a comment</p>", "html.parser")
newsoup.b.string
》
'This is a comment'
newsoup.p.string
》
'This is not a comment'
type(newsoup.b.string)
》
<class 'bs4.element.Comment'>
type(newsoup.p.string)
》
<class 'bs4.element.NavigableString'>
兩種不同型別的標籤在列印的時候並沒有標註說明,去掉了註釋的 !---- 符號,但是欄位的資料型別是不同的,需要注意。
3、HTML 的資訊遍歷
這是一種樹形結構的文字資訊。
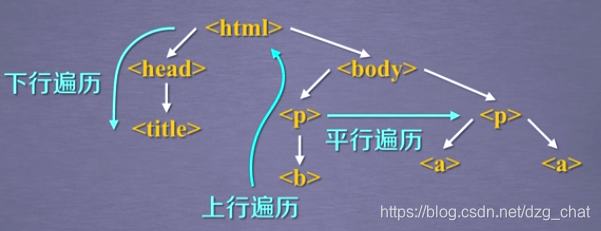
3.1、上行遍歷
parent 屬性和 parents 屬性
parent 是當前節點的父標籤,parents 是所有的父輩們的標籤。
列印parent是輸出標籤,parents是一個需要遍歷輸出的類
遍歷 p 標籤的父輩們,並顯示標籤名:
for parent in soup.p.parents:
if parent is None:
print(parent)
else:
print(parent.name)
>>>
body
html
[document]
html 是頂級標籤,父標籤為自己,soup 的先輩不存在.name資訊
3.2、下行遍歷
contents 屬性
子節點的列表,將標籤的所有 子 節點存入 列表。包含換行符等。
print(soup.body.contents)
>>>
['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
print(len(soup.body.contents)) #獲取子節點的數量
>>>
5
因為是列表型別,所以列表的常規操作可以使用。
children 屬性。
子節點的遍歷操作:因為物件不是一個列表,所以不能直接列印輸出。
for child in soup.body.children:
print(child)
print("**")
print("===================")
descendants 屬性
所有的子孫節點進行遍歷,和contents與children不同的地方在於上面兩個屬性只是與body直接相關的,而descendants是所有的子孫節點都包含。
for desc in soup.body.descendants:
print(desc)
print("*****")
3.3、平行遍歷
平行遍歷的前提是所有的節點在同一個父親節點之下,否則不能構成平行遍歷關係。
next_sibling 屬性
返回按照html文字順序的下一個平行節點(標籤)
print(soup.a.next_sibling)
print(soup.a.next_sibling.next_sibling)
>>>
and
<a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>
previous_sibling 屬性
上一個節點。
next_siblings 屬性
迭代型別,需遍歷,按照文字順序後續的所有。
previous_siblings 屬性
迭代型別,所有前續的平行節點。
4、基於BS4庫的常用Html內容查詢方法
在soup變數中查詢相關資訊,
通常將<標籤>.find__all(…)簡寫為<標籤>(…)
將soup.find_all(…)簡寫為 soup(…)
4.1、典型方法詳細介紹
<>.find_all(name,attrs,recursive,string,**kwargs)
4.1.1 name引數
根據標籤名稱檢索相應字串,返回包含被檢索標籤的所有標籤列表
print(soup.find_all('a'))
》》
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
也可以同時查詢顯示多種標籤 a 和 b 及c :
soup.find_all(['a','b','c'])
當 name 引數為True 時,顯示soup所有標籤的資訊。
for tag in soup.find_all(True):
print(tag.name)
》》
html
head
title
body
p
b
p
a
a
結合正則表示式(Re)庫只查詢顯示包含某個字母或單次的所有標籤
import re
soup.find_all(re.compile(‘b’))
只查詢和 b 相關的,輸出為b 和 body的標籤資訊。
4.1.2、attrs
表示對標籤的屬性進行字串檢索,可以檢視帶有某個屬性的標籤。
soup.find_all('p','course')
#查詢返回 p 標籤內的包含 course 屬性資訊的標籤
查詢確定的內容資訊:注意輸入時不使用精確查詢會匹配不到
print(soup.find_all(id='link1')) #精確
print('*****')
print(soup.find_all(id='link')) #不精確
》》
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]
*****#上、下為精確和不精確匹配的輸出
[]
想不精確,查詢帶某個關鍵詞的時候使用正則表示式
soup.find_all(id=re.compile('link'))
》》
******
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
4.1.3 recursive
表示是否對子孫全部節點檢索,預設為True,若只對當前節點的 子節點搜尋,則更改為False
對比一下兩種表示式的輸出差別:
soup.find_all('a') #全部子孫節點
soup.find_all('a',recursive=False) #只對子節點
》》
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
[]
4.1.4、 string
對標籤中間的字串域<>…<>進行檢索,檢索時精確輸入,不精確輸入時使用正則表示式。
print(soup.find_all(string = re.compile('pyth'))) #正則模糊檢索,返回獵豹
》》
['This is a python demo page', 'The demo python introduces several python courses.']
4.2 其他常用方法
引數屬性和find_all() 一致。
注意使用的時候是和標籤相關的。

使用時應該是具體的哪個標籤,再去找它的子孫輩或者先輩:
print(soup.a.find_parent('p'))
print('****')
print(soup.a.find_parents('p'))
如果直接是soup.find:
print(soup.find_parent('a'))
因為soup是頂級,可能返回的都是NONE 或者空 [ ]