
Global Average Pooling 對全連線層的可替代性
reference:https://blog.csdn.net/williamyi96/article/details/77530995
Golbal Average Pooling 第一次出現在論文Network in Network中,後來又很多工作延續使用了GAP,實驗證明:Global Average Pooling確實可以提高CNN效果。
Traditional Pooling Methods
要想真正的理解Global Average Pooling,首先要了解深度網路中常見的pooling方式,以及全連線層。
眾所周知CNN網路中常見結構是:卷積、池化和啟用。卷積層是CNN網路的核心,啟用函式
Fully Connected layer
很長一段時間以來,全連線網路一直是CNN分類網路的標配結構。一般在全連線後會有啟用函式來做分類,假設這個啟用函式是一個多分類softmax,那麼全連線網路的作用就是將最後一層卷積得到的feature map stretch成向量,對這個向量做乘法,最終降低其維度,然後輸入到softmax層中得到對應的每個類別的得分。
全連線層如此的重要,以至於全連線層過多的引數重要到會造成過擬合,所以也會有一些方法專門用來解決過擬合,比如dropout。
但是,我們同時也注意到,全連線層有一個非常致命的弱點就是引數量過大,特別是與最後一個卷積層相連的全連線層。一方面增加了Training以及testing的計算量,降低了速度;另外一方面引數量過大容易過擬合。雖然使用了類似dropout等手段去處理,但是畢竟dropout是hyper-parameter, 不夠優美也不好實踐。
那麼我們有沒有辦法將其替代呢?當然有,就是GAP(Global Average Pooling)。
Global Average Pooling
們要明確以下,全連線層將卷積層展開成向量之後不還是要針對每個feature map進行分類嗎,GAP的思路就是將上述兩個過程合二為一,一起做了。如圖所示:
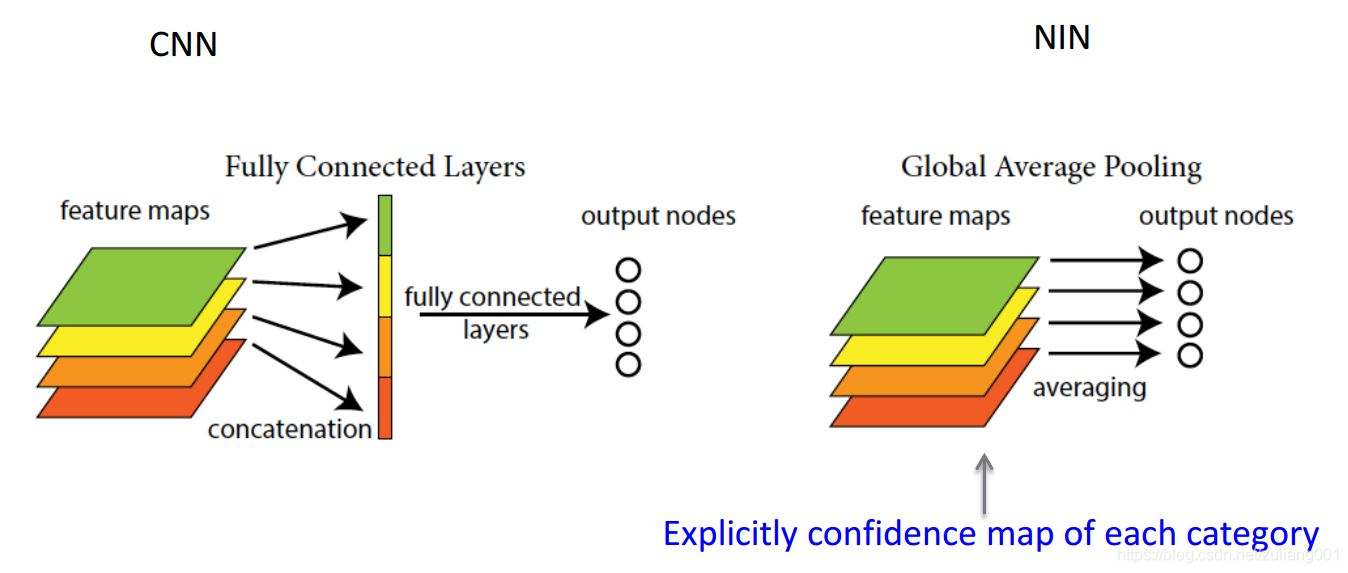
每個講到全域性池化的都會說GAP就是把avg pooling的視窗大小設定成feature map的大小,這雖然是正確的,但這並不是GAP內涵的全部。GAP的意義是對整個網路從結構上做正則化防止過擬合。既要引數少避免全連線帶來的過擬合風險,又要能達到全連線一樣的轉換功能,怎麼做呢?直接從feature map的通道上下手,如果我們最終有1000類,那麼最後一層卷積輸出的feature map就只有1000個channel,然後對這個feature map應用全域性池化,輸出長度為1000的向量,這就相當於剔除了全連線層黑箱子操作的特徵,直接賦予了每個channel實際的類別意義。
實踐證明其效果還是比較可觀的,同時GAP可以實現任意影象大小的輸入。但是值得我們注意的是,使用GAP可能會造成收斂速度減慢。
舉個例子
假如,最後的一層的資料是10個6*6的特徵圖,global average pooling是將每一張特徵圖計算所有畫素點的均值,輸出一個數據值,
這樣10 個特徵圖就會輸出10個數據點,將這些資料點組成一個1*10的向量的話,就成為一個特徵向量,就可以送入到softmax的分類中計算了