
【spring cloud】spring cloud Sleuth 和Zipkin 進行分散式鏈路跟蹤
spring cloud 分散式微服務架構下,所有請求都去找閘道器,對外返回也是統一的結果,或者成功,或者失敗。
但是如果失敗,那分散式系統之間的服務呼叫可能非常複雜,那麼要定位到發生錯誤的具體位置,就是一個比較麻煩的問題。
所以定位故障點,就引入了spring cloud Sleuth【Sleuth是獵犬的意思】 和Zipkin 【zipkin是一款開源的分散式資料跟蹤系統】。
Spring Cloud Sleuth是對Zipkin的一個封裝,對於Span、Trace等資訊的生成、接入HTTP Request,以及向Zipkin Server傳送採集資訊等全部自動完成。
最後,你可以在zipkin的UI上看到一個比較完善的追蹤結果和分析。
Zipkin提供了可插拔資料儲存方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下來的測試為方便直接採用In-Memory方式進行儲存,生產推薦Elasticsearch。
一 、下面開始spring cloud整合步驟
【GitHub原始碼地址:https://github.com/AngelSXD/springcloud】
版本介紹:
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <java.version>1.8</java.version> <spring-boot.version>2.0.4.RELEASE</spring-boot.version> <spring-cloud.version>Finchley.SR1</spring-cloud.version> <lcn.last.version>4.2.1</lcn.last.version> </properties>
1.建立ms-sleuth-zipkin 子服務,新增pom.xml架包依賴【標紅部分,你們可以不需要,我的demo里正好需要才加的】
<!-- zipkin服務端 --> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> <version>2.10.1</version> <!--排除--> <exclusions> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> </exclusion> </exclusions> </dependency> <!-- zipkin UI展示 --> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <version>2.10.1</version> </dependency>
2.啟動類加註解
package com.swapping.springcloud.ms.sleuth.zipkin; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cloud.netflix.eureka.EnableEurekaClient; import zipkin.server.internal.EnableZipkinServer; //啟用Zipkin服務 @EnableZipkinServer @EnableEurekaClient @SpringBootApplication(scanBasePackages = {"com.swapping"}) public class SpringcloudMsSleuthZipkinApp { public static void main(String[] args) { SpringApplication.run(SpringcloudMsSleuthZipkinApp.class, args); } }
3.配置檔案中配置基礎的配置即可【如果啟動zipkin之後,無法訪問或者報錯,參考:https://www.cnblogs.com/sxdcgaq8080/p/10007735.html】
spring.application.name=springcloud-ms-sleuth-zipkin server.port=8002 eureka.client.service-url.defaultZone=http://127.0.0.1:8000/eureka/
#zipkin啟動報錯無法訪問的解決方法
management.metrics.web.server.auto-time-requests=false
4.然後依次啟動eureka服務,和zipkin服務即可
訪問地址:【注意最後需要帶上/】
http://localhost:8002/zipkin/
可以看到頁面
5.接著,就是需要在zipkin自己服務中,和各個需要開啟鏈路跟蹤的服務的配置檔案中新增配置 ,並且新增pom依賴
我是載入父級pom中,這樣所有子module都可以用
<!-- zipkin 支援 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
配置【注意,spring boot 1.X的取樣率配置是spring.sleuth.sampler.percentage=1】
【我在zipkin服務、ms-member服務、ms-gateway服務、ms-integral都做了新增】
#在需要鏈路的服務 以及 zipkin服務新增配置
spring.zipkin.base-url=http://localhost:8002
#採集率
spring.sleuth.sampler.probability=1.0
關於取樣率的解釋:
Spring Cloud Sleuth有一個Sampler策略,可以通過這個實現類來控制取樣演算法。取樣器不會阻礙span相關id的產生,但是會對匯出以及附加事件標籤的相關操作造成影響。 Sleuth預設取樣演算法的實現是Reservoir sampling,具體的實現類是PercentageBasedSampler,預設的取樣比例為: 0.1(即10%)。不過我們可以通過spring.sleuth.sampler.percentage來設定,所設定的值介於0.0到1.0之間,1.0則表示全部採集。
但是如果是全部採集的話,儲存的效能需要考慮一下。
6.測試
ms-member有一個save的介面,自己做了save操作,並且feign呼叫了ms-integral服務做了save操作。【並且在最終ms-member中返回結果之前,丟擲一個除零異常】
啟動eureka
啟動閘道器ms-gateway
啟動ms-zipkin
啟動ms-member
啟動ms-integral
那麼請求的流程就是 閘道器(ms-gateway)---->ms-member--->ms-integral 【每一個結點採集到的資訊會由Sleuth 傳送給zipkin服務】
訪問地址:
http://localhost:8001/v1/ms-member/member/save?auth=111
訪問介面完成後,訪問zikpin的UI
http://localhost:8002/zipkin/
然後選擇檢視ms-gateway服務
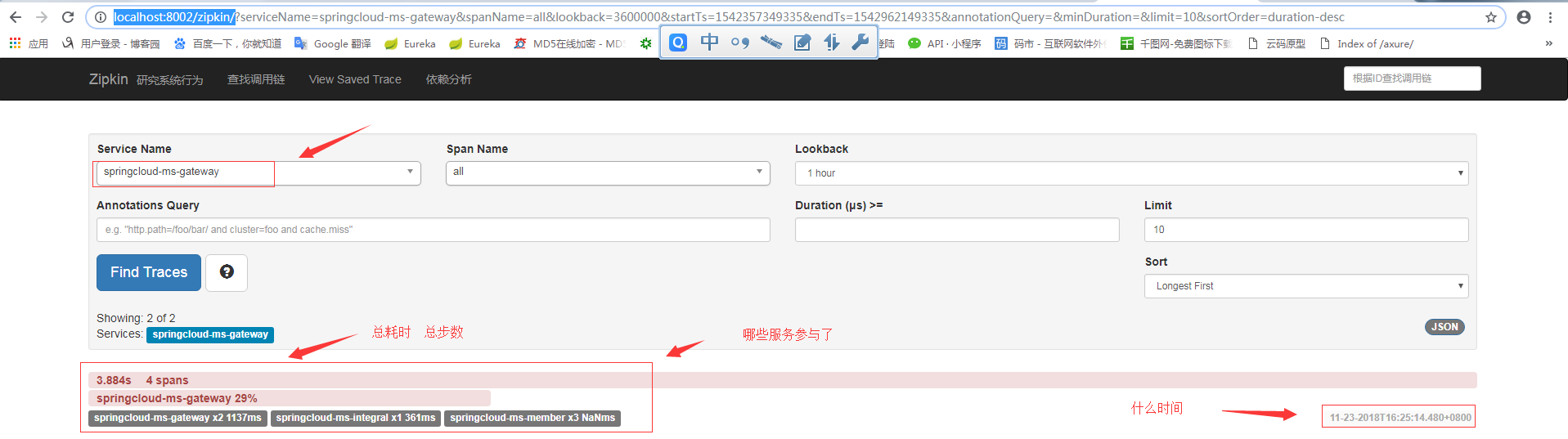
點選進去:
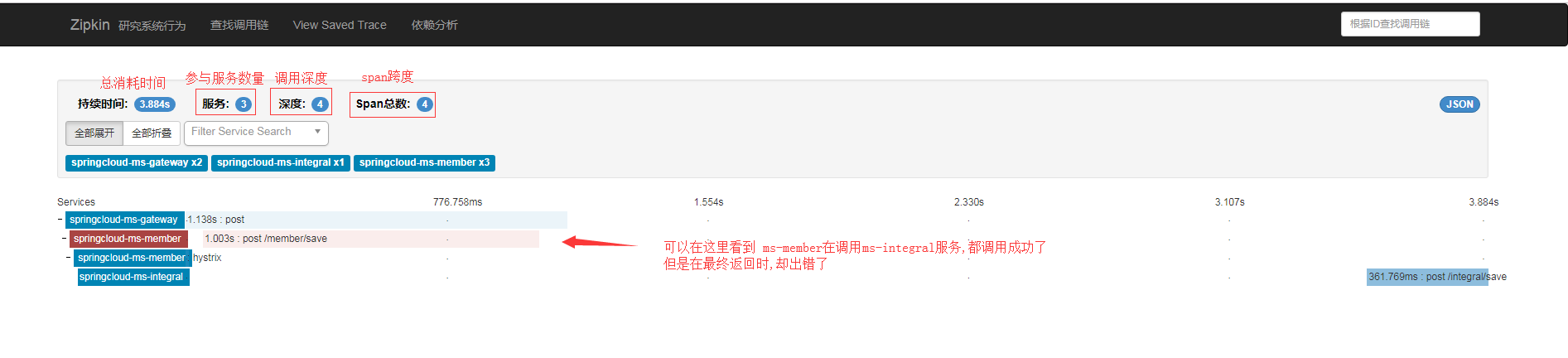
從進入gateway開始看,也就是請求的第一步:
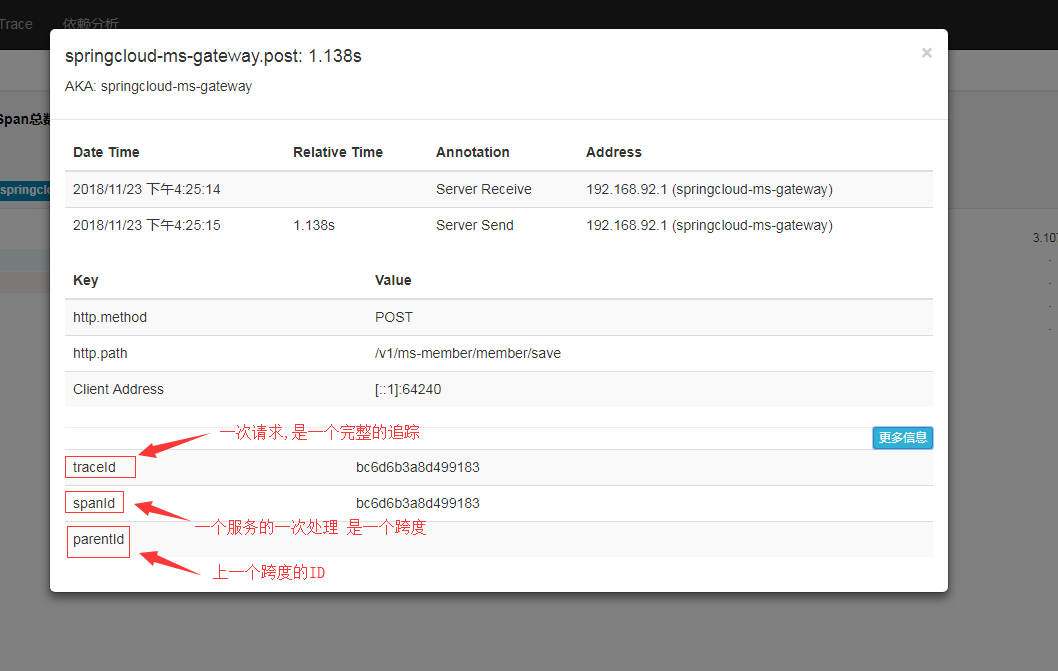
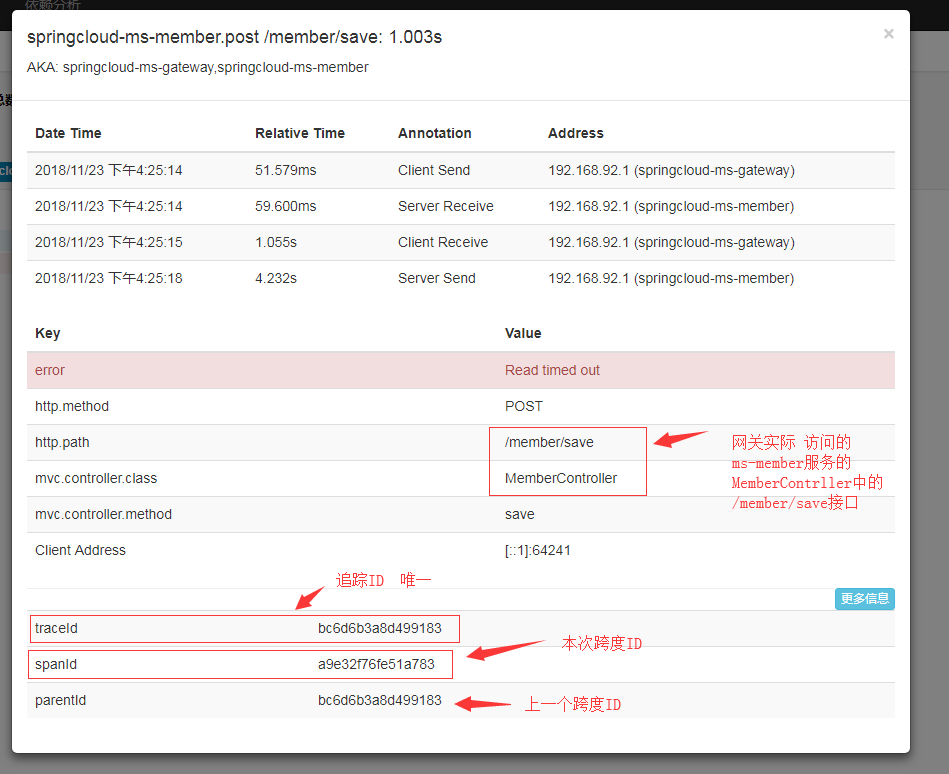
同時還可以看到:
點選依賴分析,還可以看到呼叫關係

二、Zipkin整合elasticsearch