
論文筆記(4)--(Re-ID)Re-ranking Person Re-identification with k-reciprocal Encoding
2017年的CVPR:《Re-ranking Person Re-identification with k-reciprocalEncoding》
論文:https://arxiv.org/abs/1701.08398v1
GitHub:https://github.com/zhunzhong07/person-re-ranking
Abstract
當將person re-ID看作一個檢索過程時,re-ranking是提高其準確性的關鍵步驟。然而,在re-ID社群中,對re-ranking的努力有限,尤其是那些全自動、無監督的解決方案。在本文中,我們提出了一種k-reciprocal編碼方法來re-ranking re-ID的結果。我們的假設是,如果一個gallery影象與k-reciprocal nearest neighbors中的probe查詢相似,則更有可能是真正的匹配。具體地,給定影象,通過將其k-reciprocal nearest neighbors編碼為單個向量來計算k-reciprocal特徵,該向量用於在傑卡德距離(Jaccard Distance:用來衡量兩個集合差異性的一種指標)下re-ranking。最終的距離計算為原始距離和傑卡德距離的組合。我們的re-ranking方法不需要任何人工互動或任何標記資料,因此適用於大規模資料集。在大型Market-1501、CUHK03、MARS和PRW資料集上的實驗證實了我們方法的有效性。
1. Introduction
person re-ID是計算機視覺中的一個具有挑戰性的課題。一般來說,re-ID可以被看作是一個檢索問題。給定一個probe person,我們希望在gallery中搜索包含處於跨相機模式下的相同行人的影象。在獲得初始排序列表之後,好的實踐包括新增re-ranking步驟,期望相關影象將獲得更高的排名。因此,本文將重點放在re-ranking問題上。
re-ranking主要是在通用例項檢索generic instance retrieval[5、14、34、35]中進行研究。許多re-ranking主方法的主要優點是它可以在不需要額外訓練樣本的情況下實現,並且可以應用於任何初始ranking結果。
re-ranking的有效性在很大程度上取決於初始ranking列表initial ranking list的質量。許多先前的工作利用了初始排序列表[5,14,34,35,43,44]中排名靠前的影象(例如k-最近鄰,k-nearest neighbors)之間的相似關係。一個基本的假設是,如果返回的影象在probe的k個最近鄰內排序,那麼它很可能是一個真正的匹配,可用於隨後的re-ranking。然而,情況可能偏離最佳情況:錯誤匹配很可能包括在probe的k個最近鄰中。例如,在圖1中,P1、P2、P3和P4是4個查詢圖probe的真實匹配,但是它們都不包括在top-4中。我們觀察到一些錯誤匹配(N1-N6)獲得高排名。結果,直接使用top-k的影象可能在re-ranking系統中引入噪聲並損害最終結果。

在文獻中,k-reciprocal nearest neighbor[14,34]是解決上述問題的有效方法,即被錯誤匹配汙染的top-k影象。當兩個影象被稱為k-reciprocal nearest neighbor時,當另一個影象作為probe時,它們都被排到top-k。因此,k-reciprocal nearest neighbor作為兩個影象是否正確匹配的更嚴格規則。在圖1中,我們觀察到probe是正確匹配影象的reciprocal neighbor,而不是錯誤匹配影象的reciprocal neighbor。該觀察識別初始排序列表initial ranking list中的正確匹配,以改善重新排序re-ranking結果。
基於以上考慮,本文提出了一種基於k-reciprocal編碼的re-ID re-ranking方法。我們的方法包括三個步驟。首先,將加權的k-reciprocal neighbor 集編碼為一個向量,形成k-reciprocal特徵。然後,兩個影象之間的Jaccard距離可以通過它們的k-reciprocal特徵來計算。其次,為了獲得更魯棒的k-reciprocal特徵,我們改進了一種區域性查詢擴充套件方法(a local query expansion approach),以進一步改善re-ID效能。最後,最終距離的計算為原始距離和Jaccard距離的加權集合。隨後,它被用來獲取re-ranking列表。所提出的方法的框架如圖2所示。綜上所述,本文的貢獻是:
- 我們提出了一個k-reciprocal特徵通過編碼k-reciprocal特徵到一個單一的向量。重re-ranking過程可以很容易地通過向量比較來執行。
- 我們的方法不需要任何人工互動或帶標註的資料,並且可以自動和無監督的方式應用於任何人person re-ID ranking結果。
- 該方法有效地提高了Market-1501、CUHK03、MARS和PRW等資料集上的person re-ID效能。特別地,我們在rank-1和mAP上實現了Market-1501的最先進的精度。

2. Related Work
我們推薦感興趣的讀者閱讀[3,50]以詳細回顧person re-ID。在此,我們重點研究用於目標檢索,特別是用於re-ID的re-ranking方法。
Re-ranking for object retrieval.
Re-ranking方法已被成功地研究以提高目標檢索精度[51]。許多工作利用k-nearest neighbors來探索相似關係來解決re-ranking問題。[5]提出了average query expansion (AQE)方法,該方法通過對top-k返回結果中的向量進行平均,得到一個新的查詢向量(query vector),用於對資料庫進行重新查詢。為了利用遠離查詢影象的負樣本,Arandjelović和Zisserman[1]改進了discriminative query expansion (DQE),使用線性SVM來獲得權重向量。從決策邊界的距離被用來修改初始排序表(initial ranking list)。[35]利用初始排序表的k-nearest neighbors作為新查詢(queries)來生成新的排序表。每個影象的新得分根據其在產生的排序表中的位置來計算。最近,稀疏上下文啟用sparse contextual activation (SCA)[2]提出將neighbor set編碼為向量,並通過廣義Jaccard距離來表示樣本的相似性。為了防止錯誤匹配對top-k影象的汙染,[14,34]中採用了k-reciprocal nearest neighbors的概念。在[14]中提出了上下文不相似性度量contextual dissimilarity measure (CDM),通過迭代正則化每個點到其鄰域的平均距離來細化相似性。[34]正式提出k-reciprocal nearest neighbors的概念。k-reciprocal nearest neighbors被認為是高度相關的候選,用於構造閉集(closed set)以re-ranking資料集的其餘部分。我們的工作從兩個方面背離了這兩個方法。我們不像文獻[14]那樣對最近鄰(nearest neighborhood)關係進行對稱化來細化相似度,也不像文獻[34]那樣直接將k-reciprocal nearest neighbors看作高階樣本。相反,我們通過比較兩幅影象的k-reciprocal nearest neighbors來計算它們之間的新距離。
Re-ranking for re-ID.
大多數現有的person re-ID方法主要集中於特徵表示[41,12,23,48,21]或度量學習[23,17,9,32,45]。最近,一些研究者[10,33,28,24,49,20,11,19,42,44]已經注意到在re-ID社群中基於re-ranking的方法。[20]通過分析每對影象的近鄰(near neighbors)的相關資訊和直接資訊,建立re-ranking模型。在[11]中,通過聯合考慮排序列表中的內容和上下文資訊,學習無監督的重新排序模型,有效地去除了模糊樣本,提高了re-ID的效能。[19]提出一種雙向排序(bidirectional ranking)方法,利用計算得到的新相似度作為內容相似度和上下文相似度的融合,對初始排序表進行修正。最近,利用不同基線(different baseline)方法的公共最近鄰來re-ranking任務[42,44]。[42]將全域性特徵和區域性特徵的公共最近鄰作為新查詢(queries),通過集合全域性特徵和區域性特徵的新排序列表來修改初始排序列表。在[44]中,利用k-nearest neighbor set從不同的baseline方法計算相似度和不相似度,然後進行相似度和不相似度的集合來優化初始排序表。上述方法在re-ranking方面繼續取得進展,有望為將來從k-nearest neighbors發現進一步的資訊作出貢獻。然而,使用k-nearest neighbors直接實現re-ranking可能限制整體效能,因為常常包括錯誤匹配。為了解決這個問題,本文研究了k-reciprocal neighbors在person re-ID中的重要性,從而設計了一個簡單而有效的re-ranking方法。
3. Proposed Approach
3.1. Problem Definition
給定查詢影象p和gallery set(包含N幅影象,G = {gi | i = 1, 2, ...N }),p和gi之間的原始距離可以用馬氏距離(Mahalanobis distance)衡量,
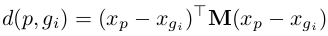
其中,xp個xg分別代表查詢圖p和檢測集gallery中gi的外觀特徵,M是半正定矩陣。
初始排序表
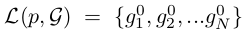
可根據probe p和gallery gi之間的成對原始距離得到,其中
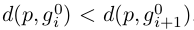
我們的目標是對L(p,G)進行re-rank,使更多的正樣本排在top列表中,從而提高person re-ID的效能。
3.2. K -reciprocal Nearest Neighbors
我們將N(p,k)定義為一個probe p的k-nearest neighbors(i.e. 排序列表的top-k samples):
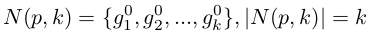
其中,|.|表示集合中候選的數目。k-reciprocal nearest neighbors R(p, k)可以定義為:
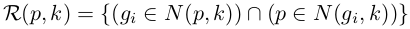
根據前面的描述,k-reciprocal nearest neighbors比k-nearest neighbors和probe p更相關。然而,由於照明、姿態、檢視和遮擋的變化,正樣本影象可能被從k-nearest neighbors中排除,並且隨後不被包括在k-reciprocal nearest neighbors中。為了解決這個問題,我們根據以下條件將R(p,k)中每個候選項的1/2 k-reciprocal nearest neighbors增量地新增到更魯棒的集合R*(p,k)中:
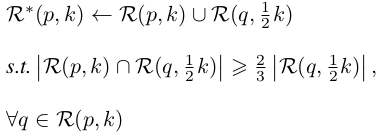
3.3. Jaccard Distance
3.4. Local Query Expansion
3.5. Final Distance
3.6. Complexity Analysis
4. Experiments
4.1. Datasets and Settings
4.2. Experiments on Market-1501
4.3. Experiments on CUHK03
4.4. Experiments on MARS
4.5. Experiments on PRW
4.6. Parameters Analysis
5. Conclusion
在本文中,我們解決person re-ID的re-ranking問題。通過將k-reciprocal nearest neighbors編碼為單個向量,我們提出了k-reciprocal特徵,從而可以通過向量比較容易地執行re-ranking過程。為了從相似樣本中獲取相似關係,提出了局部擴充套件查詢(local expansion query)以獲得更魯棒的k-reciprocal特徵。基於原始距離和Jaccard距離的組合的最終距離有效地提高了多個大規模資料集上的re-ID效能。值得一提的是,我們的方法是全自動和無監督的,並且可以很容易地實現任何ranking結果。