
Python 核心程式設計學習——正則表示式
#正則表示式
首先明確一下學習正則表示式的初衷
讀完了蟲師的自動化實踐書,自己動手想寫一個介面測試,發現很多東西都不大會,很多地方卡死了,尤其卡在匹配字元上,師父讓我直接用index取出字元,程式碼感覺不大美觀。
正則表示式是一些有字元和特殊符號組成的字串,它們描述了模式的重複或者表述多個字元
作用:為高階的文字模式匹配、抽取與為文字形式的搜尋和替換功能提供了基礎
這裡推薦菜鳥工具
https://c.runoob.com/front-end/854
標準庫中的re模組
模式匹配的完成方式:一是搜尋search(),二是匹配match()
^匹配字串起始部分

$匹配字串結尾部分
*一次或多次出現的正則表示式
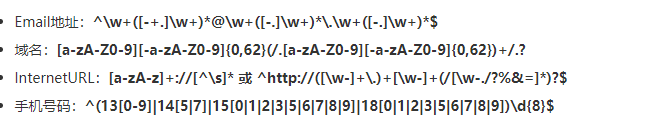
注意:
1、|匹配多個正則表示式模式
2、從字串的開頭和結尾或單詞邊界開始匹配(^/$/\b/\B)
3、匹配任意單個字元(.)(不包括\n)
4、建立字元集合[]
re模組函式的使用
import re
match() 開頭開始,成功返回匹配物件,否則返回None
search() 查詢正則表示式第一次出現,如果匹配成功返回匹配物件,否則返回None
findall() 在字串中查詢正則表達模式的所有(非重複)出現;返回一個列表
split() 根據正則表示式中的分隔符吧字元分割為一個列表,返回成功匹配的列表,可以設定次數(預設是分割所有匹配的地方)
sub() 把字串中所有匹配正則表示式的地方替換成字串,如果次數沒有給出,則對所有匹配的地方進行替換
group() 返回所有匹配物件或是返回某個特定自足(指定編號是num的子組)
import re
re.match(‘app’,‘app123’).group()
‘app’
re.match(‘app’,‘123app’).group()
×
re.search(‘app’,‘app123’).group()
‘app’
findall()的妙用
findall(rule,target[,flag])
flags定義包括:
re.I 忽略大小寫
re.L 表示特殊字符集\w,\W,\b,\B,\s,\S依賴於當前環境
re.M 多行模式
re.S '.‘並且包括換行符在內的任意字元(’.'不包括換行符)
re.U 表示特殊字符集\w,\W,\b,\B,\s,\S依賴於Unicode字元屬性資料庫
#爬取標題

//title=re.findall(’
print ‘’.join(title)
——轉化為列表
#爬取連結
//links=re.findall('href="(.?)"’,html)
for each in links:
print each
sub()和subn()進行替換
用split()分隔(分隔模式)
貪婪匹配和非貪婪匹配
1、當正則表示式中包含能接受重複的限定符時,匹配儘可能多的字元
2、貪婪匹配:a.b,它將會匹配最長的以a開始,以b結束的字串,如果讓它來搜尋aabab,它將會匹配整個字串aabab
3、非貪婪匹配:貪婪模式它後面加上一個問號?。‘.?’就意味著在能使整個匹配成功的前提下使用最少的重複
4、a.*?b匹配最短的以a開始,以b結束的字串,如果把它應用於aabab的話,他會匹配aab和ab