python初識05-檔案處理
檔案是作業系統中的一個虛擬概念。檔案是以計算機硬碟為載體儲存在計算機上的資訊集合,檔案可以是文字文件、圖片、程式,等等。在系統執行時,計算機以程序為基本單位進行資源的排程和分配;而在使用者進行的輸入、輸出中,則以檔案為基本單位。大多數應用程式的輸入都是通過檔案來實現的。
在初期編寫程式時,接觸最多的是文字檔案,比如,在註冊和登入功能中,使用者名稱和密碼要儲存在檔案裡,python程式也是寫成文字檔案的形式。
執行一個python檔案的過程:
• Cpython直譯器載入到記憶體
• py檔案從硬碟載入到記憶體
• Cpython直譯器向CPU發出指令,處理py檔案,逐行識別文字的語法
開啟一個文字文件的過程:
• 1 •啟動文字編輯器(程式載入到記憶體),開始編輯,編輯時我們看到即時輸入的內容是存在了記憶體
• 2 •在輸入→顯示的過程中,涉及到中文字元→二進位制→中文字元的過程
• 3 •寫完儲存,編輯器把記憶體中的資料儲存到硬碟
首先來討論一下• 2 •,字元→二進位制→字元的過程,就是編碼(encode)(輸入),解碼(decode)(輸出),的過程。
最開始計算機出現,只在英文環境裡使用,所以編碼解碼只考慮英文字元和二進位制,具體用哪些二進位制數字表示哪個符號,經最早的這批人達成一致,這就是ASCII碼。
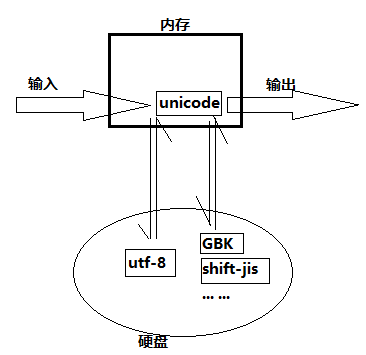
後來計算機普及,每個國家都產生了自己的語言與二進位制的對應標準,比如中國的GBK,因為各個國家不統一,導致了這樣的問題:漢語國家編寫的軟體,在其他語系國家裡不能使用,因為他們的計算機中沒有漢語字元與二進位制的對照關係!為了解決這樣的問題,各國統一,unicode碼誕生了,它將很多國家的字元與二進位制的關係都包含在內,統一使用16位二進位制數字表示各國字元。
結果就是,我們在自己的電腦文字編輯器裡輸入一個日文字元,編碼到記憶體,顯示(輸出)的時候,這16位二進位制數字會解碼成日文,顯示出來,而不會出現亂碼的問題。
可是再後來,使用計算機的過程中,又發現了新問題:在英語系國家的程式設計者發現,原來採用ASCII碼,用8位二進位制表示字元,而現在需要16位,輸入的資料存入硬碟的時間幾乎長了一倍!為了解決這樣的問題,又出現了UTF-8(8-bit Unicode Transformation Format),這是一種針對Unicode的可變長度字元編碼,它會識別unicode編碼的二進位制表示的字元是什麼語言的字元,並分配不同的位元組,比如,如果是英文,就用1個位元組儲存到硬碟,如果是中文,就用3個位元組存到硬碟...這是• 3 •的過程
有了UTF-8之後,只要我們寫一個檔案,儲存成utf-8編碼格式,在任何國家的電腦上也能通用,而且佔的空間更小,存取更快!是不是覺得,utf-8可以完全取代unicode了!理論上的確是這樣,但這裡又存在一個歷史遺留問題了,在這之前,很多國家都用自己國家的編碼標準編寫了軟體,而utf-8裡只有與unicode 一 一對應的關係,並沒有直接和GBK,shift-jis等標準建立聯絡,所以直至現在,我們的計算機記憶體採用的,仍然是unicode.就像python3剛推出,而很多python2的軟體都不能用python3執行,導致很多公司和個人拒絕使用python3,於是龜叔迫不得已推出python2.7一樣,我們需要unicode來作為階段性的過渡。
但是如果以後每個人寫檔案,都採用utf-8格式儲存,等足夠長的時間後,就可以廢棄unicode標準了,也就不會存在因為編碼解碼而導致的程式報錯和亂碼問題!!
這張圖可以幫助你理解編碼、解碼的過程和亂碼、報錯的原因: