
資料結構與演算法之美專欄學習筆記-二叉樹基礎(下)
二叉查詢樹 Binary Search Tree
二叉查詢樹的定義
二叉查詢樹又稱二叉搜尋樹。其要求在二叉樹中的任意一個節點,其左子樹中的每個節點的值,都要小於這個節點的值,而右子樹的節點的值都大於這個節點的值。
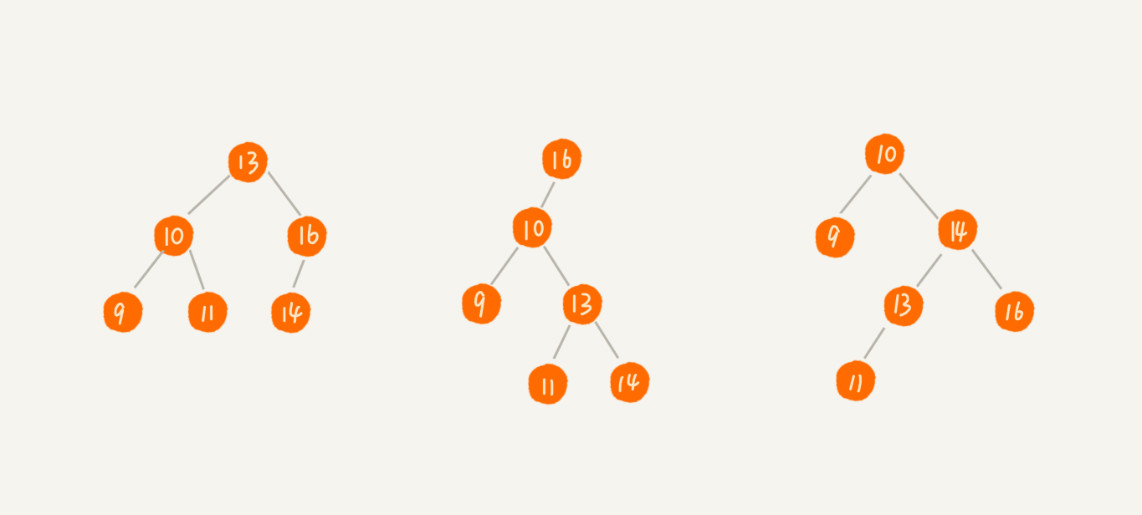
二叉查詢樹的查詢操作
二叉樹類、節點類以及查詢方法的程式碼實現
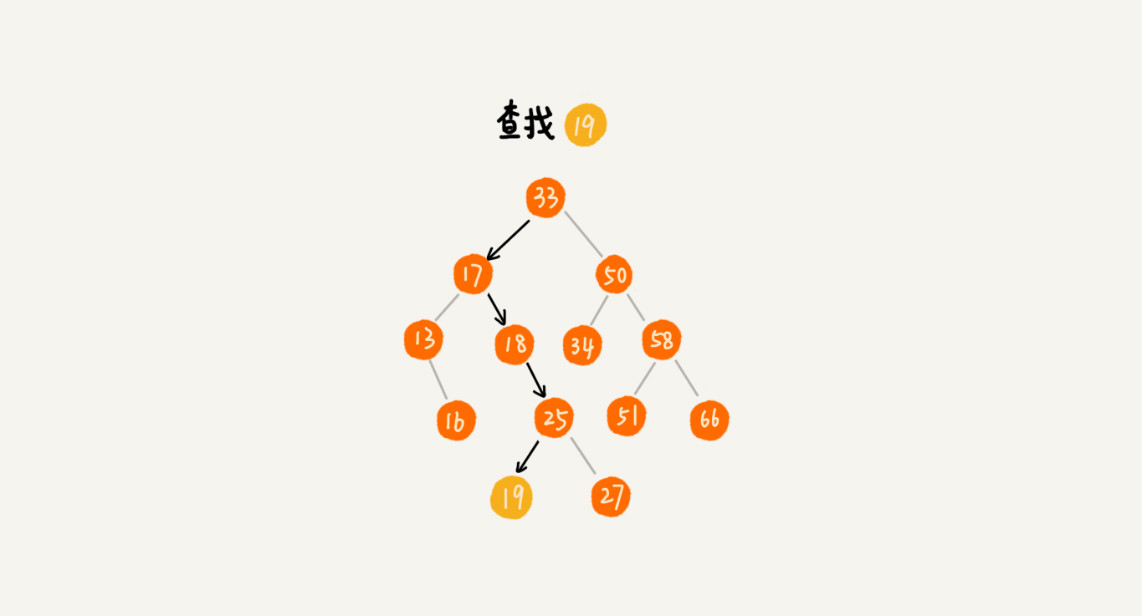
先取根節點,如果它等於我們要查詢的資料,那就返回。
如果要查詢的資料比根節點的值小,那就在左子樹中遞迴查詢;
如果要查詢的資料比根節點的值大,那就在右子樹中遞迴查詢。
public class BinarySearchTree{ //二叉樹節點類 publicclass Node{ //自動屬性:整型資料,左節點、右節點引用域 public int Data { get; set; } public Node Left { get; set; } public Node Right { get; set; } public Node(int data){ Data = data; } } //根結點 private Node tree; public Node Tree{get{return tree;}}//查詢方法 public Node Find(int data){ //從根節點遍歷 Node p = tree; while (p != null){ if (data > p.Data) p = p.Right; else if (data < p.Data) p = p.Left; else return p; } return null; } }
二叉查詢樹的插入操作
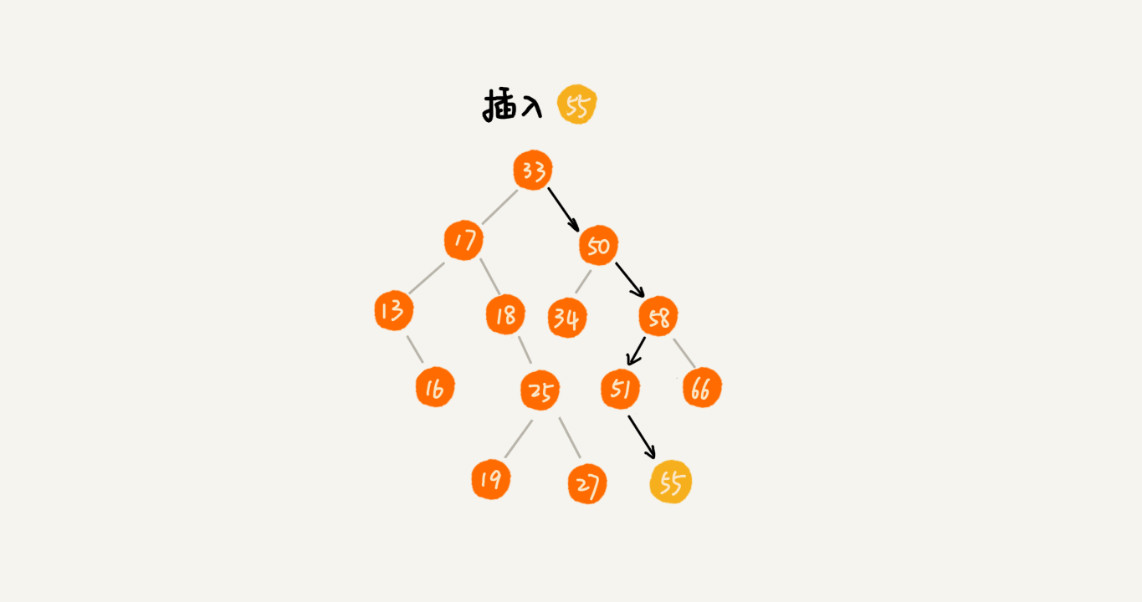
新插入的資料一般都是在葉子節點上,所以我們只需要從根節點開始,依次比較要插入的資料和節點的大小關係。
如果要插入的資料比節點的資料大,並且節點的右子樹為空,就將新資料直接插到右子節點的位置;如果不為空,就再遞迴遍歷右子樹,查詢插入位置。
同理,如果要插入的資料比節點數值小,並且節點的左子樹為空,就將新資料插入到左子節點的位置;如果不為空,就再遞迴遍歷左子樹,查詢插入位置。
public void Insert(int data){ //沒有根節點則插入根節點 if (tree == null) { tree = new Node(data); return; } //遍歷根節點 Node p = tree; while (p!=null){ //根據資料大小找到左右子樹對應的葉節點,將資料插入 if (data >= p.Data){ if (p.Right == null){ p.Right = new Node(data); return; } p = p.Right; } else if (data < p.Data){ if (p.Left == null){ p.Left = new Node(data); return; } p = p.Left; } } }
二叉查詢樹的刪除操作
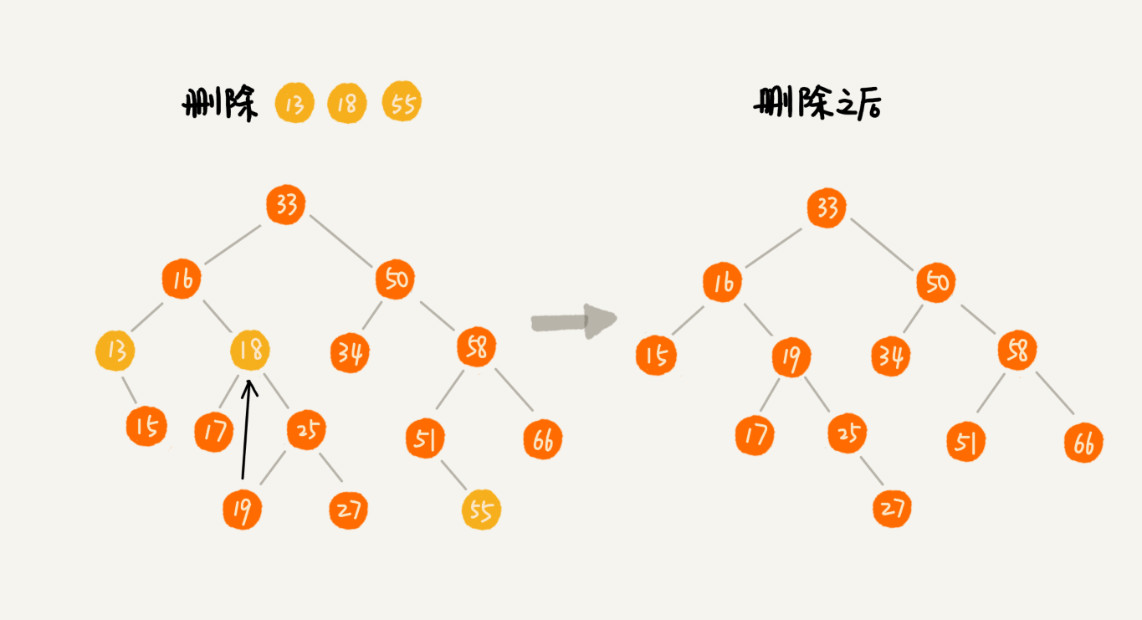
第一種情況,刪除的節點沒有子節點直接將其父節點指向置為null。
第二種情況,刪除的節點只有一個子節點,將其父節點指向其子節點。
第三種情況,刪除的節點有兩個子節點,首先找到該節點右子樹中最小的的節點把他替換掉要刪除的節點 然後再刪除這個最小的節點,該節點必定沒有子節點,否則就不是最小的節點了
public void Delete(int data){ Node p = tree;//p指向要刪除的節點 Node pp = null;//記錄p的父節點 while (p != null && p.Data != data){ pp = p; if (data > p.Data) p = p.Right; else p = p.Left; } if (p == null) return; //要刪除的節點有兩個子節點 if (p.Left != null && p.Right != null){ Node minP = p.Right; Node minPP = p; while (minP.Left != null){ minPP = minP; minP = minP.Left; } p.Data = minP.Data; p = minP;//p節點的值更新為最小節點的值,使p指向最小節點,下面就變成了刪除p pp = minPP; } //要刪除的節點有一個子節點,就獲取它的子節點 Node child; if (p.Left != null) child = p.Left; else if (p.Right != null) child = p.Right; 或者沒有節點,子節點設為null else child = null; //要刪除的節點是根節點 if (pp == null) tree = child; //刪去節點,其父節點直接指向其子節點 else if (pp.Left == p) pp.Left = child; else pp.Right = child; }
關於二叉查詢樹的刪除操作,還有個非常簡單、取巧的方法,就是單純將要刪除的節點標記為“已刪除”,但是並不真正從樹中將這個節點去掉。
這樣原本刪除的節點還需要儲存在記憶體中,比較浪費記憶體空間,但是刪除操作就變得簡單了很多。而且,這種處理方法也並沒有增加插入、查詢操作程式碼實現的難度。
二叉查詢樹的其他操作
二叉查詢樹中還可以支援快速地查詢最大節點和最小節點、前驅節點和後繼節點。
二叉查詢樹除了支援上面幾個操作之外,還有一個重要的特性,就是中序遍歷二叉查詢樹,可以輸出有序的資料序列,時間複雜度是 O(n),非常高效。因此,二叉查詢樹也叫作二叉排序樹。
下面使用一組測試資料,其資料結構如下所示
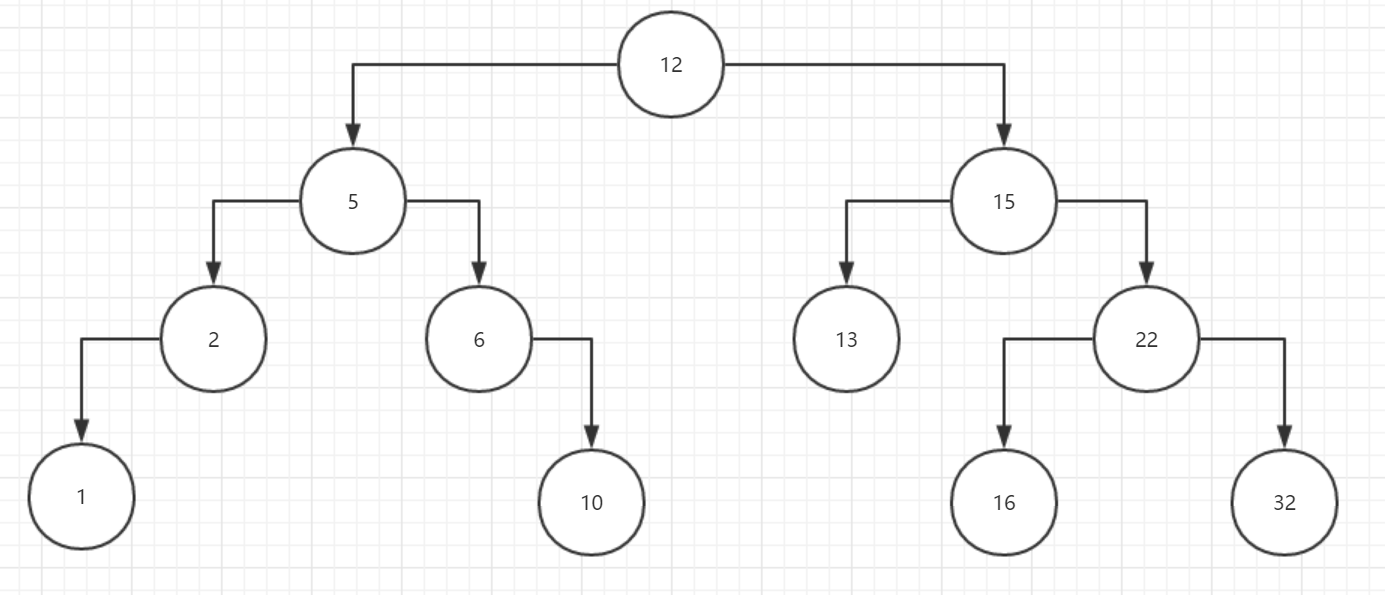
測試資料Program類
class Program{ static void Main(string[] args){ BinarySearchTree b = new BinarySearchTree(); //插入資料 b.Insert(12); b.Insert(15); b.Insert(5); b.Insert(6); b.Insert(2); b.Insert(22); b.Insert(32); b.Insert(10); b.Insert(16); b.Insert(13); b.Insert(1); //層序遍歷 b.LevelOrder(); Console.WriteLine(); //刪除節點 b.Delete(15); //再層序遍歷 b.LevelOrder(); Console.WriteLine(); //中序遍歷 b.InOrder(b.Tree); Console.WriteLine("Over"); Console.ReadKey(); } }
層序遍歷和中序遍歷二叉查詢樹
//層序遍歷,就是圖的深度優先搜尋演算法 public void LevelOrder(){ Queue<Node> q = new Queue<Node>(); //根節點入棧,迴圈遍歷棧,直到棧空 q.Enqueue(tree); while (q.Count != 0){ //打印出棧的資料 Node node = q.Dequeue(); Console.Write(node.Data + ","); //將出棧的節點的子節點入棧 if (node.Left != null) q.Enqueue(node.Left); if (node.Right != null) q.Enqueue(node.Right); } } //中序遍歷,相當於排序 public void InOrder(Node node){ if (node == null) return; InOrder(node.Left); Console.Write(node.Data + ","); InOrder(node.Right); }
輸出結果
12,5,15,2,6,13,22,1,10,16,32, 12,5,16,2,6,13,22,1,10,32, 1,2,5,6,10,12,13,16,22,32,Over
支援重複資料的二叉查詢樹
前面的二叉查詢樹的操作,我們預設樹中節點儲存的都是數字,針對的都是不存在鍵值相同的情況。
我們可以通過兩種辦法來構建支援重複資料的二叉查詢樹。
第一種方法
二叉查詢樹中每一個節點不僅會儲存一個數據,因此我們通過連結串列和支援動態擴容的陣列等資料結構,把值相同的資料都儲存在同一個節點上。
第二種方法
每個節點仍然只儲存一個數據。在查詢插入位置的過程中,如果碰到一個節點的值,與要插入資料的值相同,我們就將這個要插入的資料放到這個節點的右子樹,也就是說,把這個新插入的資料當作大於這個節點的值來處理。
當要查詢資料的時候,遇到值相同的節點,我們並不停止查詢操作,而是繼續在右子樹中查詢,直到遇到葉子節點,才停止。這樣就可以把鍵值等於要查詢值的所有節點都找出來。
對於刪除操作,我們也需要先查詢到每個要刪除的節點,然後再按前面講的刪除操作的方法,依次刪除。
二叉查詢樹的時間複雜度分析
最壞、最好情況
如果根節點的左右子樹極度不平衡,已經退化成了連結串列,所以查詢的時間複雜度就變成了 O(n)。
最理想的情況,二叉查詢樹是一棵完全二叉樹(或滿二叉樹)。不管操作是插入、刪除還是查詢,時間複雜度其實都跟樹的高度成正比,也就是 O(height)。而完全二叉樹的高度小於等於 log2n。
平衡二叉查詢樹
我們需要構建一種不管怎麼刪除、插入資料,在任何時候都能保持任意節點左右子樹都比較平衡的二叉查詢樹,這就是一種特殊的二叉查詢樹,平衡二叉查詢樹。
平衡二叉查詢樹的高度接近 logn,所以插入、刪除、查詢操作的時間複雜度也比較穩定,是O(logn)。
二叉查詢樹相比散列表的優勢
散列表中的資料是無序儲存的
如果要輸出有序的資料,需要先進行排序。而對於二叉查詢樹來說,我們只需要中序遍歷就可以在 O(n) 的時間複雜度內,輸出有序的資料序列。
散列表擴容耗時很多
而且當遇到雜湊衝突時,效能不穩定,儘管二叉查詢樹的效能不穩定,但是在工程中,我們最常用的平衡二叉查詢樹的效能非常穩定,時間複雜度穩定在 O(logn)。
散列表存在雜湊衝突
儘管散列表的查詢等操作的時間複雜度是常量級的,但因為雜湊衝突的存在,這個常量不一定比 logn 小,所以實際的查詢速度可能不一定比 O(logn) 快。
加上雜湊函式的耗時,也不一定就比平衡二叉查詢樹的效率高。
散列表裝載因子不能太大
為了避免過多的雜湊衝突,散列表裝載因子不能太大,特別是基於開放定址法解決衝突的散列表,不然會浪費一定的儲存空間。
綜合這幾點,平衡二叉查詢樹在某些方面還是優於散列表的,所以,這兩者的存在並不衝突。
思考
如何通過程式設計,求出一棵給定二叉樹的確切高度呢?