
HDFS HA切換後missing block問題分析
我們Hadoop平臺也從Hadoop1.2.1升級到了Hadoop2.4.0版本,當然HDFS HA 也配置到叢集中。具體的配置方法是基於cloudera 開源的zookeeper +QJM HA方案(https://issues.apache.org/jira/browse/HDFS-1623)。感恩cloudera 這樣偉大的公司,為我們提供了一個比較完美方案。小夥伴把HBase cluster從Hadoop1.2.1遷移到Hadoop2.4.0,同時驗證HDFS HA 切換是否對HBase功能產生影響。問題出現了,當我們持續往HBase寫入資料的時候並切換HA(kill active Namenode),讀出剛才寫入的資料,悲劇了,資料讀不來,HDFS web頁面出現了missing block。
接下來我們我們分析HBase 相關日誌,發現在HA 切換時寫入 hfile 檔案出現問題。ok,我們現在先驗證HDFS HA切換是否影響普通檔案寫入。怎麼驗證了?這個不難啊,我們用HDFS client程式碼持續寫入大量小檔案(10個位元組),同時進行HA切換。悲劇再次發生了,HDFS web頁面同時出現了missing block:

現在問題復現了,先興奮一把,我們先解決 HDFS HA 切換造成塊丟失的問題。解決了這個問題再繼續驗證HBase。下面先解釋一下切換過程:
- namenode2是active Namenode,我們切換的時候直接kill掉該節點;
- namenode1是standby Namenode ,我們切換後直接變為active Namenode;
一、問題分析
1)Namenode 分析
我們選擇第一個block:blk_1075342606進行分析,切換後namenode1日誌如下:
這個日誌說明在namenode節點已經接受到Datanode對該block彙報但是在blockmap 裡面沒有block的記錄。那我們再看看 kill 了的namenode2的日誌吧。

該日誌說明已經給相應的block分配了相關的Datanode節點。也就是說在namenode2 inode(Fsimage) 和 blockmap 裡面已經有該blk的資訊。啥?Namenode 的inode(Fsimage)和blockmap 忘記了。忘記的同學可以一下看看ggjucheng 同學對namenode原始碼簡要分析:http://www.cnblogs.com/ggjucheng/archive/2013/02/04/2889386.html。 需要我們記住的是:NameNode作為HDFS中檔案目錄和檔案分配的管理者,它儲存的最重要資訊,就是下面兩個對映:
- 檔名=>資料塊:持久化為fsimage,持久化到記憶體中、檔案系統的inode相似;
- 資料塊=>DataNode列表,BLockmap儲存的結構。
2) Datanode日誌
批量查詢Datanode日誌,檢視blk是否寫入到Datanode。方法如下for i in $(cat ~/software/hadoop/etc/hadoop/slaves); do echo $i; ssh $i "grep blk_1075342606 ~/hadoop/logs/hadoop-bigdata-Datanode*.log*";done
可以驗證到如下:
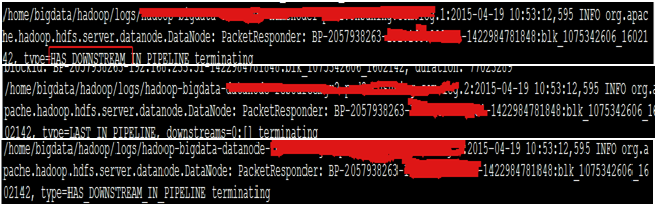
這說明blk 已經成功寫入到了三個Datanode節點。 資料寫入正常,但是namenode 1裡面關於該block的元資料不正常。
3) FileJournalManager同步日誌
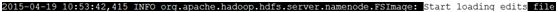 需要檢視edits是否記錄該block的edit log檔案。在10:53:42開始大量的日誌editlog同步。需要確定blk_1075342606相應的edit log是否同步過來。
需要檢視edits是否記錄該block的edit log檔案。在10:53:42開始大量的日誌editlog同步。需要確定blk_1075342606相應的edit log是否同步過來。4) 綜合分析
我們可以做如下分析:對於namenode1日誌,blockmap 裡面為什麼沒有該block資訊?熟悉HDFS的同學知道,在namenode啟動時,active namenode將每個檔案對應的blockid儲存入BlocksMap,此時BlocksMap中每個block對應的Datanodes列表暫時為空。建立檔案時會建立相應的blocksmap。在大神(微博名:@王志強-Austin)指導下,結合 Namenode HA方案,standby namenode同步editlog 通過QJM實現的,初步猜想Datanode增量彙報該block給 namenode1的時候,edit log還沒同步過來。怎麼驗證這種猜想了?重啟一下這個block對於的Datanode,重新進行一次block report 即可驗證。
我們重啟該block report對於的datanode,oh my God!奇蹟發生了,該block從頁面的missing block佇列裡面去掉了。然後對block對應的檔案,也能夠讀出資料。
我們回頭過來分析namenode1 block report 和edit log 的時間,發現在HDFS HA 切換期間,當Datanode 的incremental block report 在edit log同步之前發生時,後臺standby沒有完全變成activenamenode之前,會出現包含 invalidate block 的後臺日誌。
2. 原始碼分析
1) Datanode blockreport
Datanode會進行增量或者全量block report 給namenode。增量的block report間隔時間為100*(heartbeat間隔時間),每次會清空增量佇列;全量block report為1個小時。下面是程式碼入口: (1) reportReceivedDeletedBlocks: 從上次lastDeletedReport後的接收到的block彙報給namenode;所有新加入的block放到pendingIncrementalBRperStorage佇列中;當本次彙報完了以後會清空pendingIncrementalBRperStorage佇列;如果彙報失敗會將合併到下一次的pendingIncrementalBRperStorage;(2) blockReport :從上次lastBlockReport計算是否過了dnConf.blockReportInterval(預設為1個小時)時間,進行全量彙報;呼叫的介面如下:
bpNamenode.blockReport(bpRegistration, bpos.getBlockPoolId(), reports);2) Namenode blockreport process
下面檢視namenode如何處理IncrementalBlockReport,處理入口是:

根據不同的狀態對block處理不同,需要關注RECEIVED_BLOCK、RECEIVING_BLOCK的處理過程。下面的程式碼對block 進行的了判決:
BlockInfo storedBlock = blocksMap.getStoredBlock(block);
if(storedBlock == null) {
// If blocksMap does not contain reported block id,
// the replica should be removed from the data-node.
toInvalidate.add(new Block(block));
return null;
}
如果在blocksmap裡面找不到該block,就判斷該block為invalidate block;並且新增到toInvalidate佇列裡面。全量blockreport對Block的判決過程和IncrementalBlockReport相似。
3) FileJournalManager editlog
rollEditLog生成入口如下:CheckpointSignature rollEditLog() throws IOException {
checkSuperuserPrivilege();
checkOperation(OperationCategory.JOURNAL);
writeLock();
try {
checkOperation(OperationCategory.JOURNAL);
checkNameNodeSafeMode("Log not rolled");
if (Server.isRpcInvocation()) {
LOG.info("Roll Edit Log from " + Server.getRemoteAddress());
}
return getFSImage().rollEditLog();
} finally {
writeUnlock();
}
}
load edit log的載入入口為loadFSEdits,實現過程如下:
long startTime = now();
FSImage.LOG.info("Start loading edits file " + edits.getName());
long numEdits = loadEditRecords(edits, false, expectedStartingTxId,
startOpt, recovery);
FSImage.LOG.info("Edits file " + edits.getName()
+ " of size " + edits.length() + " edits # " + numEdits
+ " loaded in " + (now()-startTime)/1000 + " seconds");
if (FSNamesystem.LOG.isDebugEnabled()) {
FSNamesystem.LOG.debug(op.opCode + ": " + path +
" numblocks : " + addCloseOp.blocks.length +
" clientHolder " + addCloseOp.clientName +
" clientMachine " + addCloseOp.clientMachine);
}
如果需要檢視standby Namenode edit log詳細同步載入過程,可以開啟該方法對於class檔案的debug日誌,具體方法如下:
hadoop daemonlog --setlevel Namenode:9000 org.apache.hadoop.HDFS.server.Namenode. FSEditLogLoader debug3. 問題解決
通過上面分析日誌和原始碼分析我們得出如下結論:當kill active Namenode 時候,HDFS ha發生了切換。如果Datanode 的incremental block report 先於 standby Namenode editlog 同步,這些block變成了invalidate block;當 standby 完全切換完後變為active Namenode,這些新加入的block依然是invalidate block。需要Datanode再重新做blockreport。
在生產叢集出現這樣的情況,不可能當HA發生切換的時候去重啟invalidate block 對應的Datanode。可以採用如下方案解決:
- Datanode發現namenode 發生切換的時候做一次全量blockreport。這種方案的優點是隻需要修改Datanode程式碼,修改驗證簡單;缺點是每次傳送Namenode HA 切換所有Datanode都要重新做一次全量blockreport,通訊開銷變大。目前叢集每個節點也是每小時做一次全量blockreport。
- namenode專門起一個執行緒;當standby namenode變為activenamenode以後發現有invalidate block,給相應的Datanode傳送全量blockreport命令。這種方案的優點是隻讓有部分Datanode參與全量blockreport,減少通訊開銷;缺點是需要修改FF 和Datanode端程式碼,維護專門的執行緒去查詢invalidate block對應的Datanode併發送相關命令。
本文為了先解決問題,實現了第一種方案。在後續的文章中我們會繼續驗證第二種方案的可行性。在BPServiceActor.java中新增如下程式碼:
commit edf77140caba9761e22fb6660de4f8d11add216b
Author: Ricky Yang <[email protected]>
Date: Fri Apr 24 08:13:33 EDT 2015
missing block when HA switch
diff /hadoop-HDFS-project/hadoop-HDFS/src/main/java/org/apache/hadoop/HDFS/server/datanode/BPServiceActor.java
> private DatanodeProtocolClientSideTranslatorPB activeNamenode;
> DatanodeProtocolClientSideTranslatorPB nowactiveNamenode = bpos.getActiveNN();
> if((nowactiveNamenode != null) && !nowactiveNamenode.equals(activeNamenode)){
> LOG.info("active nn changed and block report agained");
> lastBlockReport= now()-dnConf.blockReportInterval-1;
> activeNamenode = nowactiveNamenode;
> }
1) 在BPServiceActor.java設定全域性變數保持當前activeNamenode;
2) 獲取當前的activeNamenode 儲存為nowactiveNamenode;
3) activeNamenode不為空並且namenode發生了切換時;
4) 調整lastblockreport時間,讓BPServiceActor滿足blockreport時間;
if (startTime - lastBlockReport <= dnConf.blockReportInterval) {
return null;
}5) 儲存當前active Namenode;
6) 該BPServiceActor 進行block report
此處巧妙修改了block report時間判斷條件lastBlockReport,提前觸發了全量blockreport。
4. 測試總結
重新編譯HDFS原始碼,替換相應的hadoop-HDFS-2.4.0.jar包,重啟HDFS和HBase。進行下面的測試:| Test-1 |
HDFS 可用性 |
| 測試步驟 |
1)持續寫入HDFS小檔案 2)kill 掉active Namenode 3)讀出檔案對比 4)檢視後臺日誌和web頁面 |
| 預期 |
1)HDFS 讀寫正確 2)後臺頁面也web頁面正常 |
| 測試結果 |
符合預期 |
| Test-1 |
HBase可用性 |
| 測試步驟 |
1)持續寫入HBase資料 2)kill 掉active Namenode 3)讀出剛才寫成的資料對比 4)檢視後臺日誌和web頁面 |
| 預期 |
1)HBase讀寫正確 2)HDFS後臺頁面也web頁面正常 |
| 測試結果 |
符合預期 |
原因是edit log還沒有同步過來,在namespace裡面沒有建立相應的inode和blockmap資訊。當edit log同步完了以後需要重新進行全量blockreport。第一種方案需要修改的程式碼較少,可以暫時使用該方案。在生產叢集已經執行1個多月,目前沒有暴露出問題。
開源軟體出現問題是很正常的,學習分析日誌並與程式碼結合不失是一種解決問題的好方法。