
Hadoop 叢集之HDFS HA、Yarn HA
部署叢集的原因
如果我們採用單點的偽分散式部署,那麼NN節點掛了,就不能對外提供服務。叢集的話,存在兩個NN節點,一個掛了,另外一個從standby模式直接切換到active狀態,實時對外提供服務(讀寫)。在生產上,避免出現對外服務中斷的情況,所以會考慮採用叢集部署。
HDFS HA (High availability)
單點式偽分佈:
NN
SNN secondary 1小時checkpoint
DN
HDFS HA:
NN active
NN standby 實時備份
DN
JN : JounalNode 日誌
ZKFC : zookeeperFailoverController(控制NN為active還是standby)
圖解如下:

- 過程分析
客戶端上輸入一個命令,然後NNactive節點把這個命令操作記錄寫到自己的editlog,同時JN叢集也會寫一份,NNstandby節點實時接收JN叢集的日誌,先是讀取執行log操作(重演),使得自己的元資料和activeNN節點保持一致,同時兩個NN節點都接受DN的心跳和blockreport。ZKFC監控NN的健康狀態,向ZK定期傳送心跳,使自己可以被選舉;當自己被ZK選舉為主的時候,zkfc程序通過RPC呼叫使NN的狀態變為active,對外提供實時服務。 - zookeeper 軟體
學習中:使用三臺
生產上:50臺規模以下 :7臺
50~100 9/11臺 >100 11臺
zk的部署是2n+1的方式。是選舉式投票原理,所以要配置奇數臺(zk並不是越多越好,因為考慮到zk越多,選舉誰做active的時間就會越長,會影響效率) - ZKFC zookeeperFailoverController:
在hdfs HA 中,它屬於單獨的程序,負責監控NN的健康狀態,向ZK定期傳送心跳,使自己可以被選舉;當自己被ZK選舉為主的時候,zkfc程序通過RPC呼叫使NN的狀態變為active,對外提供實時服務,這是無感知的。 - hdfs dfs -ls /命令
hdfs dfs -ls / 的 ‘/’相當於hdfs://ip:9000/的簡寫。所以在叢集環境中用這個命令就應該考慮ip具體是哪個機器的,所以用簡寫就代表是所在的那臺機器。舉例如下
NN1 active–>掛了 IP地址為192.168.1.100
NN2 standby 192.168.1.101
假如我們在192.168.1.100機器上用hdfs dfs -ls / 那麼就相當於hdfs dfs -ls hdfs://192.168.1.100:9000/ ,但是假如這臺機器掛了,我們再通過hdfs dfs -ls / 或者hdfs dfs -ls hdfs://192.168.1.100:9000/ 來執行命令已經不行了。如果說把其輸入命令改為hdfs dfs -ls hdfs://192.168.1.101:9000/ 去訪問雖然可以,但是生產上並不太可能,因為很多程式都已經打包好,不可能再去改這個命令列的對應的機器的IP地址。那麼,就有了一個對應的名稱空間 :nameservice來解決這個問題。 - 名稱空間
生產上HA命令是通過命令空間訪問的
名稱空間 :nameservice 在HA中其實並不關心哪臺機器是standby 哪臺是active。一般都是如下訪問:
名稱空間 :nameservice: ruozeclusterg5
hdfs dfs -ls hdfs://ruozeclusterg5/ 其實就相當於上圖中把兩個NN節點包起來,而對外提供的就為ruozeclusterg5,內部進行active的選舉,所以外部呼叫的時候並不關心哪個是active,只會用ruozeclusterg5去訪問,至於誰是active,內部會解決。 - ActiveNN:
操作記錄寫到自己的editlog,同時JN叢集也會寫一份;接收 DN的心跳和blockreport - StandbyNN:
接收JN叢集的日誌,先是讀取執行log操作(重演),使得自己的元資料和activenn節點保持一致,接收 DN的心跳和blockreport。 - JounalNode:
用於 active standby nn節點的同步資料,部署是2n+1個(3個/5個–>7個)JounalNode節點出問題比較少。最容易出問題的就是NNactive狀態,比如出現網路抖動導致延遲,這樣就可能會出現誤認為active 節點掛掉,把standby節點提升為active,這時候就可能出現兩個active節點。但是這種概率非常低,因為生產上一般採用區域網,不太會網路波動出現這種問題,但也有可能出現。還有一種情況就是兩個NN都是standby狀態,然後切不起來active,那麼這兩種情況下就會出現問題。所以並不能說在生產上HA就是萬無一失的。
總結:
HA是為了解決單點問題,兩個NN通過JN叢集共享狀態,通過ZKFC 選舉active,ZKFC監控狀態,自動備援,DN會同時向active standby nn傳送心跳和塊報告.HDFS HA的部署方法有:NameNode HA With QJM (相當於共享日誌,生產上推薦的就是QJM這種)和 NameNode HA With NFS (相當於共享儲存目錄)
學習中的叢集部署
hadoop001
NN
ZKFC(與NN部署在同一臺機器上)
DN
JN
ZK
hadoop002
NN
ZKFC(與NN部署在同一臺機器上)
DN
JN
ZK
hadoop003
DN
JN
ZK
生產上的叢集:
假如還有幾臺空機器hadoop004-010 那麼就可以把001 002 上部署的DN拿下來,部署在hadoop004-010 機器上,這個是要看具體機器的配置及數量,按需分配
Yarn HA
圖解如下:
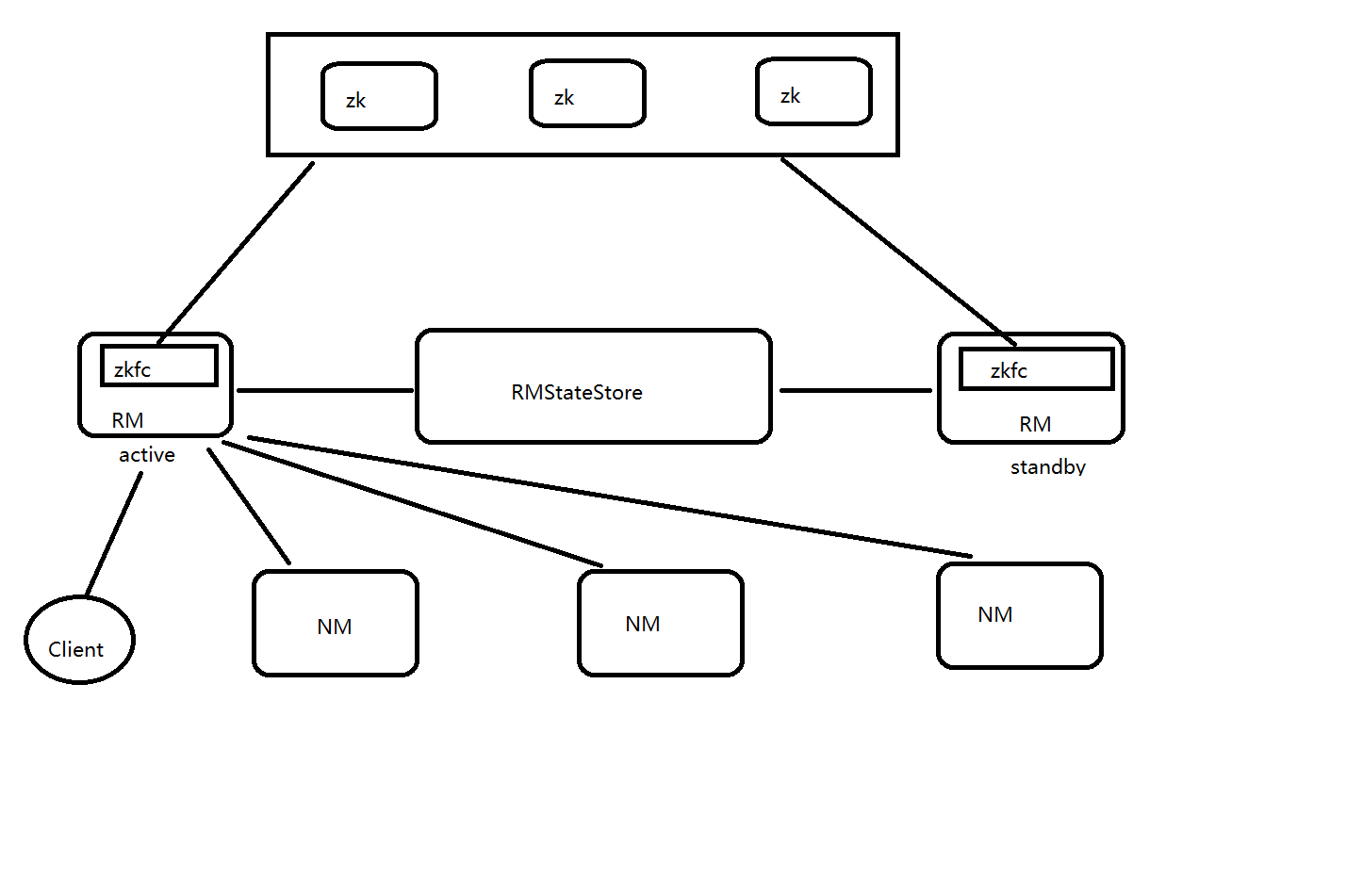
-
zkfc是在RM裡面的,只作為RM程序的一個執行緒而非獨立的守護程序來獨立存在。這個涉及到一個概念,執行緒
在yarn HA中,zkfc是執行緒,也就是RM程序的一個執行緒。所謂程序就是jps 、 ps-ef | grep xxx 能夠檢視到的,而執行緒 屬於一個程序的裡面的 除非特殊命令和工具才能看到。 包含至少一個執行緒。 -
RMStateStore:
a.RM把job資訊存在在ZK的/rmstore下(類似hdfs的根目錄,zk也有自己的根目錄),activeRM會向這個目錄寫app資訊
b.當active RM掛了,另外一個standby RM通過zkfc選舉成功為active,會從/rmstore讀取相應的作業資訊。 重新構建作業的記憶體資訊,啟動內部服務(apps manager 和資源排程),開始接收NM的心跳,構建叢集的資源資訊,並且接收客戶端的作業提交請求。 -
RM:
a.啟動時候的會向ZK的目錄?寫個lock檔案,寫成功的話,就為active,否則為standby。然後standby rm節點會一直監控這個lock檔案是否存在,假如不存在,就試圖建立,假如成功就為active。
b.接收client的請求。接收和監控NM的資源狀況彙報,負載資源的分配和排程。
c.啟動和監控ApplicationMaster(AM) on NM的container(執行在NM上面的容器裡面)
注:ApplicationsManager RM
ApplicationMaster 是JOB的老大 執行在NM的container (相當於spark的driver) -
NM:
節點的資源管理,啟動container執行task計算,上報資源,彙報task進度給AM (ApplicationMaster)
yarn HA 和hdfs HA之間的區別
- hdfs中zkfc是屬於程序。yarn中zkfc是屬於RM程序中的一個執行緒
- dn和nm的區別:DN會同時給NN active和standby都發送心跳包和塊報告。NM只會向NN active傳送心跳包
- hdfs HA叢集啟動的程序順序:
- 架構: