
oracle 本人與其他所有人認識的SQL
首先新建測試表
1 create table DIM_IA_TEST6 2 ( 3 NAME VARCHAR2(20), 4 OTHERNAME VARCHAR2(20) 5 )
插入資料
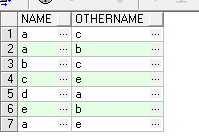
--如果沒有重複的記錄,則不用去重
使用union all實現,第一列(name)人與其他所有人都認識的sql:
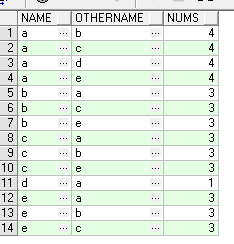
select name,othername,count(othername)over(partition by name) nums from (select name,othername from (select name,othername fromDIM_IA_TEST6 union all select othername name,name othername from DIM_IA_TEST6)t group by name,othername)
結果顯示name與所有人認識的結果(nums為認識人數):
相關推薦
oracle 本人與其他所有人認識的SQL
首先新建測試表 1 create table DIM_IA_TEST6 2 ( 3 NAME VARCHAR2(20), 4 OTHERNAME VARCHAR2(20) 5 ) 插入資料 --如果沒有重複的記錄,則不用去重使用union all實現,第一列(name)人
oracle 12c與其他版本的幾點區別
1、oracle12c 增加CDB和PDB的概念,CDB簡稱資料庫容器,裡面可以建立多個虛擬的相互隔離的PDB資料庫,因此擁有云計算機的功能,實現對雲資料庫的支援;PDB簡稱可插拔資料庫,類似於之前版本的一對一或多對一關係(PAC)資料庫。2、建立使用者的sql語句不同,之前
MySQL、SQL server 、Oracle資料庫中查詢所有的資料庫,查詢指定資料庫所有表名,查詢所有的欄位的名字
MySQL中查詢所有資料庫名和表名 1.查詢所有資料庫 show databases; 2.查詢指定資料庫中所有表名 select table_name from information_schema.tables where table_schema='database_name' a
支援kubernetes原生Spark 與其他應用的結合(mysql,postgresql,oracle,hdfs,hbase)
安裝執行支援kubernetes原生排程的Spark程式:https://blog.csdn.net/luanpeng825485697/article/details/83651742 dockerfile的目錄 . ├── driver │ └── Dockerfile
Oracle資料庫與PL/SQL Developer客戶端的安裝
使用PLSQL Developer出現錯誤:Initialization error SQL*Net not properly installed 原因:32位的PL/SQL Developer需要搭配32位的Oracle資料庫,你可能安裝了64位的資料庫 Oracle
oracle 與 mysql批量插入的 sql 總結
mysql 方案一:帶列名 INSERT INTO example (example_id, name, value, other_value) VALUES (100, 'Name 1', 'Value 1', 'Other 1'), (101,
Oracle 10g與SQL Server 2008互聯之透明閘道器配置
舊系統使用Oracle,新系統使用SQL Server,使用透明閘道器將舊系統的資料通過觸發器更新到新系統中去。 一、環境 A: Oralce DB Server OS: CentOS 6.4
Oracle與Mysql等資料庫通用SQL優化技巧
a. 資料表的處理順序 oracle 在解析一個查詢語句FROM後面的一系列資料表是按照從右往左的順序進行的.也就是說最後的資料表將是最先被oracle處理的,所以我們在寫多個表關聯的查詢語句時,把資料量最小的表或者是經過條件篩選後得到資料量最小的表放到最後,資料量大的表就放在最前面. select col1
認識Vue.js+Vue.js的優缺點+和與其他前端框架的區別
首先,我們先了解什麼是MVX框架模式?MVX框架模式:MVC+MVP+MVVM1.MVC:Model(模型)+View(檢視)+controller(控制器),主要是基於分層的目的,讓彼此的職責分開。View通過Controller來和Model聯絡,Controller是V
ORACLE查詢某個時間之前的記錄,與現在的記錄的sql
記錄一下,防止自己忘記 -- 查詢的是現在的某條記錄 與 3分鐘之前這條記錄的資料 select * from sysuser where id ='fa5224f9024d431c
高階SQL優化(二) ——《12年資深DBA教你Oracle開發與優化——效能優化部分》
u正確合適的索引是查詢優化效能的首選 u索引是表的索引列排序後的小型化拷貝,會增加儲存開銷,因此會帶來Insert、Update、Delete的額外開銷 u一個表可以有一個索引,也可以有多個索引,往往過多的索引或不恰當的索引帶來的負面性能更多 u表索引的設計初衷,往往在40%甚至更高的情況下與最終的實
MySql中SQL語句與其他資料庫不一樣的地方
目前發現的mysql與其他資料庫如SqlServer、Oracle不同的地方 mysql中的註釋(--)後要多加一個空格才生效 mysql中查詢條件的字串可以是雙引號 mysql中查詢條件的字串不區分大小寫 mysql中不能按拼音排序,要將資料庫的字符集由UTF-8修改為GBK mysql中有更簡單的分頁方法
資料應用達人之SQL基礎教程分享6-比較與邏輯操作
第三章 SQL裡的操作符-條件查詢 (SQL裡有很多操作符,它們都是用來滿足SQL查詢的,特別是為WHERE語句指定條件所使用,所以本章我們會結合WHERE語句的使用對SQL的操作符一一進行講解) 1.比較操作 比比才知道 1、研究植物的學生—等於、不等 【知識
高階SQL優化(三) 常用優化工具 ——《12年資深DBA教你Oracle開發與優化——效能優化部分》
1.AUTOTRACE簡介 AUTOTRACE是SQL*Plus的一項功能,其作用是自動跟蹤SQL語句,為SQL 語句生成一個 執行計劃並且提供與 該語句的處理有關的統計資訊。 SQL*Plus AUTOTRACE 可以用來替代 SQL Trace 使用,AUTOTRACE 的好處是不必設定跟蹤檔案
高階SQL優化(一) ——《12年資深DBA教你Oracle開發與優化——效能優化部分》
使用基於規則的優化器(CBO)時,Oracle解析器按照從右到左的順序處理FROM子句的表明,即FROM子句中最後的表(驅動表)會最先被處理。 當FROM子句包含多個表時,建議將記錄最少的表(一般是字典表)放在最後面。當Oracle處理多個表時,一般採用排序或合併的方式連線這些表,系統首先會掃描FR
關於前增量與後增量的認識誤區
i++ ++i 前增量 後增量大學時老師講C++時說過, x=i++; 與 x=++i 的區別當時以為很懂了,一個是後增量,一個是前增量x= i++; 相當於 x=i ; i=i+1;x=++i ; 相當於 i=i+1; x=i ; 並對這種解釋深信不疑。近日 微信群看到一則題目,甚是困惑,
Oracle備份與恢復
ron 還原 類型 修改 文件拷貝 per esp 主機數 segment 步驟:(面試) 1,在新主機DBCA建庫,實例名和原主機數據庫名一致2,在新主機創建用戶3,dbms_metadata.get_ddl導出表空間生成語句4,在新主機創建表空間5,exp導出原庫全部數
php與其他一些相關工具的安裝步驟分享
you 記錄 有道 工具 nbsp 寫博客 安裝php inux ref 現在很少花時間來專門寫博客,都是把平時看到用到的東西像隨筆一樣記錄在雲筆記上。 在這兒分享一些php相關的技術安裝過程: linux下編譯安裝php:php安裝 phpunit安裝過程:phpuni
RHEL6.5上Oracle ACFS與Linux samba一起使用時遇到的bug
perf out back through sam cli 一個 ora general RHEL上的Oracle ACFS與linux samba一起使用時遇到的bug 一、環境介紹: cat /etc/issue的結果為: Red Hat Enterpri
《象與騎象人聽書筆記》
理解 nbsp 說明 日子 異常 新的 稻盛和夫 層次 人的 人們會因為偶爾的小毛病而異常難受,而對大多數平常日子裏的活蹦亂跳卻毫無知覺。現代科學發現佛陀“放下身外之物”的觀點也不夠全面,因為確實有少數的身外之物能夠給我們帶來持續的幸福,值得我們追求