
1、秒殺系統架構分析與實戰
1 秒殺業務分析
-
正常電子商務流程
(1)查詢商品;(2)建立訂單;(3)扣減庫存;(4)更新訂單;(5)付款;(6)賣家發貨
-
秒殺業務的特性
(1)低廉價格;(2)大幅推廣;(3)瞬時售空;(4)一般是定時上架;(5)時間短、瞬時併發量高;
2 秒殺技術挑戰
假設某網站秒殺活動只推出一件商品,預計會吸引1萬人參加活動,也就說最大併發請求數是10000,秒殺系統需要面對的技術挑戰有:
-
對現有網站業務造成衝擊
秒殺活動只是網站營銷的一個附加活動,這個活動具有時間短,併發訪問量大的特點,如果和網站原有應用部署在一起,必然會對現有業務造成衝擊,稍有不慎可能導致整個網站癱瘓。
解決方案:將秒殺系統獨立部署,甚至
使用獨立域名,使其與網站完全隔離。 -
高併發下的應用、資料庫負載
使用者在秒殺開始前,通過不停重新整理瀏覽器頁面以保證不會錯過秒殺,這些請求如果按照一般的網站應用架構,訪問應用伺服器、連線資料庫,會對應用伺服器和資料庫伺服器造成負載壓力。
解決方案:重新設計秒殺商品頁面,不使用網站原來的商品詳細頁面,
頁面內容靜態化,使用者請求不需要經過應用服務。 -
突然增加的網路及伺服器頻寬
假設商品頁面大小200K(主要是商品圖片大小),那麼需要的網路和伺服器頻寬是2G(200K×10000),這些網路頻寬是因為秒殺活動新增的,超過網站平時使用的頻寬。
解決方案:因為秒殺新增的網路頻寬,必須和運營商重新購買或者租借。為了減輕網站伺服器的壓力,
需要將秒殺商品頁面快取在CDN,同樣需要和CDN服務商臨時租借新增的出口頻寬。 -
直接下單
秒殺的遊戲規則是到了秒殺才能開始對商品下單購買,在此時間點之前,只能瀏覽商品資訊,不能下單。而下單頁面也是一個普通的URL,如果得到這個URL,不用等到秒殺開始就可以下單了。
解決方案:為了避免使用者直接訪問下單頁面URL,需要將改URL動態化,即使秒殺系統的開發者也無法在秒殺開始前訪問下單頁面的URL。辦法是在
下單頁面URL加入由伺服器端生成的隨機數作為引數,在秒殺開始的時候才能得到。 -
如何控制秒殺商品頁面購買按鈕的點亮
購買按鈕只有在秒殺開始的時候才能點亮,在此之前是灰色的。如果該頁面是動態生成的,當然可以在伺服器端構造響應頁面輸出,控制該按鈕是灰色還 是點亮,但是為了減輕伺服器端負載壓力,更好地利用CDN、反向代理等效能優化手段,該頁面被設計為靜態頁面,快取在CDN、反向代理伺服器上,甚至使用者瀏覽器上。秒殺開始時,使用者重新整理頁面,請求根本不會到達應用伺服器。
解決方案:使用JavaScript指令碼控制,
在秒殺商品靜態頁面中加入一個JavaScript檔案引用,該JavaScript檔案中包含 秒殺開始標誌為否;當秒殺開始的時候生成一個新的JavaScript檔案(檔名保持不變,只是內容不一樣),更新秒殺開始標誌為是,加入下單頁面的URL及隨機數引數(這個隨機數只會產生一個,即所有人看到的URL都是同一個,伺服器端可以用redis這種分散式快取伺服器來儲存隨機數),並被使用者瀏覽器載入,控制秒殺商品頁面的展示。這個JavaScript檔案的載入可以加上隨機版本號(例如xx.js?v=32353823),這樣就不會被瀏覽器、CDN和反向代理伺服器快取。這個JavaScript檔案非常小,即使每次瀏覽器重新整理都訪問JavaScript檔案伺服器也不會對伺服器叢集和網路頻寬造成太大壓力。
-
如何只允許第一個提交的訂單被髮送到訂單子系統
由於最終能夠成功秒殺到商品的使用者只有一個,因此需要在使用者提交訂單時,檢查是否已經有訂單提交。如果已經有訂單提交成功,則需要更新 JavaScript檔案,更新秒殺開始標誌為否,購買按鈕變灰。事實上,由於最終能夠成功提交訂單的使用者只有一個,為了減輕下單頁面伺服器的負載壓力, 可以控制進入下單頁面的入口,只有少數使用者能進入下單頁面,其他使用者直接進入秒殺結束頁面。
解決方案:假設下單伺服器叢集有10臺伺服器,每臺伺服器只接受最多10個下單請求。在還沒有人提交訂單成功之前,如果一臺伺服器已經有十單了,而有的一單都沒處理,可能出現的使用者體驗不佳的場景是使用者第一次點選購買按鈕進入已結束頁面,再重新整理一下頁面,有可能被一單都沒有處理的伺服器處理,進入了填寫訂單的頁面,
可以考慮通過cookie的方式來應對,符合一致性原則。當然可以採用最少連線的負載均衡演算法,出現上述情況的概率大大降低。 -
如何進行下單前置檢查
- 下單伺服器檢查本機已處理的下單請求數目:
如果超過10條,直接返回已結束頁面給使用者;
如果未超過10條,則使用者可進入填寫訂單及確認頁面;
- 檢查全域性已提交訂單數目:
已超過秒殺商品總數,返回已結束頁面給使用者;
未超過秒殺商品總數,提交到子訂單系統;
-
秒殺一般是定時上架
該功能實現方式很多。不過目前比較好的方式是:提前設定好商品的上架時間,使用者可以在前臺看到該商品,但是無法點選“立即購買”的按鈕。但是需要考慮的是,
有人可以繞過前端的限制,直接通過URL的方式發起購買,這就需要在前臺商品頁面,以及bug頁面到後端的資料庫,都要進行時鐘同步。越在後端控制,安全性越高。定時秒殺的話,就要避免賣家在秒殺前對商品做編輯帶來的不可預期的影響。這種特殊的變更需要多方面評估。一般禁止編輯,如需變更,可以走資料訂正多的流程。
-
減庫存的操作
有兩種選擇,一種是
拍下減庫存另外一種是付款減庫存;目前採用的“拍下減庫存”的方式,拍下就是一瞬間的事,對使用者體驗會好些。 -
庫存會帶來“超賣”的問題:售出數量多於庫存數量
由於庫存併發更新的問題,導致在實際庫存已經不足的情況下,庫存依然在減,導致賣家的商品賣得件數超過秒殺的預期。方案:
採用樂觀鎖update auction_auctions set quantity = #inQuantity# where auction_id = #itemId# and quantity = #dbQuantity#還有一種方式,會更好些,叫做嘗試扣減庫存,扣減庫存成功才會進行下單邏輯:
update auction_auctions set quantity = quantity-#count# where auction_id = #itemId# and quantity >= #count# -
秒殺器的應對
秒殺器一般下單個購買及其迅速,根據購買記錄可以甄別出一部分。可以通過校驗碼達到一定的方法,這就要求校驗碼足夠安全,不被破解,採用的方式有:
秒殺專用驗證碼,電視公佈驗證碼,秒殺答題。
3 秒殺架構原則
-
儘量將請求攔截在系統上游
傳統秒殺系統之所以掛,請求都壓倒了後端資料層,資料讀寫鎖衝突嚴重,併發高響應慢,幾乎所有請求都超時,流量雖大,下單成功的有效流量甚小【一趟火車其實只有2000張票,200w個人來買,基本沒有人能買成功,請求有效率為0】。
-
讀多寫少的常用多使用快取
這是一個典型的
讀多寫少的應用場景【一趟火車其實只有2000張票,200w個人來買,最多2000個人下單成功,其他人都是查詢庫存,寫比例只有0.1%,讀比例佔99.9%】,非常適合使用快取。
4 秒殺架構設計
秒殺系統為秒殺而設計,不同於一般的網購行為,參與秒殺活動的使用者更關心的是如何能快速重新整理商品頁面,在秒殺開始的時候搶先進入下單頁面,而不是商品詳情等使用者體驗細節,因此秒殺系統的頁面設計應儘可能簡單。
商品頁面中的購買按鈕只有在秒殺活動開始的時候才變亮,在此之前及秒殺商品賣出後,該按鈕都是灰色的,不可以點選。
下單表單也儘可能簡單,購買數量只能是一個且不可以修改,送貨地址和付款方式都使用使用者預設設定,沒有預設也可以不填,允許等訂單提交後修改;只有第一個提交的訂單傳送給網站的訂單子系統,其餘使用者提交訂單後只能看到秒殺結束頁面。
要做一個這樣的秒殺系統,業務會分為兩個階段,第一個階段是秒殺開始前某個時間到秒殺開始, 這個階段可以稱之為準備階段,使用者在準備階段等待秒殺; 第二個階段就是秒殺開始到所有參與秒殺的使用者獲得秒殺結果, 這個就稱為秒殺階段吧。
4.1 前端層設計
首先要有一個展示秒殺商品的頁面, 在這個頁面上做一個秒殺活動開始的倒計時, 在準備階段內使用者會陸續開啟這個秒殺的頁面, 並且可能不停的重新整理頁面。這裡需要考慮兩個問題:
-
第一個是秒殺頁面的展示
我們知道一個html頁面還是比較大的,
即使做了壓縮,http頭和內容的大小也可能高達數十K,加上其他的css, js,圖片等資源,如果同時有幾千萬人蔘與一個商品的搶購,一般機房頻寬也就只有1G~10G,網路頻寬就極有可能成為瓶頸,所以這個頁面上各類靜態資源首先應分開存放,然後放到cdn節點上分散壓力,由於CDN節點遍佈全國各地,能緩衝掉絕大部分的壓力,而且還比機房頻寬便宜~ -
第二個是倒計時
出於效能原因這個一般由js呼叫客戶端本地時間,就有可能出現客戶端時鐘與伺服器時鐘不一致,另外伺服器之間也是有可能出現時鐘不一致。
客戶端與伺服器時鐘不一致可以採用客戶端定時和伺服器同步時間,這裡考慮一下效能問題,用於同步時間的介面由於不涉及到後端邏輯,只需要將當前web伺服器的時間傳送給客戶端就可以了,因此速度很快,就我以前測試的結果來看,一臺標準的web伺服器2W+QPS不會有問題,如果100W人同時刷,100W QPS也只需要50臺web,一臺硬體LB就可以了~,並且web伺服器群是可以很容易的橫向擴充套件的(LB+DNS輪詢),這個介面可以只返回一小段json格式的資料,而且可以優化一下減少不必要cookie和其他http頭的資訊,所以資料量不會很大,一般來說網路不會成為瓶頸,即使成為瓶頸也可以考慮多機房專線連通,加智慧DNS的解決方案;web伺服器之間時間不同步可以採用統一時間伺服器的方式,比如每隔1分鐘所有參與秒殺活動的web伺服器就與時間伺服器做一次時間同步。 -
瀏覽器層請求攔截
(1)產品層面,使用者點選“查詢”或者“購票”後,按鈕置灰,禁止使用者重複提交請求;
(2)JS層面,限制使用者在x秒之內只能提交一次請求;
4.2 站點層設計
前端層的請求攔截,只能攔住小白使用者(不過這是99%的使用者喲),高階的程式設計師根本不吃這一套,寫個for迴圈,直接呼叫你後端的http請求,怎麼整?
(1)同一個uid,限制訪問頻度,做頁面快取,x秒內到達站點層的請求,均返回同一頁面
(2)同一個item的查詢,例如手機車次,做頁面快取,x秒內到達站點層的請求,均返回同一頁面
如此限流,又有99%的流量會被攔截在站點層。
4.3 服務層設計
站點層的請求攔截,只能攔住普通程式設計師,高階黑客,假設他控制了10w臺肉雞(並且假設買票不需要實名認證),這下uid的限制不行了吧?怎麼整?
(1)大哥,我是服務層,我清楚的知道小米只有1萬部手機,我清楚的知道一列火車只有2000張車票,我透10w個請求去資料庫有什麼意義呢?對於寫請求,做請求佇列,每次只透過有限的寫請求去資料層,如果均成功再放下一批,如果庫存不夠則佇列裡的寫請求全部返回“已售完”;
(2)對於讀請求,還用說麼?cache來抗,不管是memcached還是redis,單機抗個每秒10w應該都是沒什麼問題的;
如此限流,只有非常少的寫請求,和非常少的讀快取mis的請求會透到資料層去,又有99.9%的請求被攔住了。
-
使用者請求分發模組:使用Nginx或Apache將使用者的請求分發到不同的機器上。
-
使用者請求預處理模組:判斷商品是不是還有剩餘來決定是不是要處理該請求。
-
使用者請求處理模組:把通過預處理的請求封裝成事務提交給資料庫,並返回是否成功。
-
資料庫介面模組:該模組是資料庫的唯一介面,負責與資料庫互動,提供RPC介面供查詢是否秒殺結束、剩餘數量等資訊。
-
使用者請求預處理模組
經過HTTP伺服器的分發後,單個伺服器的負載相對低了一些,但總量依然可能很大,如果後臺商品已經被秒殺完畢,那麼直接給後來的請求返回秒殺失敗即可,不必再進一步傳送事務了,示例程式碼可以如下所示:
package seckill; import org.apache.http.HttpRequest; /** * 預處理階段,把不必要的請求直接駁回,必要的請求新增到佇列中進入下一階段. */ public class PreProcessor { // 商品是否還有剩餘 private static boolean reminds = true; private static void forbidden() { // Do something. } public static boolean checkReminds() { if (reminds) { // 遠端檢測是否還有剩餘,該RPC介面應由資料庫伺服器提供,不必完全嚴格檢查. if (!RPC.checkReminds()) { reminds = false; } } return reminds; } /** * 每一個HTTP請求都要經過該預處理. */ public static void preProcess(HttpRequest request) { if (checkReminds()) { // 一個併發的佇列 RequestQueue.queue.add(request); } else { // 如果已經沒有商品了,則直接駁回請求即可. forbidden(); } } }- 併發佇列的選擇
Java的併發包提供了三個常用的併發佇列實現,分別是:ConcurrentLinkedQueue 、 LinkedBlockingQueue 和 ArrayBlockingQueue。
ArrayBlockingQueue是
初始容量固定的阻塞佇列,我們可以用來作為資料庫模組成功競拍的佇列,比如有10個商品,那麼我們就設定一個10大小的陣列佇列。ConcurrentLinkedQueue使用的是
CAS原語無鎖佇列實現,是一個非同步佇列,入隊的速度很快,出隊進行了加鎖,效能稍慢。LinkedBlockingQueue也是
阻塞的佇列,入隊和出隊都用了加鎖,當隊空的時候執行緒會暫時阻塞。由於我們的系統
入隊需求要遠大於出隊需求,一般不會出現隊空的情況,所以我們可以選擇ConcurrentLinkedQueue來作為我們的請求佇列實現:package seckill; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.ConcurrentLinkedQueue; import org.apache.http.HttpRequest; public class RequestQueue { public static ConcurrentLinkedQueue<HttpRequest> queue = new ConcurrentLinkedQueue<HttpRequest>(); } -
使用者請求模組
package seckill; import org.apache.http.HttpRequest; public class Processor { /** * 傳送秒殺事務到資料庫佇列. */ public static void kill(BidInfo info) { DB.bids.add(info); } public static void process() { BidInfo info = new BidInfo(RequestQueue.queue.poll()); if (info != null) { kill(info); } } } class BidInfo { BidInfo(HttpRequest request) { // Do something. } } -
資料庫模組
資料庫主要是使用一個ArrayBlockingQueue來暫存有可能成功的使用者請求。
package seckill; import java.util.concurrent.ArrayBlockingQueue; /** * DB應該是資料庫的唯一介面. */ public class DB { public static int count = 10; public static ArrayBlockingQueue<BidInfo> bids = new ArrayBlockingQueue<BidInfo>(10); public static boolean checkReminds() { // TODO return true; } // 單執行緒操作 public static void bid() { BidInfo info = bids.poll(); while (count-- > 0) { // insert into table Bids values(item_id, user_id, bid_date, other) // select count(id) from Bids where item_id = ? // 如果資料庫商品數量大約總數,則標誌秒殺已完成,設定標誌位reminds = false. info = bids.poll(); } } }
4.4 資料庫設計
4.4.1 基本概念
概念一“單庫”
概念二“分片”
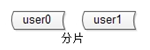
分片解決的是“資料量太大”的問題,也就是通常說的“水平切分”。一旦引入分片,勢必有“資料路由”的概念,哪個資料訪問哪個庫。路由規則通常有3種方法:
-
範圍:range
優點:簡單,容易擴充套件
缺點:各庫壓力不均(新號段更活躍)
-
雜湊:hash 【大部分網際網路公司採用的方案二:雜湊分庫,雜湊路由】
優點:簡單,資料均衡,負載均勻
缺點:遷移麻煩(2庫擴3庫資料要遷移)
-
路由服務:router-config-server
優點:靈活性強,業務與路由演算法解耦
缺點:每次訪問資料庫前多一次查詢
概念三“分組”
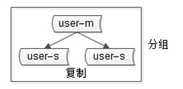
分組解決“可用性”問題,分組通常通過主從複製的方式實現。
網際網路公司資料庫實際軟體架構是:又分片,又分組(如下圖)
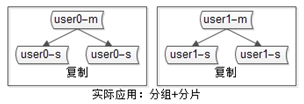
4.4.2 設計思路
資料庫軟體架構師平時設計些什麼東西呢?至少要考慮以下四點:
-
如何保證資料可用性;
-
如何提高資料庫讀效能(大部分應用讀多寫少,讀會先成為瓶頸);
-
如何保證一致性;
-
如何提高擴充套件性;
-
1. 如何保證資料的可用性?
解決可用性問題的思路是=>冗餘如何保證站點的可用性?複製站點,冗餘站點
如何保證服務的可用性?複製服務,冗餘服務
如何保證資料的可用性?複製資料,冗餘資料
資料的冗餘,會帶來一個副作用=>引發一致性問題(先不說一致性問題,先說可用性)。 -
2. 如何保證資料庫“讀”高可用?
冗餘讀庫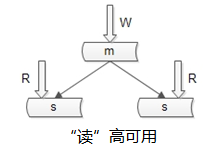
冗餘讀庫帶來的副作用?讀寫有延時,可能不一致上面這個圖是很多網際網路公司mysql的架構,寫仍然是單點,不能保證寫高可用。
-
3. 如何保證資料庫“寫”高可用?
冗餘寫庫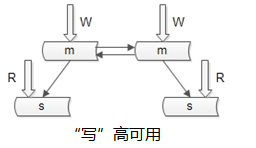
採用雙主互備的方式,可以冗餘寫庫帶來的副作用?雙寫同步,資料可能衝突(例如“自增id”同步衝突),如何解決同步衝突,有兩種常見解決方案:-
兩個寫庫使用不同的初始值,相同的步長來增加id:1寫庫的id為0,2,4,6...;2寫庫的id為1,3,5,7...;
-
不使用資料的id,業務層自己生成唯一的id,保證資料不衝突;
-
實際中沒有使用上述兩種架構來做讀寫的“高可用”,採用的是“雙主當主從用”的方式:
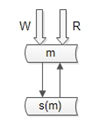
仍是雙主,但只有一個主提供服務(讀+寫),另一個主是“shadow-master”,只用來保證高可用,平時不提供服務。 master掛了,shadow-master頂上(vip漂移,對業務層透明,不需要人工介入)。這種方式的好處:
-
讀寫沒有延時;
-
讀寫高可用;
不足:
-
不能通過加從庫的方式擴充套件讀效能;
-
資源利用率為50%,一臺冗餘主沒有提供服務;
那如何提高讀效能呢?進入第二個話題,如何提供讀效能。
-
4. 如何擴充套件讀效能
提高讀效能的方式大致有三種,
第一種是建立索引。這種方式不展開,要提到的一點是,不同的庫可以建立不同的索引。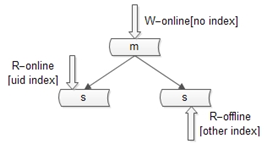
寫庫不建立索引;線上讀庫建立線上訪問索引,例如uid;線下讀庫建立線下訪問索引,例如time;第二種擴充讀效能的方式是,增加從庫,這種方法大家用的比較多,但是,存在兩個缺點:-
從庫越多,同步越慢;
-
同步越慢,資料不一致視窗越大(不一致後面說,還是先說讀效能的提高);
實際中沒有采用這種方法提高資料庫讀效能(沒有從庫),
採用的是增加快取。常見的快取架構如下: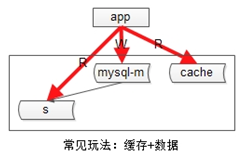
上游是業務應用,下游是主庫,從庫(讀寫分離),快取。實際的玩法:
服務+資料庫+快取一套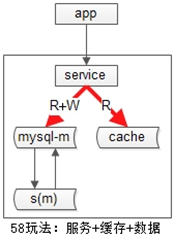
業務層不直接面向db和cache,
服務層遮蔽了底層db、cache的複雜性。為什麼要引入服務層,今天不展開,採用了“服務+資料庫+快取一套”的方式提供資料訪問,用cache提高讀效能。不管採用主從的方式擴充套件讀效能,還是快取的方式擴充套件讀效能,資料都要複製多份(主+從,db+cache),
一定會引發一致性問題。 -
-
5. 如何保證一致性?
主從資料庫的一致性,通常有兩種解決方案:
1. 中介軟體
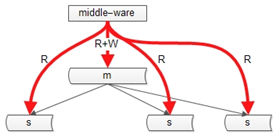
如果某一個key有寫操作,在不一致時間視窗內,中介軟體會將這個key的讀操作也路由到主庫上。這個方案的缺點是,
資料庫中介軟體的門檻較高(百度,騰訊,阿里,360等一些公司有)。2. 強制讀主
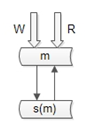
上面實際用的“雙主當主從用”的架構,不存在主從不一致的問題。第二類不一致,
是db與快取間的不一致: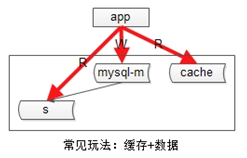
常見的快取架構如上,此時寫操作的順序是:
(1)淘汰cache;
(2)寫資料庫;
讀操作的順序是:
(1)讀cache,如果cache hit則返回;
(2)如果cache miss,則讀從庫;
(3)讀從庫後,將資料放回cache;
在一些異常時序情況下,有可能從【從庫讀到舊資料(同步還沒有完成),舊資料入cache後】,資料會長期不一致。
解決辦法是“快取雙淘汰”,寫操作時序升級為:(1)淘汰cache;
(2)寫資料庫;
(3)在經驗“主從同步延時視窗時間”後,再次發起一個非同步淘汰cache的請求;
這樣,即使有髒資料如cache,一個小的時間視窗之後,髒資料還是會被淘汰。帶來的代價是,多引入一次讀miss(成本可以忽略)。
除此之外,最佳實踐之一是:
建議為所有cache中的item設定一個超時時間。 -
6. 如何提高資料庫的擴充套件性?
原來用hash的方式路由,分為2個庫,資料量還是太大,要分為3個庫,勢必需要進行資料遷移,有一個很帥氣的“資料庫秒級擴容”方案。
如何秒級擴容?
首先,
我們不做2庫變3庫的擴容,我們做2庫變4庫(庫加倍)的擴容(未來4->8->16)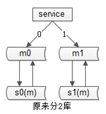
服務+資料庫是一套(省去了快取),
資料庫採用“雙主”的模式。擴容步驟:
第一步,將一個主庫提升;第二步,修改配置,2庫變4庫(原來MOD2,現在配置修改後MOD4),擴容完成;原MOD2為偶的部分,現在會MOD4餘0或者2;原MOD2為奇的部分,現在會MOD4餘1或者3;資料不需要遷移,同時,雙主互相同步,一遍是餘0,一邊餘2,兩邊資料同步也不會衝突,秒級完成擴容!最後,要做一些收尾工作:
-
將舊的雙主同步解除;
-
增加新的雙主(雙主是保證可用性的,shadow-master平時不提供服務);
-
刪除多餘的資料(餘0的主,可以將餘2的資料刪除掉);
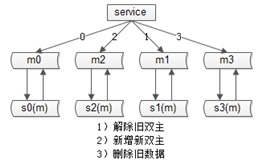
這樣,秒級別內,我們就完成了2庫變4庫的擴充套件。
-
5 大併發帶來的挑戰
5.1 請求介面的合理設計
一個秒殺或者搶購頁面,通常分為2個部分,一個是靜態的HTML等內容,另一個就是參與秒殺的Web後臺請求介面。
通常靜態HTML等內容,是通過CDN的部署,一般壓力不大,核心瓶頸實際上在後臺請求介面上。這個後端介面,必須能夠支援高併發請求,同時,非常重要的一點,必須儘可能“快”,在最短的時間裡返回使用者的請求結果。為了實現儘可能快這一點,介面的後端儲存使用記憶體級別的操作會更好一點。仍然直接面向MySQL之類的儲存是不合適的,如果有這種複雜業務的需求,都建議採用非同步寫入。
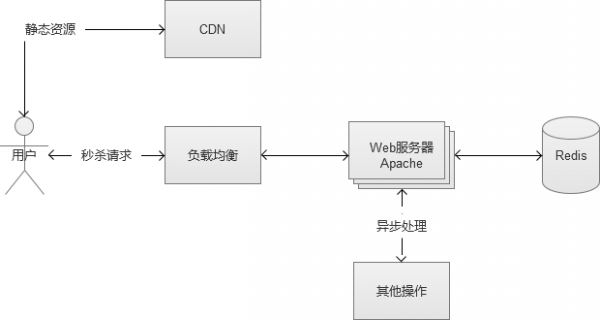
當然,也有一些秒殺和搶購採用“滯後反饋”,就是說秒殺當下不知道結果,一段時間後才可以從頁面中看到使用者是否秒殺成功。但是,這種屬於“偷懶”行為,同時給使用者的體驗也不好,容易被使用者認為是“暗箱操作”。
5.2 高併發的挑戰:一定要“快”
我們通常衡量一個Web系統的吞吐率的指標是QPS(Query Per Second,每秒處理請求數),解決每秒數萬次的高併發場景,這個指標非常關鍵。舉個例子,我們假設處理一個業務請求平均響應時間為100ms,同時,系統內有20臺Apache的Web伺服器,配置MaxClients為500個(表示Apache的最大連線數目)。
那麼,我們的Web系統的理論峰值QPS為(理想化的計算方式):
20*500/0.1 = 100000 (10萬QPS)
咦?我們的系統似乎很強大,1秒鐘可以處理完10萬的請求,5w/s的秒殺似乎是“紙老虎”哈。實際情況,當然沒有這麼理想。在高併發的實際場景下,機器都處於高負載的狀態,在這個時候平均響應時間會被大大增加。
就Web伺服器而言,Apache打開了越多的連線程序,CPU需要處理的上下文切換也越多,額外增加了CPU的消耗,然後就直接導致平均響應時間增加。因此上述的MaxClient數目,要根據CPU、記憶體等硬體因素綜合考慮,絕對不是越多越好。可以通過Apache自帶的abench來測試一下,取一個合適的值。然後,我們選擇記憶體操作級別的儲存的Redis,在高併發的狀態下,儲存的響應時間至關重要。網路頻寬雖然也是一個因素,不過,這種請求資料包一般比較小,一般很少成為請求的瓶頸。負載均衡成為系統瓶頸的情況比較少,在這裡不做討論哈。
那麼問題來了,假設我們的系統,在5w/s的高併發狀態下,平均響應時間從100ms變為250ms(實際情況,甚至更多):
20*500/0.25 = 40000 (4萬QPS)
於是,我們的系統剩下了4w的QPS,面對5w每秒的請求,中間相差了1w。
然後,這才是真正的惡夢開始。舉個例子,高速路口,1秒鐘來5部車,每秒通過5部車,高速路口運作正常。突然,這個路口1秒鐘只能通過4部車,車流量仍然依舊,結果必定出現大塞車。(5條車道忽然變成4條車道的感覺)。
同理,某一個秒內,20*500個可用連線程序都在滿負荷工作中,卻仍然有1萬個新來請求,沒有連線程序可用,系統陷入到異常狀態也是預期之內。
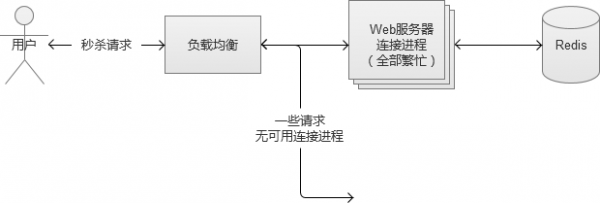
其實在正常的非高併發的業務場景中,也有類似的情況出現,某個業務請求接口出現問題,響應時間極慢,將整個Web請求響應時間拉得很長,逐漸將Web伺服器的可用連線數佔滿,其他正常的業務請求,無連線程序可用。
更可怕的問題是,是使用者的行為特點,系統越是不可用,使用者的點選越頻繁,惡性迴圈最終導致“雪崩”(其中一臺Web機器掛了,導致流量分散到其他正常工作的機器上,再導致正常的機器也掛,然後惡性迴圈),將整個Web系統拖垮。
5.3 重啟與過載保護
如果系統發生“雪崩”,貿然重啟服務,是無法解決問題的。最常見的現象是,啟動起來後,立刻掛掉。這個時候,最好在入口層將流量拒絕,然後再將重啟。如果是redis/memcache這種服務也掛了,重啟的時候需要注意“預熱”,並且很可能需要比較長的時間。
秒殺和搶購的場景,流量往往是超乎我們系統的準備和想象的。這個時候,過載保護是必要的。如果檢測到系統滿負載狀態,拒絕請求也是一種保護措施。在前端設定過濾是最簡單的方式,但是,這種做法是被使用者“千夫所指”的行為。更合適一點的是,將過載保護設定在CGI入口層,快速將客戶的直接請求返回。
6 作弊的手段:進攻與防守
秒殺和搶購收到了“海量”的請求,實際上裡面的水分是很大的。不少使用者,為了“搶“到商品,會使用“刷票工具”等型別的輔助工具,幫助他們傳送儘可能多的請求到伺服器。還有一部分高階使用者,製作強大的自動請求指令碼。這種做法的理由也很簡單,就是在參與秒殺和搶購的請求中,自己的請求數目佔比越多,成功的概率越高。
這些都是屬於“作弊的手段”,不過,有“進攻”就有“防守”,這是一場沒有硝煙的戰鬥哈。
6.1 同一個賬號,一次性發出多個請求
部分使用者通過瀏覽器的外掛或者其他工具,在秒殺開始的時間裡,以自己的賬號,一次傳送上百甚至更多的請求。實際上,這樣的使用者破壞了秒殺和搶購的公平性。
這種請求在某些沒有做資料安全處理的系統裡,也可能造成另外一種破壞,導致某些判斷條件被繞過。例如一個簡單的領取邏輯,先判斷使用者是否有參與記錄,如果沒有則領取成功,最後寫入到參與記錄中。這是個非常簡單的邏輯,但是,在高併發的場景下,存在深深的漏洞。多個併發請求通過負載均衡伺服器,分配到內網的多臺Web伺服器,它們首先向儲存傳送查詢請求,然後,在某個請求成功寫入參與記錄的時間差內,其他的請求獲查詢到的結果都是“沒有參與記錄”。這裡,就存在邏輯判斷被繞過的風險。
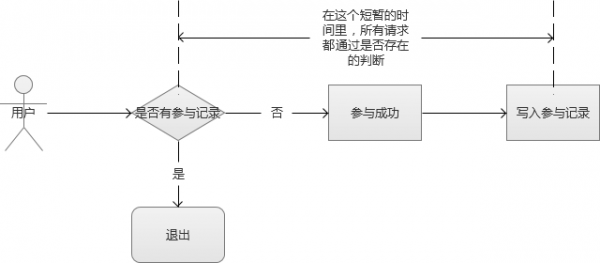
應對方案:
在程式入口處,一個賬號只允許接受1個請求,其他請求過濾。不僅解決了同一個賬號,傳送N個請求的問題,還保證了後續的邏輯流程的安全。實現方案,可以通過Redis這種記憶體快取服務,寫入一個標誌位(只允許1個請求寫成功,結合watch的樂觀鎖的特性),成功寫入的則可以繼續參加。
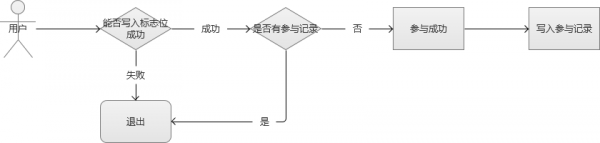
或者,自己實現一個服務,將同一個賬號的請求放入一個佇列中,處理完一個,再處理下一個。
6.2 多個賬號,一次性發送多個請求
很多公司的賬號註冊功能,在發展早期幾乎是沒有限制的,很容易就可以註冊很多個賬號。因此,也導致了出現了一些特殊的工作室,通過編寫自動註冊指令碼,積累了一大批“殭屍賬號”,數量龐大,幾萬甚至幾十萬的賬號不等,專門做各種刷的行為(這就是微博中的“殭屍粉“的來源)。舉個例子,例如微博中有轉發抽獎的活動,如果我們使用幾萬個“殭屍號”去混進去轉發,這樣就可以大大提升我們中獎的概率。
這種賬號,使用在秒殺和搶購裡,也是同一個道理。例如,iPhone官網的搶購,火車票黃牛黨。
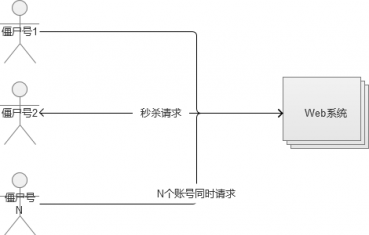
應對方案:
這種場景,可以通過檢測指定機器IP請求頻率就可以解決,如果發現某個IP請求頻率很高,可以給它彈出一個驗證碼或者直接禁止它的請求:
-
彈出驗證碼,最核心的追求,就是分辨出真實使用者。因此,大家可能經常發現,網站彈出的驗證碼,有些是“鬼神亂舞”的樣子,有時讓我們根本無法看清。他們這樣做的原因,其實也是為了讓驗證碼的圖片不被輕易識別,因為強大的“自動指令碼”可以通過圖片識別裡面的字元,然後讓指令碼自動填寫驗證碼。實際上,有一些非常創新的驗證碼,效果會比較好,例如給你一個簡單問題讓你回答,或者讓你完成某些簡單操作(例如百度貼吧的驗證碼)。 -
直接禁止IP,實際上是有些粗暴的,因為有些真實使用者的網路場景恰好是同一出口IP的,可能會有“誤傷“。但是這一個做法簡單高效,根據實際場景使用可以獲得很好的效果。
6.3 多個賬號,不同IP傳送不同請求
所謂道高一尺,魔高一丈。有進攻,就會有防守,永不休止。這些“工作室”,發現你對單機IP請求頻率有控制之後,他們也針對這種場景,想出了他們的“新進攻方案”,就是不斷改變IP。
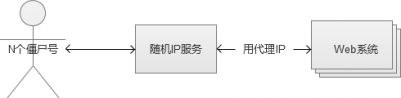
有同學會好奇,這些隨機IP服務怎麼來的。有一些是某些機構自己佔據一批獨立IP,然後做成一個隨機代理IP的服務,有償提供給這些“工作室”使用。還有一些更為黑暗一點的,就是通過木馬黑掉普通使用者的電腦,這個木馬也不破壞使用者電腦的正常運作,只做一件事情,就是轉發IP包,普通使用者的電腦被變成了IP代理出口。通過這種做法,黑客就拿到了大量的獨立IP,然後搭建為隨機IP服務,就是為了掙錢。
應對方案:
說實話,這種場景下的請求,和真實使用者的行為,已經基本相同了,想做分辨很困難。再做進一步的限制很容易“誤傷“真實使用者,這個時候,通常只能通過設定業務門檻高來限制這種請求了,或者通過賬號行為的”資料探勘“來提前清理掉它們。
殭屍賬號也還是有一些共同特徵的,例如賬號很可能屬於同一個號碼段甚至是連號的,活躍度不高,等級低,資料不全等等。根據這些特點,適當設定參與門檻,例如限制參與秒殺的賬號等級。通過這些業務手段,也是可以過濾掉一些殭屍號。
7 高併發下的資料安全
我們知道在多執行緒寫入同一個檔案的時候,會存現“執行緒安全”的問題(多個執行緒同時運行同一段程式碼,如果每次執行結果和單執行緒執行的結果是一樣的,結果和預期相同,就是執行緒安全的)。如果是MySQL資料庫,可以使用它自帶的鎖機制很好的解決問題,但是,在大規模併發的場景中,是不推薦使用MySQL的。秒殺和搶購的場景中,還有另外一個問題,就是“超發”,如果在這方面控制不慎,會產生髮送過多的情況。我們也曾經聽說過,某些電商搞搶購活動,買家成功拍下後,商家卻不承認訂單有效,拒絕發貨。這裡的問題,也許並不一定是商家奸詐,而是系統技術層面存在超發風險導致的。
7.1 超發的原因
假設某個搶購場景中,我們一共只有100個商品,在最後一刻,我們已經消耗了99個商品,僅剩最後一個。這個時候,系統發來多個併發請求,這批請求讀取到的商品餘量都是99個,然後都通過了這一個餘量判斷,最終導致超發。
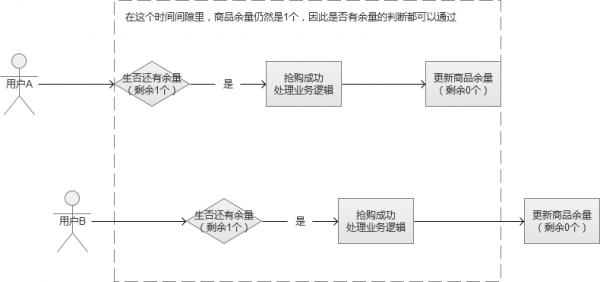
在上面的這個圖中,就導致了併發使用者B也“搶購成功”,多讓一個人獲得了商品。這種場景,在高併發的情況下非常容易出現。
7.2 悲觀鎖思路
解決執行緒安全的思路很多,可以從“悲觀鎖”的方向開始討論。
悲觀鎖,也就是在修改資料的時候,採用鎖定狀態,排斥外部請求的修改。遇到加鎖的狀態,就必須等待。
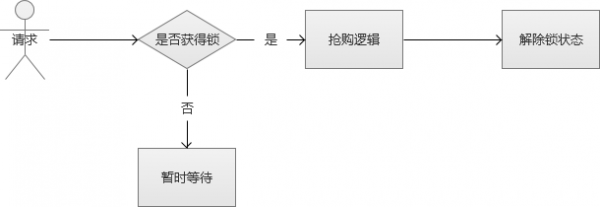
雖然上述的方案的確解決了執行緒安全的問題,但是,別忘記,我們的場景是“高併發”。也就是說,會很多這樣的修改請求,每個請求都需要等待“鎖”,某些執行緒可能永遠都沒有機會搶到這個“鎖”,這種請求就會死在那裡。同時,這種請求會很多,瞬間增大系統的平均響應時間,結果是可用連線數被耗盡,系統陷入異常。
7.3 FIFO佇列思路
那好,那麼我們稍微修改一下上面的場景,我們直接將請求放入佇列中的,採用FIFO(First Input First Output,先進先出),這樣的話,我們就不會導致某些請求永遠獲取不到鎖。看到這裡,是不是有點強行將多執行緒變成單執行緒的感覺哈。
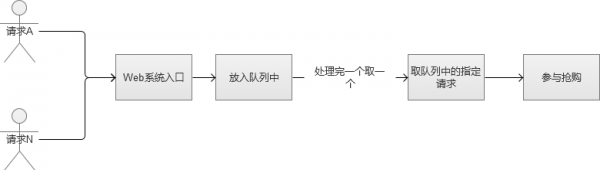
然後,我們現在解決了鎖的問題,全部請求採用“先進先出”的佇列方式來處理。那麼新的問題來了,高併發的場景下,因為請求很多,很可能一瞬間將佇列記憶體“撐爆”,然後系統又陷入到了異常狀態。或者設計一個極大的記憶體佇列,也是一種方案,但是,系統處理完一個佇列內請求的速度根本無法和瘋狂湧入佇列中的數目相比。也就是說,佇列內的請求會越積累越多,最終Web系統平均響應時候還是會大幅下降,系統還是陷入異常。
7.4 樂觀鎖思路
這個時候,我們就可以討論一下“樂觀鎖”的思路了。樂觀鎖,是相對於“悲觀鎖”採用更為寬鬆的加鎖機制,大都是採用帶版本號(Version)更新。實現就是,這個資料所有請求都有資格去修改,但會獲得一個該資料的版本號,只有版本號符合的才能更新成功,其他的返回搶購失敗。這樣的話,我們就不需要考慮佇列的問題,不過,它會增大CPU的計算開銷。但是,綜合來說,這是一個比較好的解決方案。
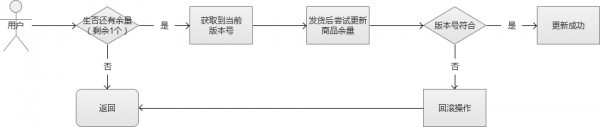
有很多軟體和服務都“樂觀鎖”功能的支援,例如Redis中的watch就是其中之一。通過這個實現,我們保證了資料的安全。
8 總結
網際網路正在高速發展,使用網際網路服務的使用者越多,高併發的場景也變得越來越多。電商秒殺和搶購,是兩個比較典型的網際網路高併發場景。雖然我們解決問題的具體技術方案可能千差萬別,但是遇到的挑戰卻是相似的,因此解決問題的思路也異曲同工。
轉自:https://my.oschina.net/xianggao/blog/524943