
python爬蟲-簡單使用xpath下載圖片
首先
1.為方便以下進行
谷歌瀏覽器裡要安裝xpath指令碼
2.下載一個lmxl 命令:pip install lxml
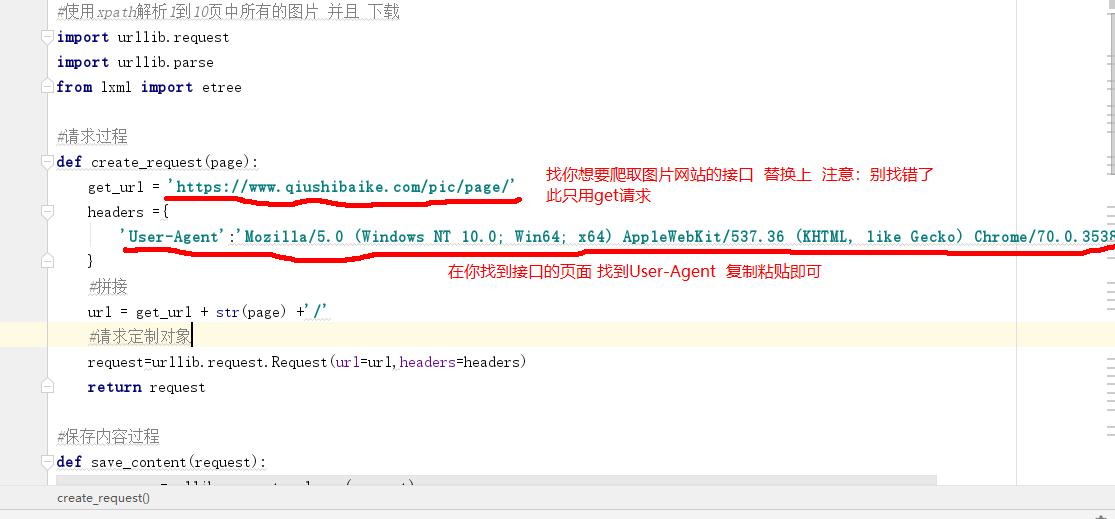
3. 以下三張圖是一個,當時爬的 《糗事百科》裡的圖片
值的注意的是:在爬取介面時,要仔細看看 ,當時用的谷歌瀏覽器 當然也可以借用工具 EditPlus 這個比較好使,看個人喜好吧 用瀏覽器或Ediutplus工具 都行 。
使用谷歌瀏覽器 開啟你要你想要下載的圖片的網站 右鍵點選檢查 開啟network 找介面
找到介面的同時 User-Agent 也就有了 就在下面 找一找就能找到
4.使用xpath時 選中Elements 逐步按標籤查詢圖片的路徑,把找到的標籤寫在xpath簡搜 ,直到你想要的。
建議:用xpath之前先看看怎麼使用xpath


就先這樣吧!
各位博友,請多多指教!
相關推薦
python爬蟲-簡單使用xpath下載圖片
首先 1.為方便以下進行 谷歌瀏覽器裡要安裝xpath指令碼 2.下載一個lmxl 命令:pip install lxml 3. 以下三張圖是一個,當時爬的 《糗事百科》裡的圖片 值的注意
Python 爬蟲簡單實現 (爬取下載連結)
原文地址:https://www.jianshu.com/p/8fb5bc33c78e 專案地址:https://github.com/Kulbear/All-IT-eBooks-Spider 這幾日和朋友搜尋東西的
Python爬蟲——利用PhantomJS下載動態載入圖片
在瀏覽網頁過程中,我們會遇到一些讓人心動的圖片,這時我們需要將它儲存在本地。一般我們用BeautifulSoup可以解析靜態網頁,但很多時候我們遇到的都是動態載入的圖片,無法再利用urllib模組操作了。 本次分享將講述如何利用PhantomJS來下載
python 爬蟲(xpath解析網頁,下載照片)
XPath (XML Path Language) 是一門在 XML 文件中查詢資訊的語言,可用來在 XML 文件中對元素和屬性進行遍歷。 lxml 是 一個HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 資料。lxml和正則一樣,也是用 C
python爬蟲簡單的抓頁面圖片並儲存到本地
1、首先注意編碼,設定為utf-8 #coding=utf-8 或者 #-*-conding:UTF-8 -*- 先抓取頁面資訊 #coding=utf-8 import urll
python爬蟲--利用xpath爬取圖片(虛擬機器ubuntu16.04)
此篇爬蟲的背景是:虛擬機器剛裝好的ubuntu 16.04,系統環境還需配置,爬蟲的程式是之前幾個月前在windows上寫的,今天放到虛擬機器上跑一跑!(安裝了VMware Tools就可以把宿主機上的檔案拉進虛擬機器中!) xpath爬取用到了urllib2與lxml庫,
[python學習] 簡單爬取圖片站點圖庫中圖片
ctu while 要去 文章 ava ges file cor nal 近期老師讓學習Python與維基百科相關的知識,無聊之中用Python簡單做了個爬取“遊訊網圖庫”中的圖片,由於每次點擊下一張感覺很浪費時間又繁瑣。主要分享的是怎樣爬取HTML
[Python]python爬蟲簡單試用
.com www pytho request rom open url 使用 開始 一直用的是python3.4版本,所以只用了urllib爬數據,然後使用BeautifulSoup做為分析。 1、首先安裝BeautifulSoup,執行命令如下: pip install
Python爬蟲:Xpath語法筆記
上一個 div 運算符 tar 爬蟲 att 語法 ont tab 常用的路勁表達式: 表達式 描述 實例 nodename 選取nodename節點的所有子節點 xpath(‘//div’) 選取了div節點的所有子節點 / 從根節點選取 xpath
Python爬蟲 —— 抓取美女圖片
In root lxml 取圖 ext time style main HR 代碼如下: 1 #coding:utf-8 2 # import datetime 3 import requests 4 import os 5 import sys
Python爬蟲 —— 抓取美女圖片(Scrapy篇)
parse color 爬蟲 select 尺度 dex -i www 模塊 雜談: 之前用requests模塊爬取了美女圖片,今天用scrapy框架實現了一遍。 (圖片尺度確實大了點,但老衲早已無戀紅塵,權當觀賞哈哈哈) Item: # -*- codi
python爬蟲7——XPath與lxml類庫、xpath helper外掛
有同學說,我正則用的不好,處理HTML文件很累,有沒有其他的方法? 有!那就是XPath,我們可以先將 HTML檔案 轉換成 XML文件,然後用 XPath 查詢 HTML 節點或元素。 什麼是XML XML 指可擴充套件標記語言(EXtensible Marku
Python爬蟲爬取網上圖片原始碼,可用來製作深度學習資料集
這次利用python設計一個爬取百度圖片上的圖片的原始碼,其中利用的是python的urllib,如果沒有裝的,可以使用Anconda在環境裡進行安裝或者 pip install urllib 這兩種方式都可以安裝,長話短說,上圖吧,點選執行後,輸入你要下載的圖片型別: 比如,熊貓?美女?
python爬蟲之xpath的基本使用 python爬蟲之xpath的基本使用
python爬蟲之xpath的基本使用 一、簡介 XPath 是一門在 XML 文件中查詢資訊的語言。XPath 可用來在 XML 文件中對元素和屬性進行遍歷。XPath 是 W3C XSLT 標準的主要元素,並且 XQuery 和 XPointer 都構建於
python爬蟲之xpath和lxml解析內容
上兩章說了urllib和request庫如何訪問一個頁面或者介面,從而獲取資料,如果是訪問介面,還好說,畢竟返回的json還是很好解析的,他是結構化的,我們可以把它轉化成字典來解析,但是如果返回的是xml或者html,就有點麻煩了,今天就主要說一下如果解析這些h
Python爬蟲小試——爬取圖片
如果是直接裝了Anaconda整合開發環境的,就可以直接移步原始碼了 否則的話,在爬取圖片之前要安裝幾個包 第一個:bs4包,需要用到其中的BeautifulSoap,是一個功能強大的網頁解析工具 pip3 install bs4 第二個:requests包,
Python爬蟲——解決urlretrieve下載不完整問題且避免用時過長
在這篇部落格中:http://blog.csdn.net/Innovation_Z/article/details/51106601 ,作者利用遞迴方法解決了urlretrieve下載檔案不完整的方法,其程式碼如下: def auto_down(url,filename): t
python爬蟲的xpath、bs4、re方法
1.re正則表示式 # 正則表示式分析: 找開始和結束標籤,兩個標籤之間把想要的內容需要包含進來,然後依次查詢分析。 pat = r'<div class="post floated-thumb">(.*?)<p class="align-right"&
Python爬蟲讀書筆記——下載快取(5)
為了支援快取,需要修改之前編寫的download函式,使其在URL下載前進行快取檢查。另外,需要把限速功能移至函式內部,只有在真正發生下載時才會觸發限速,而在載入快取時不會觸發。 為了避免每次下載都要傳入多個引數,我們藉此機會將download函式重構為一個類,這樣引數只需
python爬蟲-爬取美女圖片
當你發現某個網站上有大量的美女圖片,又非常想看,怎麼辦,網頁上看?每次看的時候都得載入吧!No,你可以把這些圖片都儲存到本地,然後,在你想看的時候就可以隨時看了,哈哈!多的不說。下面就來上程式碼: 1,匯入庫檔案: # -*- coding:utf-8 -*- # 通過request