
論文解讀:Stacked Attention Networks for Image Question Answering
這是關於VQA問題的第二篇系列文章,這篇文章在vqa領域是一篇比較有影響的文章。本篇文章將介紹論文:主要思想;模型方法;主要貢獻。有興趣可以檢視原文:Stacked Attention Networks for Image Question Answering。原論文中附有作者原始碼。
1,論文想法
作者認為在vqa(影象問答中),帶有一定的推理過程。比如:“what are sitting in the basket on a bicycl”,在這個問題中,按照人為的思路,先定位到自行車,再定位到自行車的蘭州,最後看籃子上是什麼。這是個推理過程
作者採用attention機制來實現這種分層關注的推理過程。在問題特徵提取和影象特徵提取的思路並沒有很特殊,採用LSTM,CNN網路來提取特徵。然後用問題特徵去attention影象,用attention的結果結合問題向量再次去attention影象,最後產生預測。
(ps:論文的數學公式是LSTM,TextCNN,attention的公式,沒有其他的數學公式,有疑問可以補補,這篇文章不會從數學的角度介紹)
2,模型
模型和大多數的vqa問題一樣,有三部分組成,影象特徵、文字特徵、attention部分。

a.影象特徵提取
利用VGGNet提取影象特徵,選擇的特徵是最後一層池化層(last pooling layer)的特徵,這層很好的保持了原始影象的空間資訊。首先將影象尺寸改為448x448,經過VGGNet處理之後,提取的feature map 是512x14x14。14x14是區域的數量,512是每個區域向量的維度,每個feature map對應影象中32x32大小的區域。
b.問題特徵:採用LSTM或者TextCNN

c.Stacked Attention Networks
通過多次迭代實現影象區域的Attention。第一次用文字向量去attention影象,得到一個向量;用得到的attention向量加上問題向量,再次去attention影象,得到新的attention向量。之後重複這個過程,最後用softmax預測。
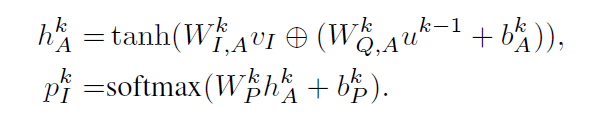
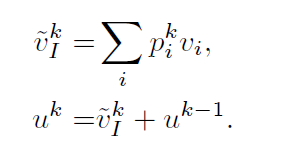
3,主要貢獻
- 提出SAN模型處理VQA任務;
- 在四個資料集上驗證SAN模型的效能;
- 詳細的分析了SAN不同層的輸出,證明了每次attention都是一次推理的過程。 每次attention都可以關注更細的內容