
大資料環境操作筆記
不久將要參加個什麼大資料比賽。 於是將相關的內容練習了幾遍。 其中各自的關鍵及相關的理解均寫成了筆記,分別是zookeeper分散式叢集環境的搭建,hadoop叢集環境的搭建,分散式非關係型資料庫hbase環境搭建,基於hive的資料倉庫的構建 以及於此同時回顧的計算機網路的相關知識。 短期來看,似乎有點浪費時間,做了一些無用功。 無論參加比賽獲獎與否。 但是長期來看,還是很有益處的,不說大資料這種對普通開發人員不著調的話題,單單是計算機網路的相關理論知識,足夠抵過很多的所謂實踐了。 不管怎樣,既然做了,那就儘量做好吧,希望能夠做到問心無愧就好。 因此還是決定將知識總體拉通在複習一遍,並且將資料倉庫中的資料分析部分給補上(筆記已經整理在電腦中,為防止誤刪資料,還是滕到部落格上比較好! 上次清理桌面莫名其妙將自己數個月起早貪黑整理的筆記,以及整理的英語筆記都給弄丟了。 還好其中重要的都給寫到了部落格裡,丟失了部分勞動成果,馬勒戈壁的)。
先看看各個元件的啟動方式,以及啟動成功後,各自啟動了哪些程序:(這實際上是最容易理解的,比很多的理論知識要來的直接的多):



當在叢集環境下,這些程序都啟動正常的話,那麼基本可以判定這個叢集是正確可用的了。
接著是hive的相關操作:
1.建立資料庫:
![]() 、
、

2.建立資料表

Or


語法規則:



注意為了正確的裝載,需要將爬取到的內容中的 ,(逗號)以及 \n(換行符號轉義)
修改mysql 的預設編碼:
![]()

![]()
修改配置,使得centos支援顯示中文:

若沒有,則要下載:
![]()



注意,以上的所有設定對centos的預設字元介面是不會生效的,只能用外接的命令列。。。
將需要檢索的結果進行分表:



統計:




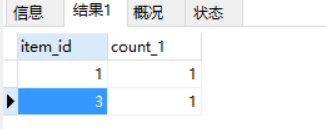
繼續統計:
![]()
轉換率計算:


針對競賽的解決方案:(統計總帖子數)
![]()
![]()

2,統計總使用者數:
![]()