
魅族推送平臺架構及優化
魅族推送平臺架構及優化
內容簡介
平臺從支撐魅族內部業務到對外能力開放過程中一系列的系統架構優化及擴張,
支撐億級高併發訊息實時推送,包括服務高可用、監控、容災、流量排程、海量儲存等方面的實踐與探討。
平臺介紹
魅族推送平臺在2016年9月之後開始對外開放,目前接入的APP大概有2000+,日推送總量達到6億,
整個通道平臺推送的峰值可以達到600萬/分鐘,理論峰值在整個叢集部署架構下還可以在此基礎上翻一倍,
達到1200萬/分鐘。
架構與實踐
主要分為:推送平臺服務、魅族推送通道,基本流程是終端接入推送通道(TCP),
接入應用服務端通過推送平臺服務將訊息分流到推送通道,然後通過通道push到裝置端。
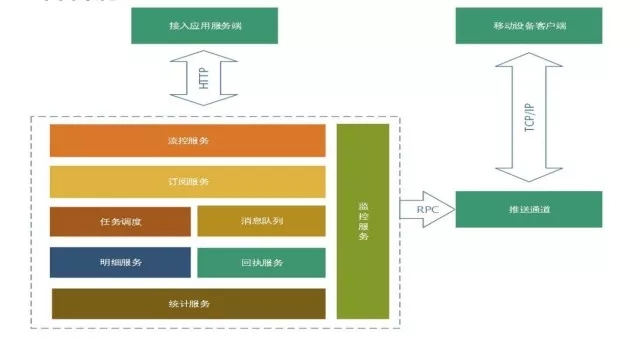
如圖所示,推送平臺的組成模組包括:
-
接入層的流控服務: 我們對推送流量的平衡和過載保護做了全域性的分散式流控服務。
-
訂閱服務: 簡單來說客戶端接入SDK之後上報的應用資料和標籤資料還有別名資料,都是在訂閱服務做儲存。
-
業務邏輯層: 有一個任務排程,主要是做訊息後臺任務推送的模組,我們做了一個高可用分片的任務推送。
-
訊息佇列服務: 共享和獨立通道。
-
訊息推送明細服務: 會將整個訊息推送流程鏈路全部上報到這個服務,這個服務的能力也是對外開放的,問題排查主要涉及這個服務。
-
訊息回執服務: 主要將推送訊息的到達和點選回執到第三方接入的應用服務。
-
平臺提供的實時統計服務
-
整個平臺的監控服務
微服務
2016年9月份之前,推送平臺的架構是高耦合的,只提供單獨對外接入和對內訊息推送的模組,
所有的訂閱、推送、分發都在一個模組裡。
開放之後我們對服務做了詳細拆分,除了前面提到的大的模組以外,我們還做了服務治理。
魅族有一個自己提供的RPC服務的框架,可以提供高質量的服務管理,對服務自動註冊、發現、監控等都有體現。
還有系統過程中的過載保護策略,
因為我們是面向大量訊息推送的平臺,對海量訊息推送,要對這個平臺的容災性做可靠性保障。
過載保護
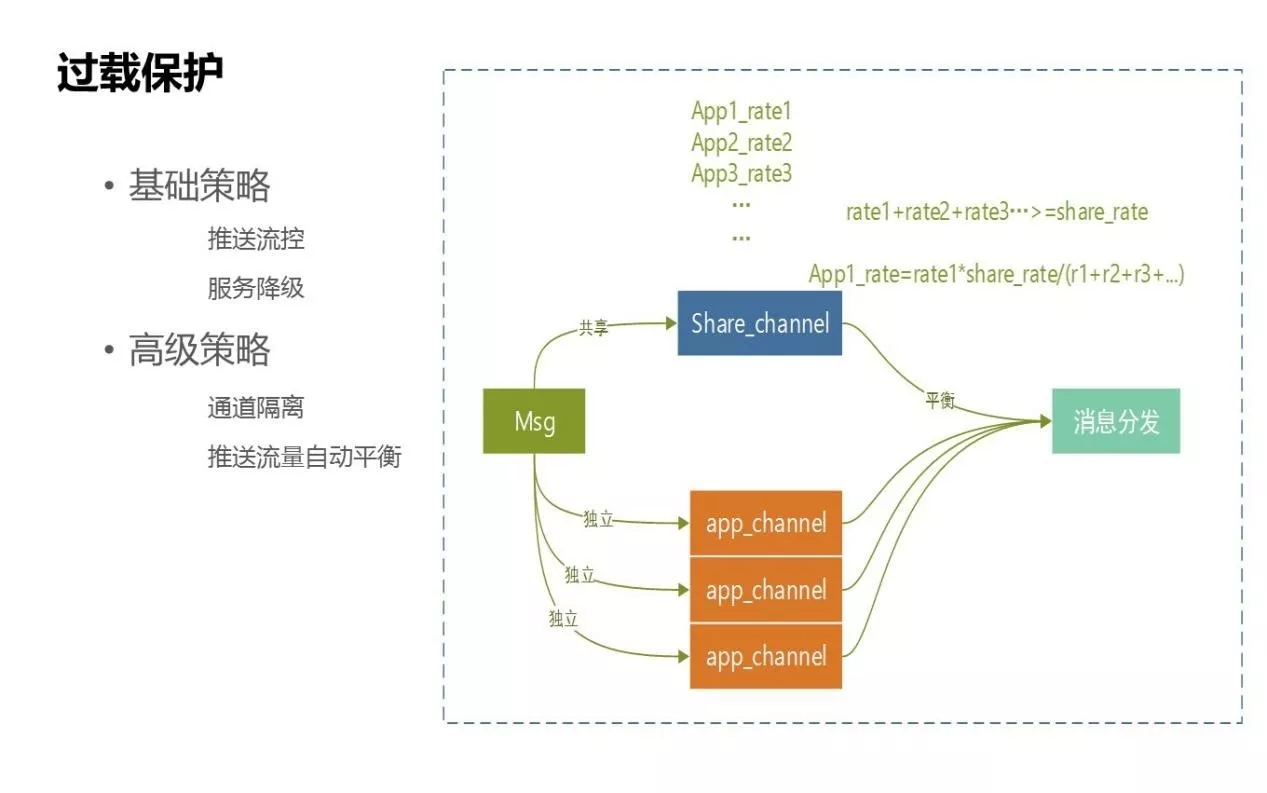
過載保護的策略分為兩種:基礎策略和高階策略。
- 基礎策略:
比如流控的控制,常用的是對IP訪問的阻斷、推送頻率的控制等,我們有這樣的基礎服務。還有一個基礎策略是服務降級,我們用了一些開源元件。
- 高階策略:
我們為過載訊息保護提供了通道,策略化主要是針對過載保護方面的,如圖所示是整個訊息下發到通道的吞吐量,比如高峰每秒鐘是20萬,要保證接入訊息後還能平衡後面的業務推送通道。
- 獨立通道:
針對的是APP級,每個APP會走獨立自主通道,每個通道的速率和資源都是隔離的,APP通道不會受其他APP之間推送速率的影響。我們一般會申請為優先順序高的應用配一個獨立通道。
- 共享通道:
是除了獨立通道之外的通道,其他APP也會走到共享通道。整個通道的併發能力是80萬/每秒。通過給通道劃分資源,為平衡速率,整個下來是不會超過上限的。比如目前有三個APP進入獨享通道,每個APP速率都是不一樣的,我們做了很簡單的速率平衡,當整個的速率大於通道設定的閾值,就會算出等比壓縮後每個APP的速率,保證三個APP對應的速率都不會超過整個通道的速率,以實現後端速率的過載保護。
有人會問,為什麼要在訊息這個地方做通道,而不是在流控的地方前置這個操作呢?
上游流控過載保護是指保護資源的流控限制,訊息下游服務推送保護的是下游通道的資源過載,
通過這兩個策略保證整個推送通道服務可用性。
熔斷利器-Hystrix
過載保護還用到了自動降級熔斷的元件,開源的Hystrix,這個元件對一個系統的熔斷保護首先關心的條件是系統什麼時候會觸發熔斷降級。
觸發的條件包括服務的健康度是否正常。服務健康度包括服務錯誤率、服務是否超時、超時是否超過設定的閾值比例,比如單位時間內達到20%,
我認為下游比例就是過高的,這時相當於觸發了熔斷條件。
初步處理。時間窗臨時禁止服務,在單位時間內,禁止對下游服務的呼叫,首先會保證當前服務的可用性,
不會出現由於通過下游服務的服務異常導致上游服務出現雪崩的情況。時間窗是臨時禁止的,下游服務會出現完全掛掉或不可提供服務的情況。
進一步處理分兩種。最簡單最直接的方式是服務降級,我們這邊對當前推送的訊息做了非同步處理,
當下遊通道服務不可用的情況下,能夠保證訊息不能丟失,等服務恢復正常,訊息繼續通過通道下發到裝置。
最粗暴的方式是直接拒絕當前服務呼叫的能力,把這個能力直接降級,這樣的方式只會在出現很嚴重的問題時才會採用,比如整個服務出現不可用情況。
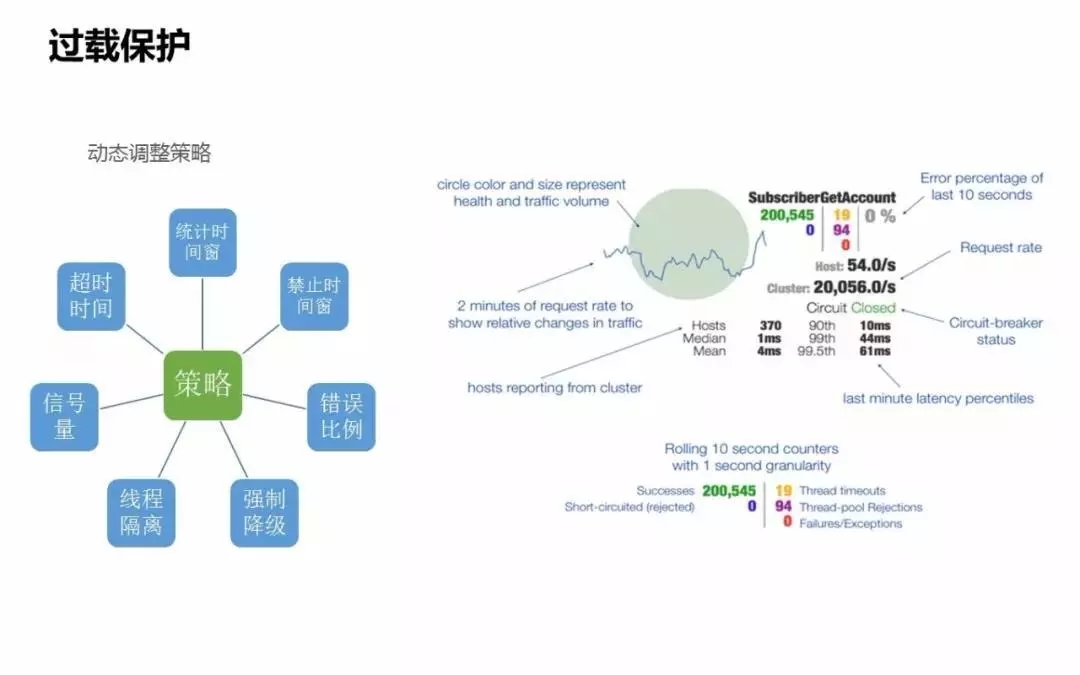
上圖是Hystrix提供的後臺監控表,它其實是服務健康度的大盤。大圈會實時顯示依賴服務的健康度,還有服務的名稱,通過健康度可以看到當前最關心的服務最近十秒鐘內的健康情況。
還有依賴服務的QPS,可以很明確看到依賴下游服務,當前的流量是達到了什麼峰值。
Hosts是有多少臺機器接入服務,像圖中的點顯示有370臺,表示上游部署了370臺機器或服務節點來接入下游服務,可以很明確看到服務的節點數。從側面也可以反饋到上游服務當前的服務健康度。
綠色的是當前依賴下游服務的健康度,這是一個熔斷過載的狀態,處於關閉的狀態,表示當前服務是正常的,沒有觸發熔斷。如果下游的服務達到熔斷策略的話,這個狀態會變成open狀態,提示服務傳送熔斷預警。
還有一些很細的指標可以體現整個健康度的狀態,下面還提供了很多對服務做隔離的指標,可以明確看到當前服務的健康度,有多少超時、多少被拒絕、多少執行失敗。
過載的策略化
- 超時時間:
一般是A服務到B服務,我們最關心的是服務之間的超時時間,上游服務依賴下游服務,如果呼叫時間超過3秒鐘,就認為下游服務是觸發到熔斷降級策略。
- 統計時間窗:
這裡有個錯誤百分比,要在一定的時間內計算出來,這個策略統計時間窗也可以是動態調整的。比如10秒鐘整個請求的呼叫通過是10%,我認為這個服務有質量問題,這是應該觸發降級狀態。
- 禁止時間:
降級之後緊接著是臨時禁止時間,禁止時間窗時間是可以設定的,比如可以設定成10秒鐘,當上下游服務依賴超過這個時間,在統計時間窗內錯誤百分比達到預設值,就禁止對下游服務的呼叫。這個呼叫是禁止使用的時間窗時間,比如禁止10秒鐘時間不再進行呼叫。
- 錯誤比例:
結合統計時間的策略,配置錯誤百分比,錯誤百分比也是可以動態配置的。
- 執行緒隔離:
服務到服務之間的隔離,這個服務裡可能有多個模組。如果想把A服務的呼叫跟B服務的呼叫做執行緒級別隔離,當A服務出現問題不會影響B服務的呼叫,可以設定當前服務用的是哪個執行緒棧,佇列大小是什麼。
- 強制降級:
如果出現熔斷策略觸發了降級,認為下游服務不可用的時候,需要開啟強制降級。可以人工在後臺通過配置對依賴服務做強制降級,這個降級狀態直接變成Open狀態,表示對下游服務的降級,從而能夠保障當前服務的依賴,避免由於雪崩情況的發生而導致服務不可用。
問題和心得
推送效能問題
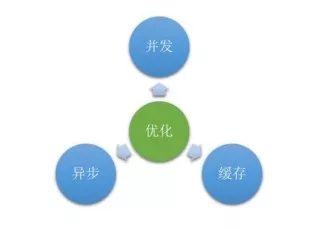
要做高效能就等於高併發或非同步,針對性能的提升無非也是從這三點觸發:怎麼提高系統的併發度、和系統的快取化、還有非同步。
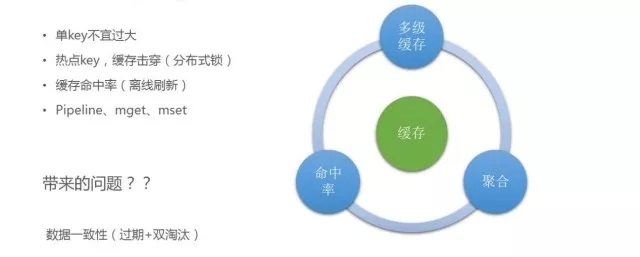
- 單key的問題:
當時做一個數據統計服務,我們設定的值過大,造成了資料劃分的偏移,對整個叢集的效能有很大影響,所以單key不宜設計過大,要做足夠精細化的拆分。
- 熱點key的問題:
快取key其實是使用率很高的key,但一般快取設定了過期機制,快取過期之後,大量請求會到下游儲存,比如DB層,這時整個系統的可靠性非常差。在快取命中的時候,整個介面提供的QPS達到理想值,當熱點key消失,大量請求擊穿到DB層,效能下降。我們用了一個分散式鎖,當多個服務要拿到熱點Key的時候,簡單加一個鎖,只有其中進來一個請求,才可以落地到DB,把資料重新載入到快取中,從而避免大量請求擊穿到DB層。
- 快取命中率的問題:
雖然系統做了快取化,但整個系統的快取命中率是比較低的,只有70%的命中率,因為快取過期,請求進來之後要把快取熱載入到快取中,這就有落地到DB的請求進來,導致整個快取命中率降低。我們的策略是對一些熱點key做離線定時重新整理,有一個後臺程序監測,如果key不在了,定時任務會把資料熱載入到快取中,從而提高快取命中率。我們通過這個機制將快取命中率從原來的70%多提高到了現在的99%。
在快取使用過程中,要儘量做到聚合。之前有一個訂閱服務,對當前推送目標是否有效都是通過快取來進行處理的,對服務可用性和效能要求特別高。我們可以達到10萬/秒,所有推送目標全部落到訂閱服務來校驗轉化,之前我們認為平臺的快取效能很高,粗暴地採用輪詢方式,後來發現當效率達到一定量級的時候對整個效能是有影響的,後來我們對於能夠聚合的操作提供pipeline機制。
用了快取不可避免會帶來資料一致性問題,萬一出現數據不一致,會對業務造成影響。
一方面我們做了時間有效期,敏感資料過期時間不能太長,比如只設置5-10分鐘,還要對它進行離線重新整理,保證資料一致性;
另一方面還有雙淘汰的策略。一般對快取資料與落地資料的更新,常規做法是我要更新一個數據,先把DB更新,再更新快取,在更新DB的時候已經有資料拿出去了,把快取中的資料清掉,上次拿掉沒有更新之前的資料,又會把之前的資料重新載入,這樣高併發的話很容易造成資料一致性問題。我們實行雙淘汰,更新前後對快取都做一次清理,達到資料一致性狀態。
- 併發:
之前在訊息推送時,嚴重依賴於MQ的佇列元件,佇列給我們提供的併發度是topic乘以分割槽數,存在的問題是:當推送訊息量達到高峰的時候,比如線上達到五萬,推送服務下發通道達到高峰,IO嚴重延遲,在不改變下游通道能力的前提下,要實現訊息推送只能提高併發,也就是要增加分割槽數。增加分割槽數又會帶來一個問題:增加分割槽會導致服務端的過載能力過高,導致佇列叢集負載高。我們把業務的整個併發度改成topic乘以執行緒池,最簡單的就是在每次註冊topic的時候,對單個topic做執行緒池的繫結。
這裡修改完之後,我們在線上又發現了一個問題:推送過程中,整個訊息的吞吐量已經上來了,服務重啟的時候,所有訊息拉取到本地之後其實是在內重啟的,內重啟會導致訊息丟失,這是不能容忍的。因此我們在服務重啟的時候加了一個執行緒hook,可以對整個topic拿到的訊息做一個停止,不再拉取新的訊息,等執行緒池裡全部訊息到手機終端,才會終止服務,從而保證在記憶體級別的訊息不丟失。
還有一個缺點,服務如果出現非正常退出,比如機器掛了或者程序突然消失,記憶體級別的資料也會處於丟失狀態,所以執行緒池的佇列要在滿足訊息推送的總能力下設定得儘可能合理來規避這個問題。
-
海量資料明細儲存問題:
-
明細佇列資料積壓:
海量資料流轉的時候是上到佇列,通過佇列寫入hbase,但高峰的時候仍然有資料積壓,比如一條訊息推送,我們會發訊息到明細日誌裡,如果客戶點選了,我們又會把訊息寫入佇列,整個訊息的聚合度是不夠的,到了後端hbase都是根據上報粒度寫的,基本上是一條一條寫,這時在上報過程中做了訊息的壓縮,在每個服務拿到訊息之後都做了佇列壓縮,跟上面提到的問題一樣,要注意服務重啟的時候,佇列裡面的資料也會結合資料重啟。
-
hbase rowkey熱點問題:
裝置標識IMEI,每個IMEI都是有規則的,比如以8600開頭的規則。我們是用rowkey,導致了寫入叢集的時候出現數據熱點,海量資料都到一個點對叢集的效能也有很大影響,這時要解決熱點問題。我們對裝置做一個逆序,在此基礎上再根據叢集做簡單的雜湊,追加到寫入的key前,基本上就可以保證寫入的資料能夠均勻落到後端hbase服務的每個節點上,從而保障整個叢集的可用性。
-
監控和灰度釋出
監控
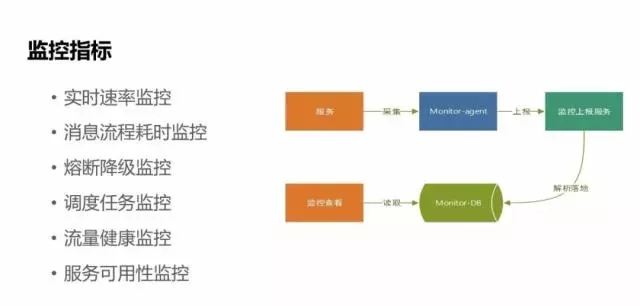
-
實時速率監控:
能夠實時看到應用在系統中推送的一天流量變化峰值,預判推送服務的可靠性。
-
訊息推送流程的耗時監控:
每套訊息的整個推送流程可能涉及到幾百個服務,我們在每個服務之間的耗時都做了很詳細的埋點監控。
-
熔斷降級監控和推送任務排程監控:
如果有失敗,我們會有監控點上報通知。
-
流量健康監控:
針對到每個APP的健康指標監控。
-
服務可用性監控:
對服務指標的採集流程也是比較簡單的,只是服務來上報指標,通過監控政策來上報統一到監控服務,然後監控服務對這些指標進行監控檢視,如果觸發監控指標,通過指標庫來做預警。
灰度釋出
灰度主要針對三個點:
-
流量灰度: 通過自動化運維平臺實現;
-
APP灰度:
-
裝置灰度: 可以針對固定的裝置或者某一機型裝置來做灰度釋出。
魅族在釋出方面已經有容器化平臺,很明顯的特點是可以做到線上自動化擴容縮容。