
【python爬蟲】BeautifulSoup庫的選擇器select()方法
阿新 • • 發佈:2019-01-23
一般使用BeautififulSoup解析得到的Soup文件可以使用
find_all()、find()、select()方法定位所需要的元素。find_all()是獲得list列表、find()是獲得map一條資料。select()是根據選擇器可以獲得多條也可以獲得單條資料。一般最常用的是find_all()和find()兩個引數。
select()方法的使用
- 從頁面中自定義獲得選擇器:
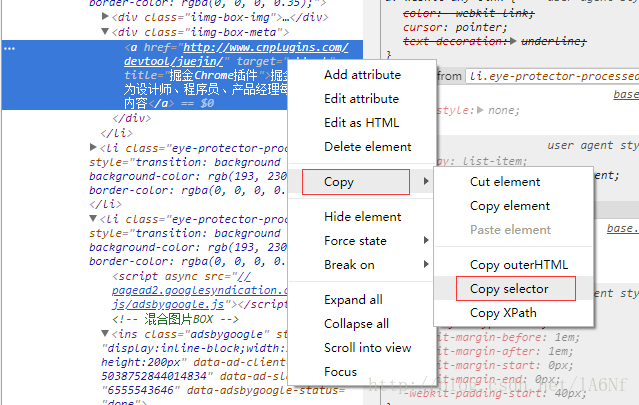
F12中選擇了目標element之後,右鍵—Copy—Copy selector 如圖:
nth-child在Python中執行會報錯,需要改為nth-of-type:
如果所複製的選擇器中包含nth-child,則需要改為nth-of-type,否則會報錯。- demo:
import requests
from bs4 import BeautifulSoup
url = 'http://www.cnplugins.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
res = requests.get(url,headers = headers) #get方法中加入請求頭