
《17.Residual Attention Network for Image Classification》
阿新 • • 發佈:2018-11-24
動機
- 深度學習中的Attention,源自於人腦的注意力機制,當人的大腦接受到外部資訊,如視覺資訊、聽覺資訊時,往往不會對全部資訊進行處理和理解,而只會將注意力集中在部分顯著或者感興趣的資訊上,這樣有助於濾除不重要的資訊,而提升資訊處理的效率。
- 最早將Attention利用在影象處理上的出發點是,希望通過一個類似於人腦注意力的機制,只利用一個很小的感受野去處理影象中Attention的部分,降低了計算的維度。
- 而後來慢慢的,有人發現其實卷積神經網路自帶Attention的功能,比方說在分類任務中,高層的feature map所啟用的pixel也恰好集中在與分類任務相關的區域,也就是salience map,常被用在影象檢測和分割上。那麼如何利用Attention來提升模型在分類任務上的效能呢?本文提供了一種新的思路。
以前的方法
- 在圖片分類中,自上而下的注意力機制應用不同方法
- 序列處理:model問題為序列決策
- 區域推薦:
- 控制門:LSTM
創新
- 提出了一種可堆疊的網路結構。與ResNet中的Residual Block類似,本文所提出的網路結構也是通過一個Residual Attention Module的結構進行堆疊,可使網路模型能夠很容易的達到很深的層次。
- 提出了一種基於Attention的殘差學習方式。與ResNet也一樣,本文做提出的模型也是通過一種殘差的方式,使得非常深的模型能夠容易的優化和學習,並且具有非常好的效能。
- Bottom-up Top-down的前向Attention機制。其他利用Attention的網路,往往需要在原有網路的基礎上新增一個分支來提取Attention,並進行單獨的訓練,而本文提出的模型能夠就在一個前向過程中就提取模型的Attention,使得模型訓練更加簡單。
優勢
- 利用mask分支學習特徵權值:可以一直在更新trunk分支權值的時候錯誤的梯度,對噪聲更魯棒;
方法
- 下圖基本上可以囊括本位的絕大部分內容,對於某一層的輸出feature map,也就是下一層的輸入,對於一個普通的網路,只有右半部分,也就是Trunk Branch,作者在這個基礎上增加了左半部分:Soft Mask Branch——一個Bottom-up Top-down的結構。
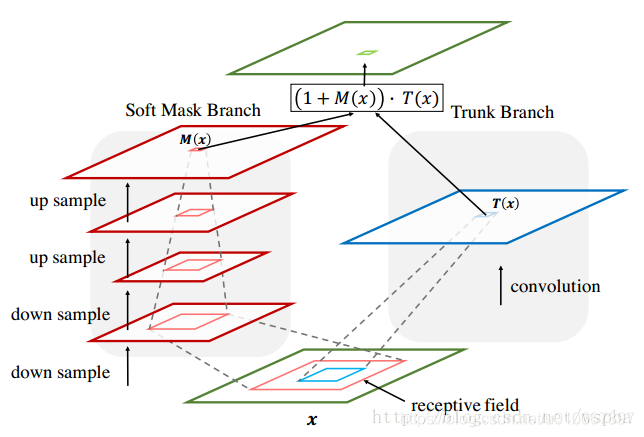
- Bottom-up Top-down的結構首先通過一系列的卷積和pooling,逐漸提取高層特徵並增大模型的感受野,之前說過高層特徵中所啟用的Pixel能夠反映Attention所在的區域,於是再通過相同數量的up sample將feature map的尺寸放大到與原始輸入一樣大,這樣就將Attention的區域對應到輸入的每一個pixel上,我們稱之為Attention map。Bottom-up Top-down這種encoder-decoder的結構在影象分割中用的比較多,如FCN,也正好是利用了這種結構相當於一個weakly-supervised的定位任務的學習。
- 接下來就要把Soft Mask Branch與Trunk Branch的輸出結合起來,Soft Mask Branch輸出的Attention map中的每一個pixel值相當於對原始feature map上每一個pixel值的權重,它會增強有意義的特徵,而抑制無意義的資訊,因此,將Soft Mask Branch與Trunk Branch輸出的feature map進行element-wised的乘法,就得到了一個weighted Attention map。但是無法直接將這個weighted Attention map輸入到下一層中,因為Soft Mask Branch的啟用函式是Sigmoid,輸出值在(0,1)之間(之所以這麼做,我認為是不希望給前後兩層的feature map帶來太大的差異和擾動,其次能夠進一步的抑制不重要的資訊),因此通過一系列這樣的乘法,將會導致feature map的值越來越小,並且也可能打破原始網路的特性,當層次極深時,給訓練帶來了很大的困難。因此作者在得到了weighted Attention map之後又與原來Trunk Branch的feature map進行了一個element-wised的操作,這就和ResNet有異曲同工之妙,該層的輸出由下面這個式子組成:
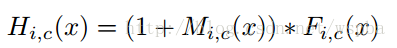
- 其中M(x)為Soft Mask Branch的輸出,F(x)為Trunk Branch的輸出,那麼當M(x)=0時,該層的輸入就等於F(x),因此該層的效果不可能比原始的F(x)差,這一點也借鑑了ResNet中恆等對映的思想,同時這樣的加法,也使得Trunk Branch輸出的feature map中顯著的特徵更加顯著,增加了特徵的判別性。這樣,優化的問題解決了,效能的問題也解決了,因此通過將這種殘差結構進行堆疊,就能夠很容易的將模型的深度達到很深的層次,具有非常好的效能。
-
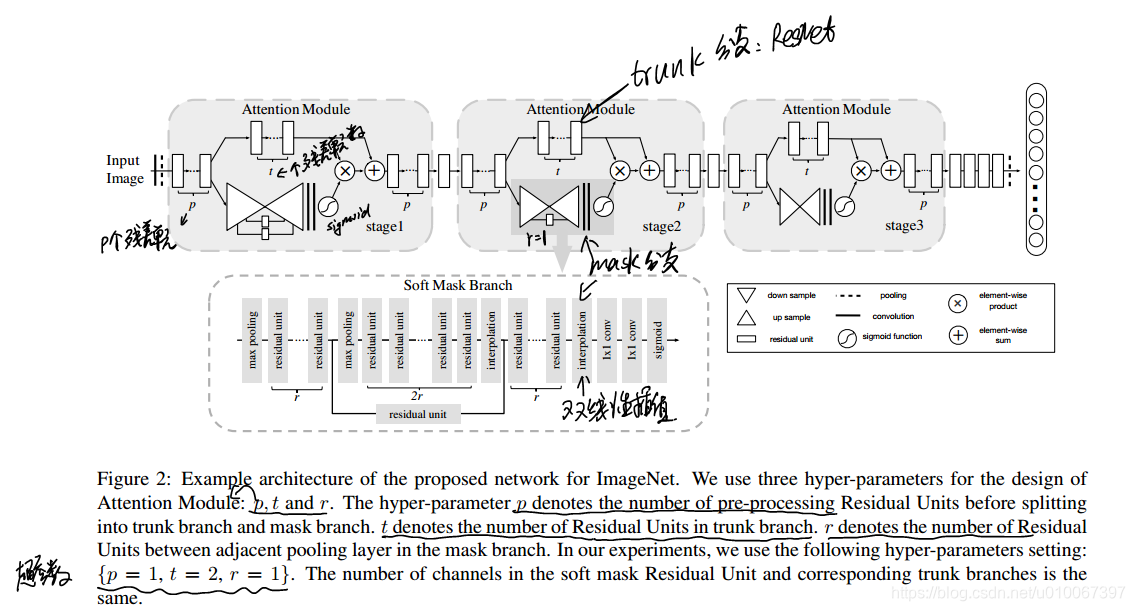
上圖是利用Residual Attention Module進行堆疊得到的模型結構,三個stage,由淺到深提取不同層次的Attention資訊,值得注意的是,網路中的每一個unit都可以換成目前具有非常好效能的結構,如Residual Block、Inception Block,換個角度說,就是可以將這個Attention的結構無縫連線到目前最優秀的網路中去,使得模型的效能更上一層樓。
-
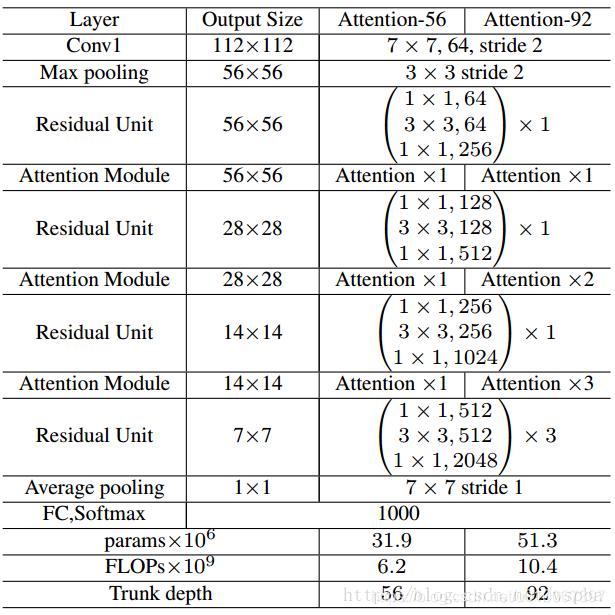
下圖是一個使用在ResNet-50上的例子,可以看出來和原始的ResNet的區別就是在每個階段的Residual Block之間增加了Attention Module,這裡有一個小trick,就是在每一個Attention Module的Soft Mask Branch中,作者使得down sample到的最小feature map的尺寸與整個網路中的最小feature map大小一致,首先7x7的feature map對於Attention來說不至於那麼粗糙,作者不希望在淺層的Attention丟失的資訊太多,其次也保證了它們具有相同大小的感受野。至於這麼做到底能提升多大的效能,這裡也很難判定。
實驗
- 作者在ImageNet資料集上與ResNet、Inception-ResNet等一系列當下最優秀的方法進行了比較:
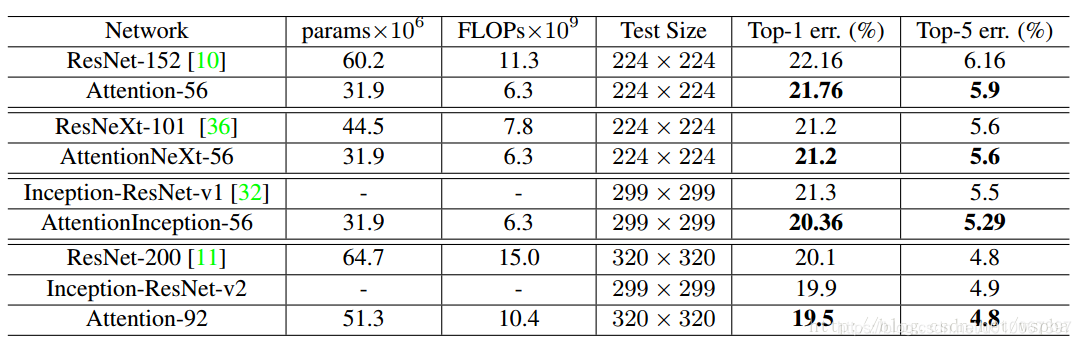
- 作者使用了不同的Attention unit,得到了結果也比原始的網路有不少的提升,這也有力的證明了Attention的效果,以及作者這種Residual Attention學習的有效性。
總結
- 將已有的結構當做是積木,搭建你自己系統的時候如果需要,或者可以用上,就要拿來,解決問題而不是創造積木。看論文的時候,不僅要知道它是如何使用,更要了解它的本質和思路,並能夠作為己用,這才能最大的提升學習的效果。