
hbase中的一些重要的知識點
hbase中的一些重要的知識點
##1.應用場景
1.需要對海量非結構化的資料進行儲存
2.需要隨機近實時的讀寫管理資料
##2.rowKey的設計
- 長度原則: rowkey是一個二進位制流,建議rowkey的長度不要超過16個位元組
原因如下:
(1)資料的持久化檔案HFile中是按照KeyValue儲存的,如果Rowkey過長比如100個位元組,1000萬列資料光Rowkey就要佔用100*1000萬=10億個位元組,將近1G資料,這會極大影響HFile的儲存效率;
(2)MemStore將快取部分資料到記憶體,如果Rowkey欄位過長記憶體的有效利用率會降低,系統將無法快取更多的資料,這會降低檢索效率。因此Rowkey的位元組長度越短越好。
(3)目前作業系統是都是64位系統,記憶體8位元組對齊。控制在16個位元組,8位元組的整數倍利用作業系統的最佳特性。
-
雜湊原則: 如果rowkey是按時間戳的方式遞增,不要將時間放在二進位制碼前,建議將rowkey的高位作為雜湊欄位,由程式迴圈生成,低位放時間欄位,這樣將提高資料均衡分佈在每個regionserver實現負載均衡的機率.如果沒有雜湊欄位,首欄位直接是時間資訊,將產生所有新資料都在一個regionserver上堆積的熱點現象,這樣在做資料檢索的時候負載將會集中在個別regionserver上,降低查詢效率
-
rowKey唯一原則: 必須在設計上保持其唯一性.
##3.二級索引
二級索引的本質就是建立各列值與行鍵之間的對映關係.
由於 HBase 本身沒有二級索引( Secondary Index)機制,基於索引檢索資料只能單純地依靠 RowKey,為了能支援多條件查詢,開發者需要將所有可能作為查詢條件的欄位一一拼接到 RowKey 中,這是 HBase 開發中極為常見的做法
##4.協處理器
協處理器有兩種:observer和endpoint
Observer允許叢集在正常的客戶端操作過程中可以有不同的行為表現
Endpoint允許擴充套件叢集的能力,對客戶端應用開放新的運算命令
Observer協處理器
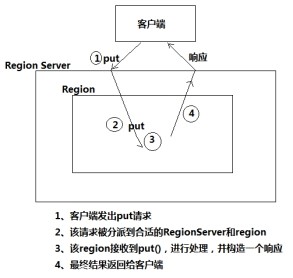
² 正常put請求的流程:
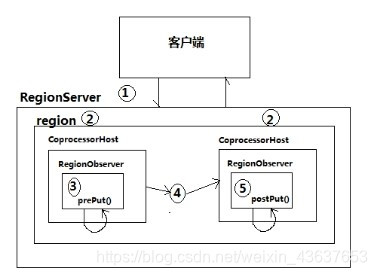
² 加入Observer協處理後的put流程:
1 客戶端發出put請求
2 該請求被分派給合適的RegionServer和region
3 coprocessorHost攔截該請求,然後在該表上登記的每個RegionObserver上呼叫prePut()
4 如果沒有被prePut()攔截,該請求繼續送到region,然後進行處理
5 region產生的結果再次被CoprocessorHost攔截,呼叫postPut()
6 假如沒有postPut()攔截該響應,最終結果被返回給客戶端
Observer的型別
1、RegionObs——這種Observer鉤在資料訪問和操作階段,所有標準的資料操作命令都可以被pre-hooks和post-hooks攔截
2、WALObserver——WAL所支援的Observer;可用的鉤子是pre-WAL和post-WAL
3、 MasterObserver——鉤住DDL事件,如表建立或模式修改
5.hbase和hive、hdfs的關係
Hive與Hbase的資料一般都儲存在HDFS上。Hadoop HDFS為他們提供了高可靠性的底層儲存支援。
Hive:
Hive不支援更改資料的操作,Hive基於資料倉庫,提供靜態資料的動態查詢。其使用類SQL語言,底層經過編譯轉為MapReduce程式,在Hadoop上執行,資料儲存在HDFS上。
HDFS:
HDFS是GFS的一種實現,他的完整名字是分散式檔案系統,類似於FAT32,NTFS,是一種檔案格式,是底層的。
Hbase:
Hbase是Hadoop database,即Hadoop資料庫。它是一個適合於非結構化資料儲存的資料庫,HBase基於列的而不是基於行的模式。
6.hbase的架構及各元件的功能
client**:**
1.hbase的客戶端,包含訪問hbase的介面(linux shell 、java api)
2.client維護一些cache來加快訪問hbase的速度,比如region的位置資訊
zookeeper**:**
1.監控hmaster的狀態,保證有且僅有一個active的hmaster,達到高可用。
2.儲存所有region的定址入口,–root表在那臺伺服器上。
3.實時監控hregionserver的狀態,將regionserver的上下線資訊實時通知給hmaster
4.儲存hbase的所有表的資訊(hbase的元資料)
hmaster**:(hbase的老大)**
1.為regionserver分配region(新建表等)
2.負責regionserver的負載均衡
3.負責region的重新分配(hregionserver異常、hregion裂變)
4.hdfs上的垃圾檔案回收
5.處理schema的更新請求
hregionserver**:(hbase的小弟)**
1.hregionserver維護master分配給他的region(管理本機器上region)
2.處理client對這些region的IO請求,並和hdfs進行互動
3.region server負責切分在執行過程中變大的region
hlog:
對hbase的操作進行記錄,使用WAL寫資料,優先寫入log,然後再寫memstore(提速的工具),以防資料丟失時可以進行回滾.
hregion:
hbase中分散式儲存和負載均衡的最小單元,是表或者表的一部分
store:
相當於一個列簇.
memstore:128M
記憶體緩衝區,用於將資料批量重新整理到HDFS上.
hstorefile(hfile):
hbase中的資料是以hfile的形式儲存在hdfs上
7.hbase的優化
客戶端的優化
1.關閉自動重新整理
.setAutoFlush
2.儘量批量寫入資料(put或者delete時儘量批量寫入)
3.謹慎關閉寫Log
.setDurability(Durability.SKI);
4.儘量將資料放入到快取:
.setInMemory(true);
5.儘量不要有太多的列簇,最多兩個,hbase在重新整理列簇的同時會將相鄰的兩個列簇也重新整理到磁碟
6.rowkey的長度儘量的短,最大64KB,儘量將該關閉的資源關閉
Admin,Table,ResultScanner等 (連線到伺服器的物件)
8.寬表高表的選擇
hbase中的寬表是指很多列較少行,即列多行少的表,一行中的資料量較大,行數少;高表是指很多行較少列,即行多列少,一行中的資料量較少,行數大。
寬表和高表的優劣總結如下:
1.查詢效能:高表更好,因為查詢條件都在row key中, 是全域性分散式索引的一部分。高表一行中的資料較少。所以查詢快取BlockCache能快取更多的行,以行數為單位的吞吐量會更高。
2.分片能力:高表分片粒度更細,各個分片的大小更均衡。因為高表一行的資料較少,寬表一行的資料較多。HBase按行來分片。
3.元資料開銷:高表元資料開銷更大。高錶行多,row key多,可能造成region數量也多,- root -、 .meta表資料量更大。過大的元資料開銷,可能引起HBase叢集的不穩定、master更大的負擔(這方面後續再好好總結)。
4.事務能力:寬表事務性更好。HBase對一行的寫入(Put)是有事務原子性的,一行的所有列要麼全部寫入成功,要麼全部沒有寫入。但是多行的更新之間沒有事務性保證。
5.資料壓縮比:如果我們對一行內的資料進行壓縮,寬表能獲得更高的壓縮比。因為寬表中,一行的資料量較大,往往存在更多相似的二進位制位元組,有利於提高壓縮比。通過壓縮,緩解了寬表一行資料量太大,並導致分片大小不均勻的問題。查詢時,我們根據row key找到壓縮後的資料,進行解壓縮。而且解壓縮可以通過協處理器(coproesssor)在HBase伺服器上做,而不是在業務應用的伺服器上做,以充分應用HBase叢集的CPU能力