
Machine Learning筆記整理 ------ (二)訓練集與測試集的劃分
1. 留出法 (Hold-out)
將資料集D劃分為2個互斥子集,其中一個作為訓練集S,另一個作為測試集T,即有:
D = S ∪ T, S ∩ T = ∅
用訓練集S訓練模型,再用測試集T評估誤差,作為泛化誤差估計。
特點:單次使用留出法得到的估計結果往往不夠穩定可靠,故如果要使用留出法,一般採用若干次隨機劃分,重複進行實驗評估後,取平均值作為最終評估結果。
比例:S = 2/3 ~ 4/5 D,T = 1/3 ~ 1/5 D
2. 交叉驗證法 (Cross validation)
將資料集D劃分為k個大小相似的互斥子集,即:
D = D1 ∪ D2
有:Di ∩ Dj=∅,每個子集Dr都儘可能保持資料分佈的一致性,即:從D中通過分層取樣得到,每次使用k-1個子集的並集作為訓練集S,餘下的一個作為測試集T,最終返回的是k個測試結果的均值。因其穩定性與保真性取決於k值,故又稱為k折交叉驗證 (K-fold cross validation),其中k最常用取值為10,又稱10折交叉驗證。

當k等於樣本數量時,得到k折交叉驗證的特例:留一法 (Leave-One-Out, LOO)。
特點:當資料集D中資料量較大時,訓練m個模型的開銷過大。
1 #!/usr/bin/env python3 2 3 # 使用10折交叉驗證來劃分Iris資料集的訓練集、測試集 4 from sklearn.cross_validation import KFold 5 6 # 引數n_splits決定了k值,即折數 7 kf = KFold(len(iris.y), n_splits = 10, shuffle = True) 8 9 for train_index, test_index in kf: 10 x_train, x_test = iris.x[train_index], iris.x[test_index] 11 y_train, y_test = iris.y[train_index], iris.y[test_index]12 13 x_train.shape, x_test.shape, y_train.shape, y_test.shape
輸出結果: ((135, 4), (15, 4), (135, ), (15, ))
或者,其實自己用的更多的是下面一種:
1 #! /usr/bin/env python3 2 3 from sklearn.cross_validation import train_test_split 4 import numpy as np 5 6 filename = '檔案路徑' 7 8 # 引數delimiter是資料集中屬性間的分隔符 9 data_set = np.loadtxt(filename, delimiter = ';') 10 11 # 假定該資料集中的屬性數目為11,標記label位於資料集的最後一列 12 x = data_set[:, 0:11] 13 y = data_set[: 11] 14 15 # 劃分比例為8:2 16 x_train, y_train, x_test, y_test = train_test_split(x, y, test_size = 0.2) 17 18 x_train.shape, y_train.shape, x_test.shape, y_test.shape
輸出結果: ((16497, 11), (16497,), (4125, 11), (4125,))
3. 自助法 (Bootstrapping)
以自助取樣為基礎 (Boostrap sampling),給定包含m個樣本的資料集D,對D進行取樣,產生資料集D':每次隨機從D中挑選一個樣本,拷貝後放入D',再講該樣本放回D中,使得該樣本在下次取樣時仍然有可能被採集到。重複該過程m次,即可得到包含m個樣本的資料集D',這就是自助取樣的結果。顯然,部分樣本會多次出現,而另一部分則不會,在m次取樣中,始終不被採集到的概率為 (1-1/m)m,即:
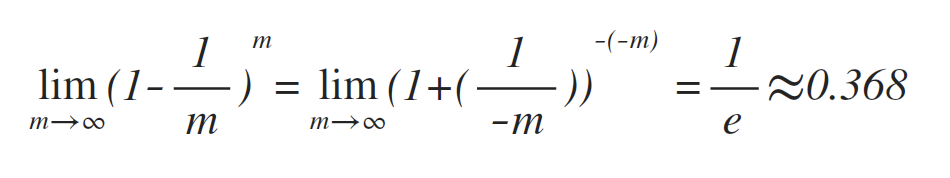
故D中有約36.8%的樣本不會出現在D'中,所以將D'用作訓練集S,D\D'用作測試集T,這樣仍有約36.8%的資料樣本不在訓練集內,可以用作測試集進行測試。
特點:適用於資料集D中資料量較小時,難以劃分訓練集、測試集時使用。