
Spring Cloud(十三) Sleuth和Zipkin分散式鏈路跟蹤
Spring Cloud(十三) Sleuth和Zipkin分散式鏈路跟蹤
隨著業務發展,系統拆分導致系統呼叫鏈路愈發複雜一個前端請求可能最終需要呼叫很多次後端服務才能完成,當整個請求變慢或不可用時,我們是無法得知該請求是由某個或某些後端服務引起的,這時就需要解決如何快讀定位服務故障點,以對症下藥。於是就有了分散式系統呼叫跟蹤的誕生。
現今業界分散式服務跟蹤的理論基礎主要來自於 Google 的一篇論文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,使用最為廣泛的開源實現是 Twitter 的 Zipkin,為了實現平臺無關、廠商無關的分散式服務跟蹤,CNCF 釋出了布式服務跟蹤標準 Open Tracing。國內,淘寶的“鷹眼”、京東的“Hydra”、大眾點評的“CAT”、新浪的“Watchman”、唯品會的“Microscope”、窩窩網的“Tracing”都是這樣的系統。
Spring Cloud Sleuth
一般的,一個分散式服務跟蹤系統,主要有三部分:資料收集、資料儲存和資料展示。根據系統大小不同,每一部分的結構又有一定變化。譬如,對於大規模分散式系統,資料儲存可分為實時資料和全量資料兩部分,實時資料用於故障排查(troubleshooting),全量資料用於系統優化;資料收集除了支援平臺無關和開發語言無關係統的資料收集,還包括非同步資料收集(需要跟蹤佇列中的訊息,保證呼叫的連貫性),以及確保更小的侵入性;資料展示又涉及到資料探勘和分析。雖然每一部分都可能變得很複雜,但基本原理都類似。
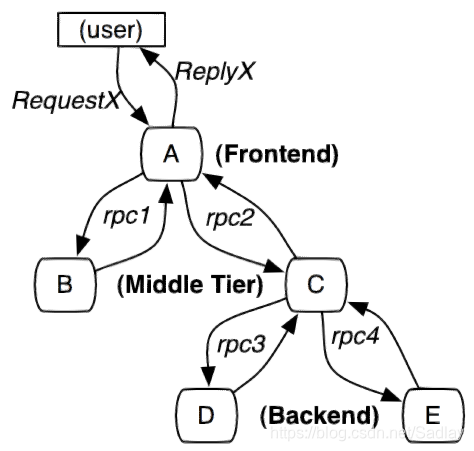
服務追蹤的追蹤單元是從客戶發起請求(request)抵達被追蹤系統的邊界開始,到被追蹤系統向客戶返回響應(response)為止的過程,稱為一個“trace”。每個 trace 中會呼叫若干個服務,為了記錄呼叫了哪些服務,以及每次呼叫的消耗時間等資訊,在每次呼叫服務時,埋入一個呼叫記錄,稱為一個“span”。這樣,若干個有序的 span 就組成了一個 trace。在系統向外界提供服務的過程中,會不斷地有請求和響應發生,也就會不斷生成 trace,把這些帶有span 的 trace 記錄下來,就可以描繪出一幅系統的服務拓撲圖。附帶上 span 中的響應時間,以及請求成功與否等資訊,就可以在發生問題的時候,找到異常的服務;根據歷史資料,還可以從系統整體層面分析出哪裡效能差,定位效能優化的目標。
Spring Cloud Sleuth為服務之間呼叫提供鏈路追蹤。通過Sleuth可以很清楚的瞭解到一個服務請求經過了哪些服務,每個服務處理花費了多長。從而讓我們可以很方便的理清各微服務間的呼叫關係。此外Sleuth可以幫助我們:
- 耗時分析: 通過Sleuth可以很方便的瞭解到每個取樣請求的耗時,從而分析出哪些服務呼叫比較耗時;
- 視覺化錯誤: 對於程式未捕捉的異常,可以通過整合Zipkin服務介面上看到;
- 鏈路優化: 對於呼叫比較頻繁的服務,可以針對這些服務實施一些優化措施。
spring cloud sleuth可以結合zipkin,將資訊傳送到zipkin,利用zipkin的儲存來儲存資訊,利用zipkin ui來展示資料。
這是Spring Cloud Sleuth的概念圖:
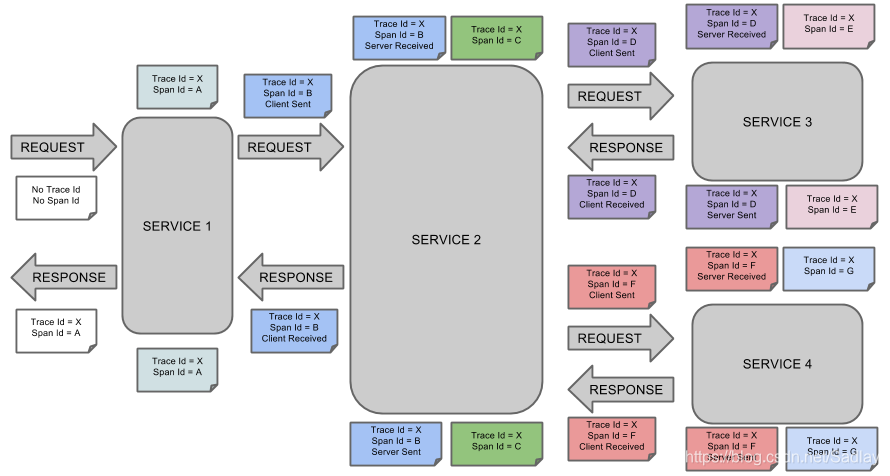
ZipKin
Zipkin 是一個開放原始碼分散式的跟蹤系統,由Twitter公司開源,它致力於收集服務的定時資料,以解決微服務架構中的延遲問題,包括資料的收集、儲存、查詢和展現。
每個服務向zipkin報告計時資料,zipkin會根據呼叫關係通過Zipkin UI生成依賴關係圖,顯示了多少跟蹤請求通過每個服務,該系統讓開發者可通過一個 Web 前端輕鬆的收集和分析資料,例如使用者每次請求服務的處理時間等,可方便的監測系統中存在的瓶頸。
Zipkin提供了可插拔資料儲存方式:In-Memory、MySql、Cassandra以及Elasticsearch。接下來的測試為方便直接採用In-Memory方式進行儲存,生產推薦Elasticsearch。
快速上手
建立zipkin-server專案
專案依賴
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
</dependencies>
啟動類
@SpringBootApplication
@EnableEurekaClient
@EnableZipkinServer
public class ZipkinApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinApplication.class, args);
}
}
使用了@EnableZipkinServer註解,啟用Zipkin服務。
配置檔案
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka/
server:
port: 9000
spring:
application:
name: zipkin-server
配置完成後依次啟動示例專案:spring-cloud-eureka、zipkin-server專案。剛問地址:http://localhost:9000/zipkin/可以看到Zipkin後臺頁面
專案新增zipkin支援
在專案spring-cloud-producer和spring-cloud-zuul中新增zipkin的支援。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
Spring應用在監測到Java依賴包中有sleuth和zipkin後,會自動在RestTemplate的呼叫過程中向HTTP請求注入追蹤資訊,並向Zipkin Server傳送這些資訊。
同時配置檔案中新增如下程式碼:
spring:
zipkin:
base-url: http://localhost:9000
sleuth:
sampler:
percentage: 1.0
spring.zipkin.base-url指定了Zipkin伺服器的地址,spring.sleuth.sampler.percentage將取樣比例設定為1.0,也就是全部都需要。
Spring Cloud Sleuth有一個Sampler策略,可以通過這個實現類來控制取樣演算法。取樣器不會阻礙span相關id的產生,但是會對匯出以及附加事件標籤的相關操作造成影響。 Sleuth預設取樣演算法的實現是Reservoir sampling,具體的實現類是PercentageBasedSampler,預設的取樣比例為: 0.1(即10%)。不過我們可以通過spring.sleuth.sampler.percentage來設定,所設定的值介於0.0到1.0之間,1.0則表示全部採集。
這兩個專案新增zipkin之後,依次進行啟動。
進行驗證
這樣我們就模擬了這樣一個場景,通過外部請求訪問Zuul閘道器,Zuul閘道器去呼叫spring-cloud-producer對外提供的服務。
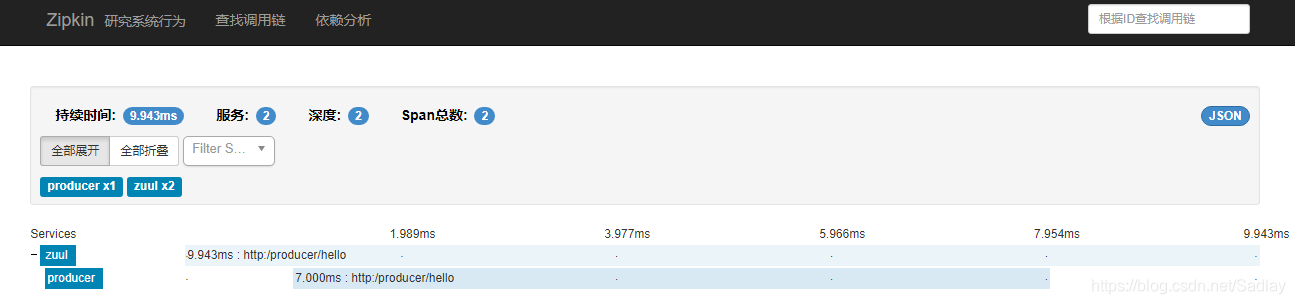
四個專案均啟動後,在瀏覽器中訪問地址:http://localhost:8888/producer/hello?name=neo 兩次,然後再開啟地址:http://localhost:9000/zipkin/點選對應按鈕進行檢視。
點選查詢看到有兩條記錄
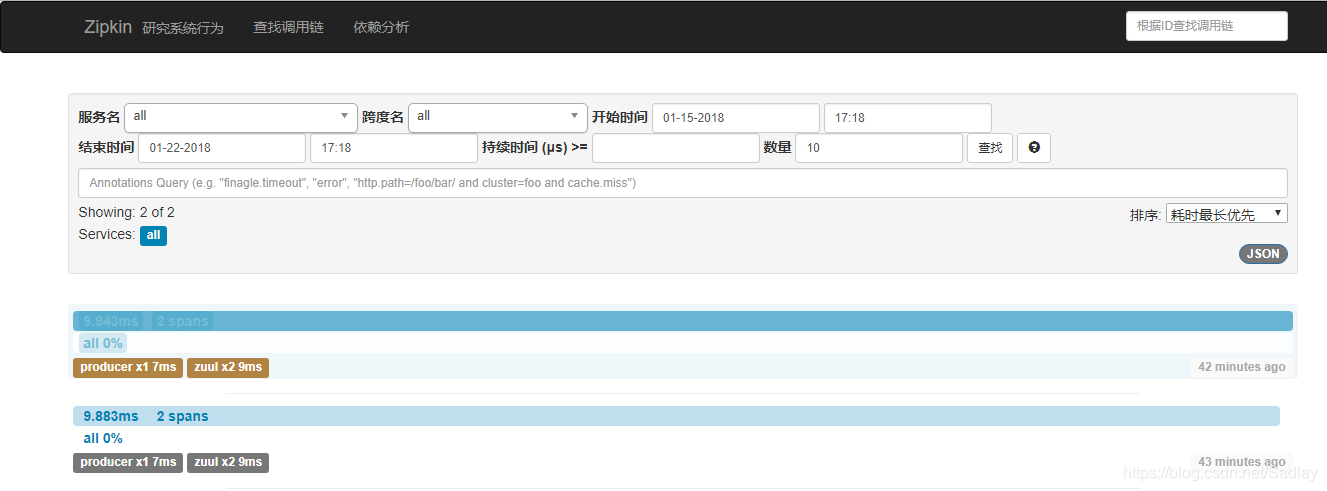
點選記錄進去頁面,可以看到每一個服務所耗費的時間和順序
點選依賴分析,可以看到專案之間的呼叫關係
