
【大資料技術】3.Mapreduce和Yarn
一、Mapreduce
Mapreduce主要應用於日誌分析、海量資料的排序、索引計算等應用場景,它是一種分散式計算模型,主要用於解決離線海量資料的計算問題。
核心思想是:“分而治之,迭代彙總”
Mapreduce主要由兩個階段:
map階段:任務分解
1.讀取HDFS中的檔案,把輸入檔案按照一定的標準分片,每個輸入片的大小是固定的,(預設情況下,輸入片的大小與資料塊的大小相同,資料塊大小預設為64M(一般為64M或128M)),假設輸入檔案若為72M,那麼該檔案進行讀取時,會分成64M和8M兩個輸入分片
2.解析成鍵值對,預設規則按行解析,“鍵”是每行起始位置(單位是位元組),“值”是本行的文字內容
3.按照鍵進行分割槽,比如鍵表示省份,按照不同省份進行分割槽,需要注意的是,分割槽的數量就是reducer階段任務執行的數量
4.對每個分割槽鍵值對進行排序,排序規則:首先按照鍵進行排序,對於鍵相同的,按照值排序
(對於鍵相同的鍵值對可以通過手動新增reduce方法,使資料量減少)
reduce階段:結果彙總
1.複製多個mapper階段任務的輸出,合併成一個大資料,並對資料進行整體排序
2.對於鍵相等的鍵值對呼叫一次reduce方法,最後把這些鍵值對寫入到HDFS中
其中排序、合併、分割槽等操作都由屬於shuffle過程,mapper與reduce端是通過http協議進行資料傳輸。
二、Yarn
mapreduce經過一系列的優化,升級稱為MR2,Yarn
它主要捨棄了MR1的Jobtrack,tasktrack,減少了Jobtrack的消耗
MR2將Jobtrack分為兩部分,即資源管理和工作任務,即全域性的ResourceManager(RM)和每個應用都有的NodeManager(NM),形成主從關係的計算框架。MRAppMaster負責任務的完成。
角色關係:
Client=需求
RM =甲方經理層(公司領導)
NM =乙方經理層(公司領導)
MRAppMaster =專案經理
Task = 專案組員工
容器 = 核心資訊 (這塊可能理解不對)
工作原理
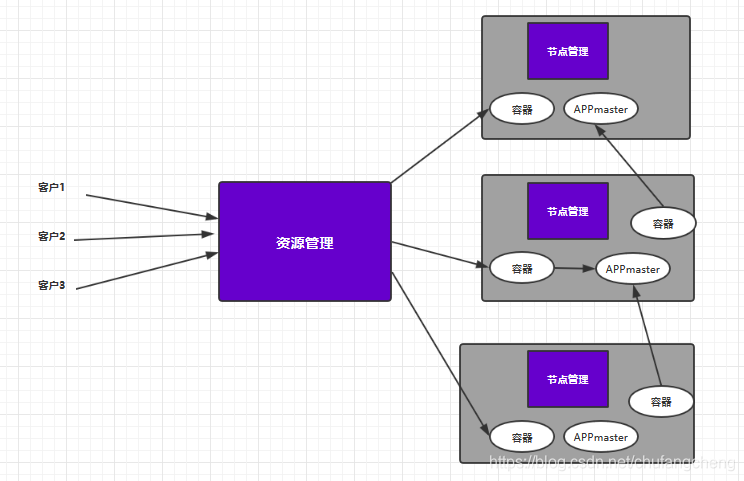
1.客戶向RM發起請求 (甲方來了一個需求)
2.RM分配建立容器,通知NM啟動MRAPPMaster (甲方經理層將核心資訊通知乙方經理層,讓乙方配備專案經理)
3.NM接受指定任務,並開闢空間啟動MRAPPMaster (乙方經理層接收專案,成立專案組並配備資源與專案經理)
4.MRAPPMaster獲取資源後,與NM通訊,啟動MapTask和reduceTask程序 (專案經理獲取資源後,給專案成員分配任務)
5.任務執行,並定時向MRAPPMaster彙報任務執行情況 (專案成員執行任務,並定期給專案經理作彙報)
以上個人總結,如有不對的地方請大家指點,謝謝。