
2017-CVPR-Spindle Net: Person Re-identification with Human Body Region Guided Feature
阿新 • • 發佈:2018-11-22
轉載自:https://blog.csdn.net/weixin_41427758/article/details/82910295
Motivation
- 由檢測演算法以及姿勢變化引起的行人身體不對準問題會為不同影象間的特徵匹配造成嚴重的影響 --> 怎麼解決這個問題?
Contribution
- 首次在ReID中考慮人體結構資訊:
- 幫助對齊不同影象中人體區域特徵
- 增強區域性細節資訊的表示能力
- SpindleNet
- a multi-stage ROI pooling framework --> 不同語義層次的特徵在不同階段進行提取
- a tree-structured fusion network + competitive strategy --> 合併不同語義層次的特徵
- 真實監控場景的ReID資料集–SenseReID來評價演算法的效能;本文的方法在大多資料集上達到了SOTA的方法
1. Introduction
- ReID定義以及用途
- 跨攝像頭或時間片段檢索行人
- 主要在安防場景

-
ReID常見的挑戰:
- 由於檢測演算法以及姿勢變化,不同影象之間的行人身體存在不對準問題,如上圖(a)
- 如何捕獲易於區分的細節資訊,如圖(b),頭部區域對於兩個圖片有更強的判別力
- 遮擋問題:如何在比較過程中,降低遮擋區域的特徵重要性
-
a tree-structured feature fusion strategy + a competitive strategy
2. Related Work
- 特徵學習
- 度量學習
- Video Based
- 通過the Region Proposal Net- work (RPN)來產生7個身體區域
- 關鍵點定位
- 身體區域產生

-
借鑑了CPM,利用sequential framework以由粗到細的方式來生成響應圖,全卷積網路 --> 14個response map
- 在每個階段,CNN提取特徵並結合上一個階段的響應圖來refine關鍵點估計的位置
- 對CPM進行修改來降低其複雜度:
- 共享前幾層的卷積引數
- 用s=2的卷積代替池化層
- 減小了輸入大小、階段數、卷積層的通道數
-
14個關節點可以通過最大化特徵圖上的值得到:
Pi=[xi,yi]=argmaxx∈[1,X],y∈[1,Y]Fi(x,y)
-
Pi=[xi,yi]=argx∈[1,X],y∈[1,Y]maxFi(x,y)
-
根據14個關節點生成3個巨集觀區域(頭-肩,上體、下體)、4個微觀區域(雙腿、雙臂),具體可參考上圖
-
RPN的訓練:
- the MPII human pose dataset
- a Gaussian kernel
- Loss function:L2 distance
4. Body Region Guided Spindle Net

- 兩個主要部分:
- the Feature Extraction Network (FEN):輸入為行人圖片以及候選區域 ==> 計算全域性特徵與子區域特徵
- the Feature Fusion Network (FFN):合併不同區域的特徵向量
4.1. Feature Extraction Network (FEN)
-
FEN由three convolution stages (FEN-C1, FEN-C2, FEN-C3)、two ROI pooling stages (FEN-P1, FEN-P2):
- 1個全圖 + 7個身體子部分每個產生256維向量
- sub-region的特徵從全圖的特徵上在不同階段crop得到
- 在FCN-C3後通過one global pooling layer and one inner product layer將輸出轉換為256維向量
-
下圖表明瞭子區域特徵的有效性

- (b)、(e)為經過FEN-C1的全域性特徵,由該特徵計算非對準的相同人的距離將遠,相似人兩個人距離較近
- (c )、(f)為FEN-P1後的特徵,利用該特徵計算相似性對於非對準的相同人距離減小,相似人的距離增大
4.2. Feature Fusion Network (FFN)
-
FFN:將8個特徵向量合併成為一個可以很好描述行人圖片的256向量
-
fusion unit:進行特徵融合過程,輸入為大小相同的兩個或多個特徵向量,輸出為合併後的特徵向量
The feature competition and selection process:element-wise maximization operationThe feature transformation process:a inner product layer ==> 對應caffe裡的全連線層
-
A tree-structured fusion strategy
- 根據子區域的不同語義層次與關係在不同的階段將特徵向量進行合併
- 雙腿、雙臂 --> 雙腿結果+下體、雙臂結果 + 上體 --> 上階段結果 + 頭-肩 --> 與全圖的特徵進行拼接並轉換成256維向量
-
對頭-肩、上體、下體的融合
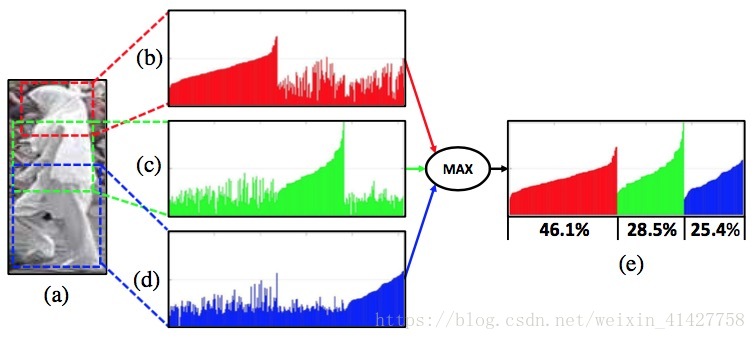
4.3. Training Details
-
progressive strategy:先訓練FEN、再訓練FFN;權重全部隨機初始化
-
FEN訓練步驟:
- 先訓練輸入為全圖
- 固定FEN-C1引數,訓練三個巨集觀分支
- 固定FEN-C1、FEN-C2,訓練四個微觀分支
-
FFN由FEN產生的特徵向量進行訓練,Softmax
5. Experiments
5.1. Datasets
- 實驗資料集以及劃分策略如下表:

5.2. Comparison Results
- 在大多資料集上取得了SOTA方法



6. Investigations on Spindle Net
6.1. Investigations on FEN
- ROI pooling得到巨集觀區域以及微觀區域的最佳位置

-
由上圖可以看到:
- Marco最佳為FEN-C1:macro包含更復雜的身份資訊,應該更早的pool out來得到更多獨立的學習引數
- Micro最佳為FEN-C2
-
全圖特徵與在不同階段提取巨集觀及微觀特徵的組合實驗

6.2. Investigations on FFN
- 測試每種特徵的效果:全圖 > 巨集觀 > 微觀

- 樹型融合策略與其他融合策略的對比:

7. Conclusion
- 本文提出的Spindle Net:
- a multi-stage ROI pooling network:分開提取不同身體區域特徵
- tree-structured fusion network:合併不同身體區域特徵
- 不同層次的身體特徵有助於對齊不同行人圖片的身體區域
- 通過實驗驗證了feature com- petition and fusion network的有效性
- 本文的方法在多個數據集上取得了SOTA的方法