物聯網技術部第二次軟體培訓總結
物聯網技術部第二次軟體培訓總結
文章目錄
一、結構體
1.定義結構
為了定義結構,您必須使用 struct 語句。struct 語句定義了一個包含多個成員的新的資料型別, struct 語句的格式如下:
struct tag {
member-list
member-list
member-list
...
} variable-list ;
tag 是結構體標籤。
member-list 是標準的變數定義,比如 int i ; 或者 float f ; 或者其他有效的變數定義。
variable-list 結構變數,定義在結構的末尾,最後一個分號之前,您可以指定一個或多個結構變數。下面是宣告 Book 結構的方式:
struct Books{ 在一般情況下,tag、member-list、variable-list 這 3 部分至少要出現 2 個。以下為例項:

• 在上面的宣告中,第一個和第二宣告被編譯器當作兩個完全不同的型別,即使他們的成員列表是一樣的,如果令 t3=&s1,則是非法的。
• 結構體的成員可以包含其他結構體,也可以包含指向自己結構體型別的指標,而通常這種指標的應用是為了實現一些更高階的資料結構如連結串列和樹等。

2.結構體變數的初始化
和其它型別變數一樣,對結構體變數可以在定義時指定初始值


3.訪問結構成員
為了訪問結構的成員,我們使用成員訪問運算子(.)。成員訪問運算子是結構變數名稱和我們要訪問的結構成員之間的一個句號。您可以使用 struct 關鍵字來定義結構型別的變數。下面的例項演示了結構的用法:


4.結構作為函式引數
您可以把結構作為函式引數,傳參方式與其他型別的變數或指標類似。您可以使用上面例項中的方式來訪問結構變數:



5.指向結構的指標
您可以定義指向結構的指標,方式與定義指向其他型別的指標相似,如下所示:
struct Books *struct_pointer ;
現在,您可以在上述定義的指標變數中儲存結構變數的地址,請把 & 運算子放在結構名稱的前面,如下所示:
struct_pointer = &Book1 ;
為了使用指向該結構的指標訪問結構的成員,您必須使用 -> 運算子,如下所示:
struct_pointer -> title ;



二、時間複雜度
1.定義
什麼是時間複雜度,演算法中某個函式有n次基本操作重複執行,用T(n)表示,現在有某個輔助函式f(n),使得當n趨近於無窮大時,T(n)/f(n)的極限值為不等於零的常數,則稱f(n)是T(n)的同數量級函式。記作T(n)=O(f(n)),稱O(f(n)) 為演算法的漸進時間複雜度,簡稱時間複雜度。通俗一點講,其實所謂的時間複雜度,就是找了一個同樣曲線型別的函式f(n)來表示
這個演算法的在n不斷變大時的趨勢 。當輸入量n逐漸加大時,時間複雜性的極限情形稱為演算法的“漸近時間複雜性”。
2.簡單的時間複雜度舉例
列舉一些簡單例子的時間複雜度。
O(1)的演算法是一些運算次數為常數的演算法。例如:
temp=a;a=b;b=temp;
上面語句共三條操作,單條操作的頻度為1,即使他有成千上萬條操作,也只是個較大常數,這一類的時間複雜度為O(1)。
O(n)的演算法是一些線性演算法。例如:
sum=0;
for(i=0;i<n;i++)
sum++;
上面程式碼中第一行頻度1,第二行頻度為n,第三行頻度為n,所以f(n)=n+n+1=2n+1。所以時間複雜度O(n)。這一類演算法中操作次數和n正比線性增長。
O(logn) 一個演算法如果能在每個步驟去掉一半資料元素,如二分檢索,通常它就取 O(logn)時間。舉個栗子:
int i=1;
while (i<=n)
i=i*2;
上面程式碼設第三行的頻度是f(n), 則:2的f(n)次方<=n;f(n)<=log₂n,取最大值f(n)= log₂n,所以T(n)=O(log₂n ) 。
O(n²)(n的k次方的情況)最常見的就是平時的對陣列進行排序的各種簡單演算法都是O(n²),例如直接插入排序的演算法。
而像矩陣相乘演算法運算則是O(n³)。
舉個簡單栗子:
sum=0;
for(i=0;i<n;i++)
for(j=0;j<n;j++)
sum++;
第一行頻度1,第二行n,第三行n²,第四行n²,T(n)=2n²+n+1 =O(n²)
三、分治法(Divide and Conquer)
1.分治法的精髓:
①分–將問題分解為規模更小的子問題;
②治–將這些規模更小的子問題逐個擊破;
③合–將已解決的子問題合併,最終得出“母”問題的解;**
分治法的作用,自然是讓程式更加快速地處理問題。比如一個n的問題分解成兩個n/2的問題,並由兩個人來完成,效率就會快一些。當然單執行緒的程式的分治法,就是把n的問題剔除掉可以省略的步驟,從而提高程式執行的速度。
1.找數字
假設我們需要在1-10000裡面找一個數200,使用逐個搜尋的方法,我們會消耗200步。如果計入小數的畫,恐怕就大大超過200這個消耗了。
假如使用二分法:
• 第一步我們找到1-10000中間的那個數:5000。它大於200,所以200應該在1-4999這個區間內,這樣我們就丟掉了後5000個數。
• 第二步我們找到2500,也比200要大,200在1-2500這個區間內。
• 第三步找到1250這個數,也比200大。
• 第四步找到750。
• 第五步找到375。
• 第六步找到167,它比200要小了,說明200在167-375之間。
• 第七步找到271,它在167-271之間。
• 第八步找到219,它在167-219之間。
• 第九步找到193,它在193-219之間。
• 第十步找到206,它在193-206之間。
• 第十一步找到199,它在199-206之間。
• 第十二步找到202,它在199-202之間。
• 第十三步找到200。
2.快速排序介紹
快速排序(Quick Sort)使用分治法策略。
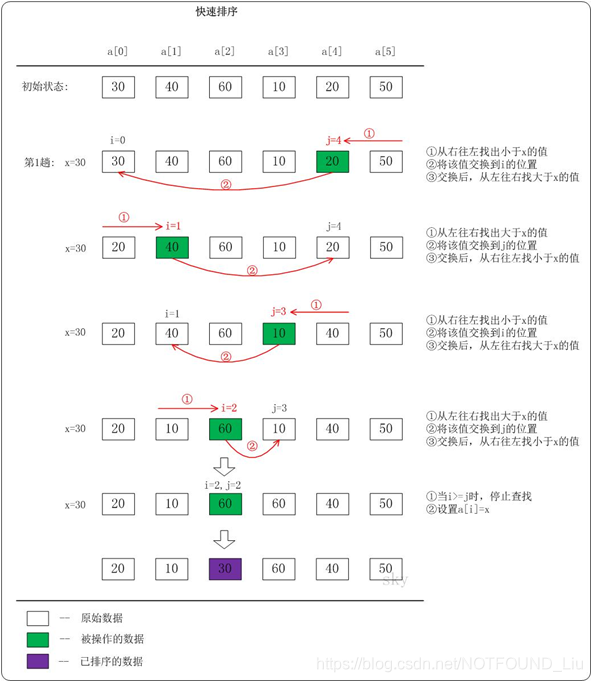
它的基本思想是:選擇一個基準數,通過一趟排序將要排序的資料分割成獨立的兩部分;其中一部分的所有資料都比另外一部分的所有資料都要小。然後,再按此方法對這兩部分資料分別進行快速排序,整個排序過程可以遞迴進行,以此達到整個資料變成有序序列。
快速排序流程:
(1) 從數列中挑出一個基準值。
(2) 將所有比基準值小的擺放在基準前面,所有比基準值大的擺在基準的後面(相同的數可以到任一邊);在這個分割槽退出之後,該基準就處於數列的中間位置。
(3) 遞迴地把"基準值前面的子數列"和"基準值後面的子數列"進行排序。

3.歸併排序介紹
將兩個的有序數列合併成一個有序數列,我們稱之為"歸併"。
歸併排序(Merge Sort)就是利用歸併思想對數列進行排序。根據具體的實現,歸併排序包括"從上往下"和"從下往上"2種方式:
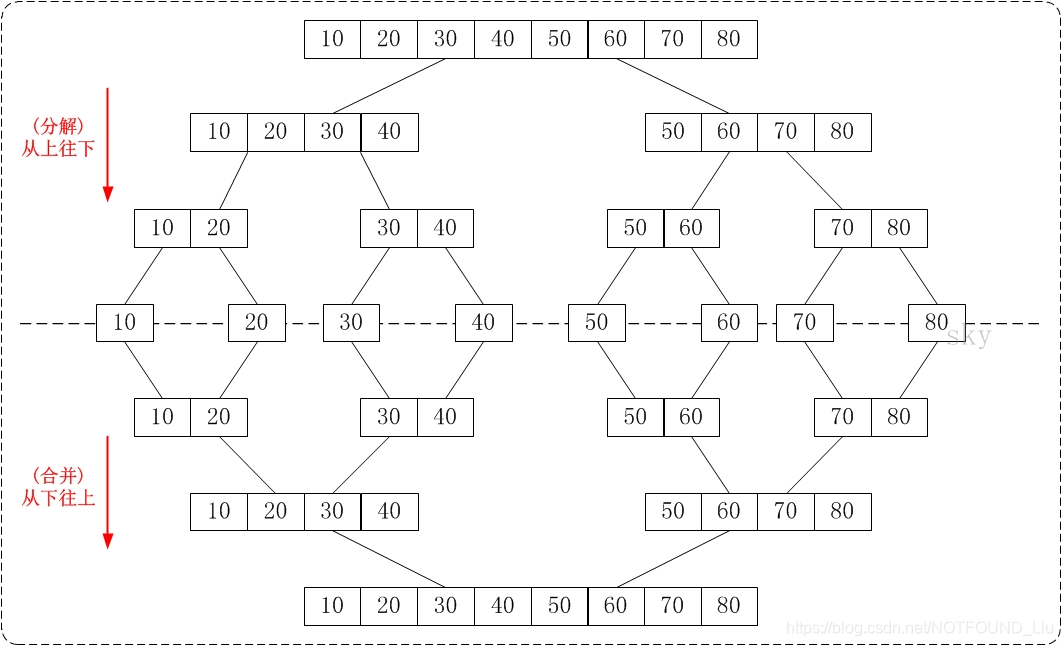
- 從下往上的歸併排序:將待排序的數列分成若干個長度為1的子數列,然後將這些數列兩兩合併;得到若干個長度為2的有序數列,再將這些數列兩兩合併;得到若干個長度為4的有序數列,再將它們兩兩合併;直接合併成一個數列為止。這樣就得到了我們想要的排序結果。(參考下面的圖片)
- 從上往下的歸併排序:它與"從下往上"在排序上是反方向的。它基本包括3步:
① 分解 – 將當前區間一分為二,即求分裂點 mid = (low + high)/2;
② 求解 – 遞迴地對兩個子區間a[low…mid] 和 a[mid+1…high]進行歸併排序。遞迴的終結條件是子區間長度為1。
③ 合併 – 將已排序的兩個子區間a[low…mid]和 a[mid+1…high]歸併為一個有序的區間a[low…high]。
歸併排序(從上往下)程式碼:


從上往下的歸併排序採用了遞迴的方式實現。它的原理非常簡單,如下圖:
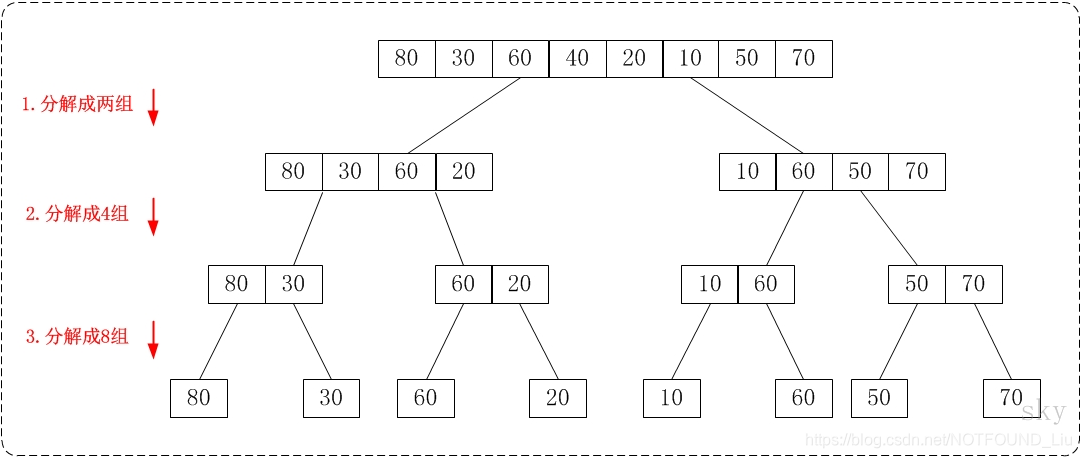
通過"從上往下的歸併排序"來對陣列{80,30,60,40,20,10,50,70}進行排序時:
① 將陣列{80,30,60,40,20,10,50,70}看作由兩個有序的子陣列{80,30,60,40}和 {20,10,50,70}組成。對兩個有序子樹組進行排序即可。
②將子陣列{80,30,60,40}看作由兩個有序的子陣列{80,30}和{60,40}組成。
將子陣列{20,10,50,70}看作由兩個有序的子陣列{20,10}和{50,70}組成。
③將子陣列{80,30}看作由兩個有序的子陣列{80}和{30}組成。
將子陣列{60,40}看作由兩個有序的子陣列{60}和{40}組成。
將子陣列{20,10}看作由兩個有序的子陣列{20}和{10}組成。
將子陣列{50,70}看作由兩個有序的子陣列{50}和{70}組成。
歸併排序(從下往上)程式碼:


從下往上的歸併排序的思想正好與"從下往上的歸併排序"相反。如下圖:
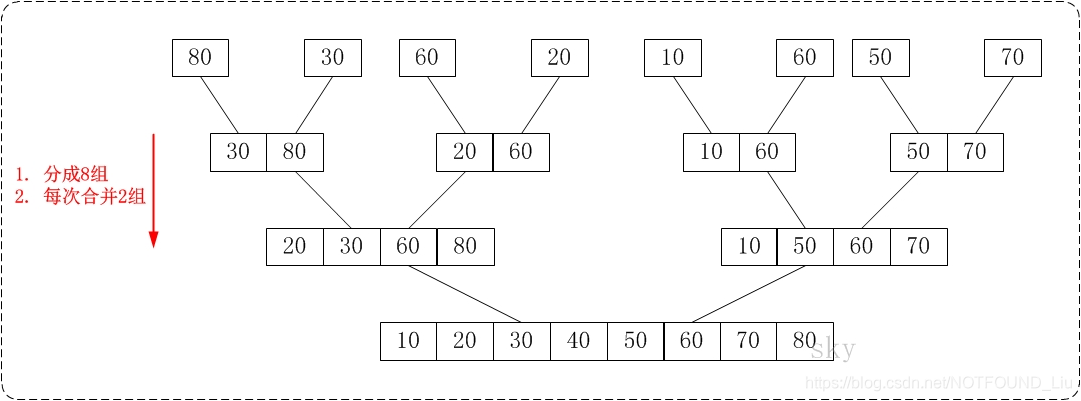
通過"從下往上的歸併排序"來對數
組{80,30,60,40,20,10,50,70}進行排序時:
- 將陣列{80,30,60,40,20,10,50,70}看作由8
個有序的子數
組{80},{30},{60},{40},{20},{10},{50}和{70}組成。 - 將這8個有序的子數列兩兩合併。得到4
個有序的子樹列{30,80},{40,60},{10,20}和{50,70}。 - 將這4個有序的子數列兩兩合併。得到2
個有序的子樹列{30,40,60,80}和{10,20,50,70}。 - 將這2個有序的子數列兩兩合併。得到1個有
序的子樹列{10,20,30,40,50,60,70,80}。
4.桶排序介紹
桶排序(Bucket Sort)的原理很簡單,它是將陣列分到有限數量的桶子裡。
假設待排序的陣列a中共有N個整數,並且已知陣列a中資料的範圍[0, MAX)。在桶排時,建立容量為MAX的桶陣列r,並將桶陣列元素都初始化為0;將容量為MAX的桶陣列中的每一個單元都看作一個"桶"。
在排序時,逐個遍歷陣列a,將陣列a的值,作為"桶陣列r"的下標。當a中資料被讀取時,就將桶的值加1。例如,讀取到陣列a[3]=5,則將r[5]的值+1。

bucketSort(a, n, max)是作用是對陣列a進行桶排序,n是陣列a的長度,max是陣列中最大元素所屬的範圍[0,max)。
假設a={8,2,3,4,3,6,6,3,9}, max=10。此時,將陣列a的所有資料都放到需要為0-9的桶中。如下圖:
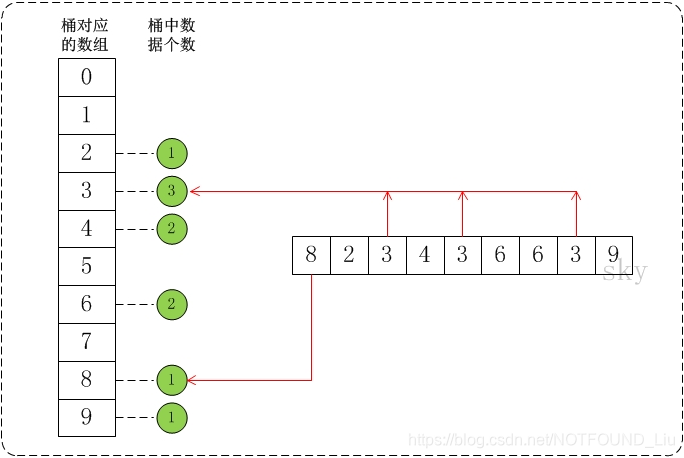
在將資料放到桶中之後,再通過一定的演算法,將桶中的資料提出出來並轉換成有序陣列。就得到我們想要的結果了。
5.基數排序介紹
基數排序(Radix Sort)是桶排序的擴充套件,它的基本思想是:將整數按位數切割成不同的數字,然後按每個位數分別比較。
具體做法是:將所有待比較數值統一為同樣的數位長度,數位較短的數前面補零。然後,從最低位開始,依次進行一次排序。這樣從最低位排序一直到最高位排序完成以後, 數列就變成一個有序序列。
基數排序圖文說明
通過基數排序對陣列{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意圖如下:
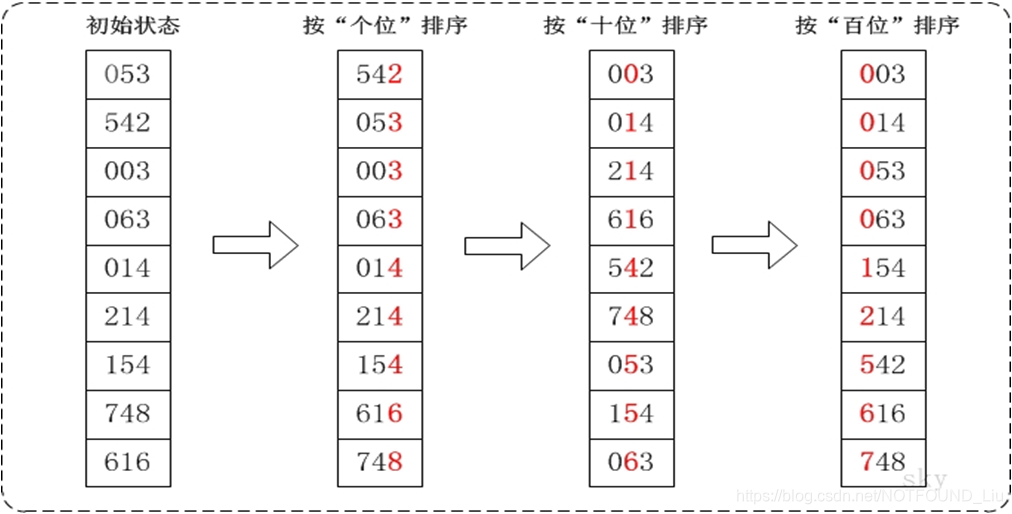



radix_sort(a, n)的作用是對陣列a進行排序。
- 首先通過get_max(a)獲取陣列a中的最大值。獲取最大值的目的是計算出陣列a的最大指數。
- 獲取到陣列a中的最大指數之後,再從指數1開始,根據位數對陣列a中的元素進行排序。排序的時候採用了桶排序。
- count_sort(a, n, exp)的作用是對陣列a按照指數exp進行排序。
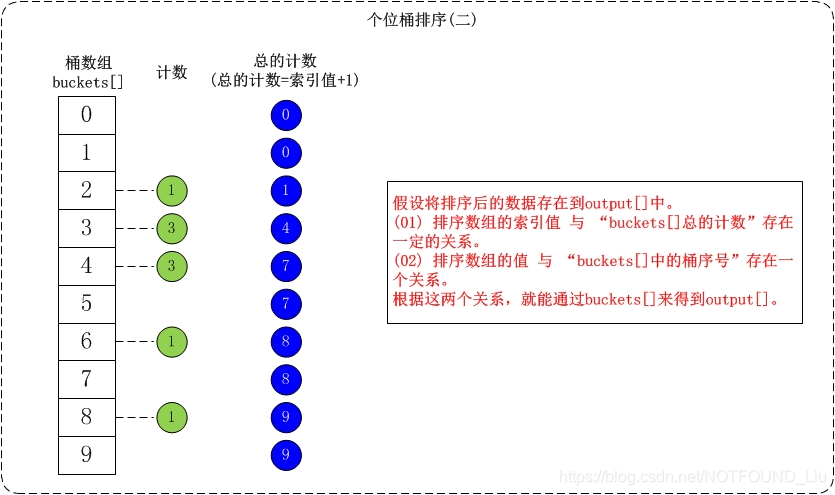
下面簡單介紹一下對陣列{53, 3, 542, 748, 14, 214, 154, 63, 616}按個位數進行排序的流程。
(01) 個位的數值範圍是[0,10)。因此,參見桶陣列buckets[],將陣列按照個位數值新增到桶中。
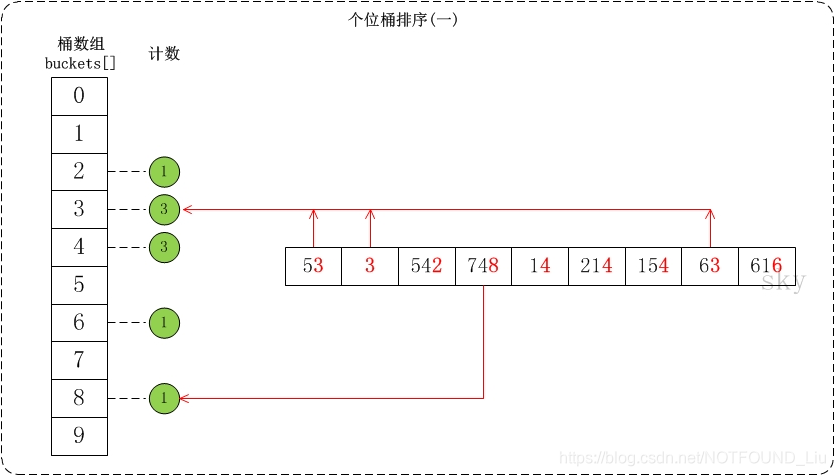
• (02) 接著是根據桶陣列buckets[]來進行排序。假設將排序後的陣列存在output[]中;找出output[]和buckets[]之間的聯絡就可以對資料進行排序了。