
Strom核心元件與程式設計模型
1.Strom介紹
Storm用來實時處理資料,特點:低延遲、高可用、分散式、可擴充套件、資料不丟失。提供簡單容易理解的介面,便於開發
2.strom與hadoop的區別
Storm用於實時計算,Hadoop用於離線計算。
Storm處理的資料儲存在記憶體中,源源不斷;Hadoop處理的資料儲存在檔案系統中,一批一批。
Storm的資料通過網路傳輸進來;Hadoop的資料儲存在磁碟中。
Storm與Hadoop的程式設計模型相似
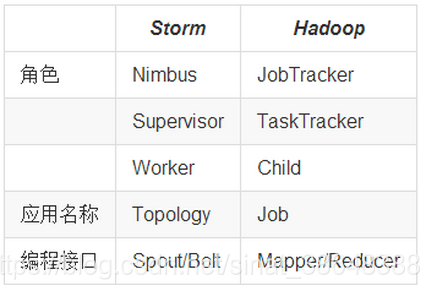
Job:任務名稱
JobTracker:專案經理
TaskTracker:開發組長、產品經理
Child:負責開發的人員
Mapper/Reduce:開發人員中的兩種角色,一種是伺服器開發、一種是客戶端開發
Topology:任務名稱
Nimbus:專案經理
Supervisor:開組長、產品經理
Worker:開人員
Spout/Bolt:開人員中的兩種角色,一種是伺服器開發、一種是客戶端開發
3.Storm核心元件
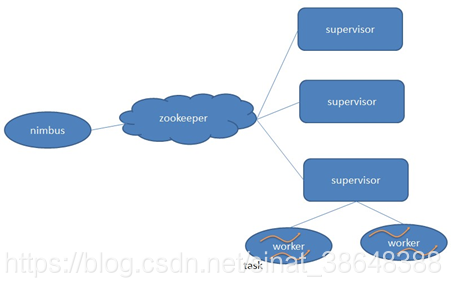
Nimbus:負責資源分配和任務排程。
Supervisor:負責接受nimbus分配的任務,啟動和停止屬於自己管理的worker程序。—通過配置檔案設定當前supervisor上啟動多少個worker。
Worker:執行具體處理元件邏輯的程序。Worker執行的任務型別只有兩種,一種是Spout任務,一種是Bolt任務。
Task:worker中每一個spout/bolt的執行緒稱為一個task. 在storm0.8之後,task不再與物理執行緒對應,不同spout/bolt的task可能會共享一個物理執行緒,該執行緒稱為executor。
4.Storm程式設計模型
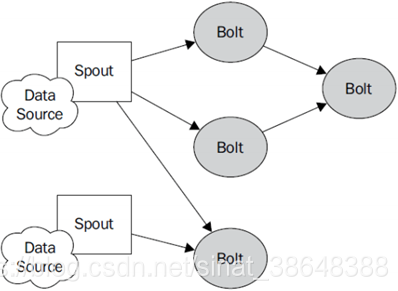
Topology:Storm中執行的一個實時應用程式的名稱。(拓撲)
Spout:在一個topology中獲取源資料流的元件。
通常情況下spout會從外部資料來源中讀取資料,然後轉換為topology內部的源資料。
Bolt:接受資料然後執行處理的元件,使用者可以在其中執行自己想要的操作。
Tuple:一次訊息傳遞的基本單元,理解為一組訊息就是一個Tuple。
Stream:表示資料的流向。