
Scrapy爬取Ajax(非同步載入)網頁例項——簡書付費連載
這兩天學習了Scrapy爬蟲框架的基本使用,練習的例子爬取的都是傳統的直接載入完網頁的內容,就想試試爬取用Ajax技術載入的網頁。
這裡以簡書裡的優選連載網頁為例分享一下我的爬取過程。
網址為:
https://www.jianshu.com/mobile/books?category_id=284
一、分析網頁
進入之後,滑鼠下拉發現內容會不斷更新,網址資訊也沒有發生變化,於是就可以判斷這個網頁使用了非同步載入技術。
 f
f
首先明確爬取的內容,本次我爬取的是作品名稱、照片、作者、閱讀量。然後將照片下載儲存在資料夾中,然後將全部內容生成csv資料夾儲存。
檢視網頁原始碼發現程式碼裡只有已載入的作品的內容,編寫爬蟲程式碼發現爬取不到收錄的資訊。
進入Network選項,勾選XHR選項,通過下滑網頁發現Network選項卡會載入檔案,如下圖:
注:這裡我用的是火狐瀏覽器

點選其中一個載入檔案,可以在訊息頭看到請求網址:
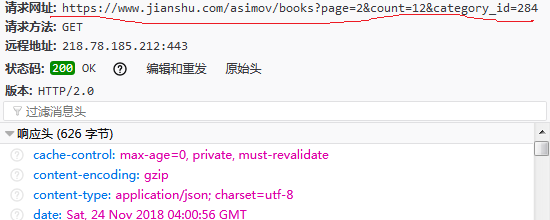
繼續下滑,發現Headers部分請求的URL只是page後面的數字在改變,通過改變數字,我們就能在後面呼叫回撥函式爬取多個網頁了。
二、Scrapy爬取
1.在命令提示符輸入:
cd Desktop #進入桌面 scrapy startproject jian #生成名為jian的Scrapy資料夾
cd jian
scrapy genspider lianzai jianshu.com #爬蟲名為lianzai
這裡我用的是pycharm,開啟資料夾。

2.在items.py定義爬蟲欄位
1 class JianItem(scrapy.Item): 2 # define the fields for your item here like: 3 # name = scrapy.Field() 4 book_name=scrapy.Field() 5 img=scrapy.Field() 6 author=scrapy.Field() 7 readers=scrapy.Field() 8 pass
3.在lianzai.py編寫爬蟲程式碼,爬取資料
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from jian.items import JianItem 4 import json 5 import requests 6 7 class LianzaiSpider(scrapy.Spider): 8 name = 'lianzai' 9 allowed_domains = ['jianshu.com'] 10 start_urls = ['https://www.jianshu.com/asimov/books?page=1&count=12&category_id=284'] #第一頁的url 11 def parse(self, response): 12 data=json.loads(response.body) #str轉為json物件 13 try: 14 for i in range(0, 12): 15 item = JianItem() 16 img=data['books'][i]['image_url'] 17 book_name=data['books'][i]['name'] 18 author=data['books'][i]['user']['nickname'] 19 readers=data['books'][i]['views_count'] 20 21 item['img']=img 22 item['book_name']=book_name 23 item['author']=author 24 item['readers']=readers 25 yield item #返回資料 26 except IndexError: 27 pass 28 urls=['https://www.jianshu.com/asimov/books?page={}&count=12&category_id=284'.format(str(i))for i in range(2, 11)] # 29 for url in urls: 30 yield scrapy.Request(url,callback=self.parse) #回撥函式
這裡特別要注意的是要爬取內容的所在位置。
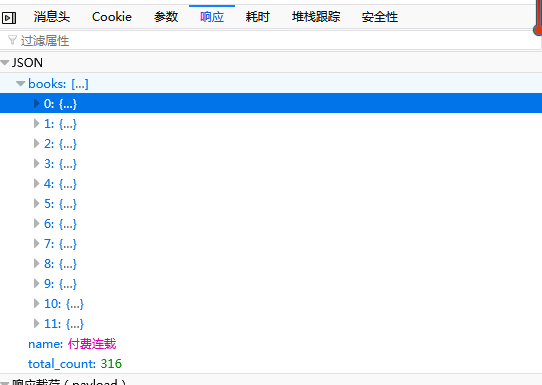
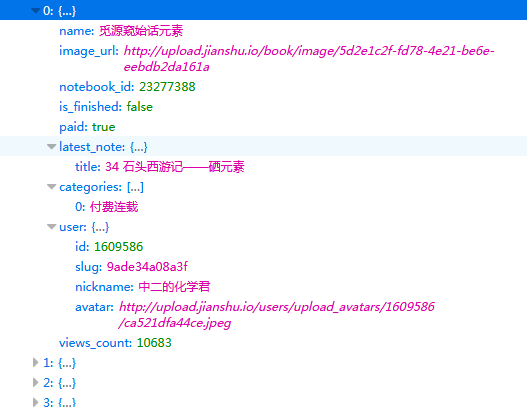
上圖中左圖可以看出爬取的內容的位置在response裡的['books']裡面,且一個網頁有12個作品,因此上面迴圈出為(0,12)。
開啟後如上右圖,可以看到我們要爬取的作品名、圖片地址、作者、閱讀量都在裡面,爬取就相對容易了。
4.在setting.py設定爬蟲配置
1 USER_AGENT='Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36' #請求頭 2 DOWNLOAD_DELAY=0.5 #延時0.5 3 FEED_URI='file:C:/Users/lenovo/Desktop/jianshulianzai.csv' #在桌面生成CSV檔案 4 FEED_FORMAT='csv' #存入 5 ITEM_PIPELINES={'jian.pipelines.JianPipeline':300}
5.在pipelines.py處理照片資料
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 import os 8 import urllib.request 9 10 class JianPipeline(object): 11 def process_item(self, item, spider): 12 headers = { 13 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36' 14 } 15 try: 16 if item['img'] != None: 17 req=urllib.request.Request(url=item['img'],headers=headers) 18 res=urllib.request.urlopen(req) 19 file_name = os.path.join(r'C:\Users\lenovo\Desktop\my_pic', item['book_name'] + '.jpg') 20 with open(file_name,'wb')as f: 21 f.write(res.read()) 22 except urllib.request.URLError: 23 pass 24 return item
6.全部儲存後,在命令列終端輸入:
scrapy crawl lianzai
就將結果爬取下來並儲存啦。
三、結果
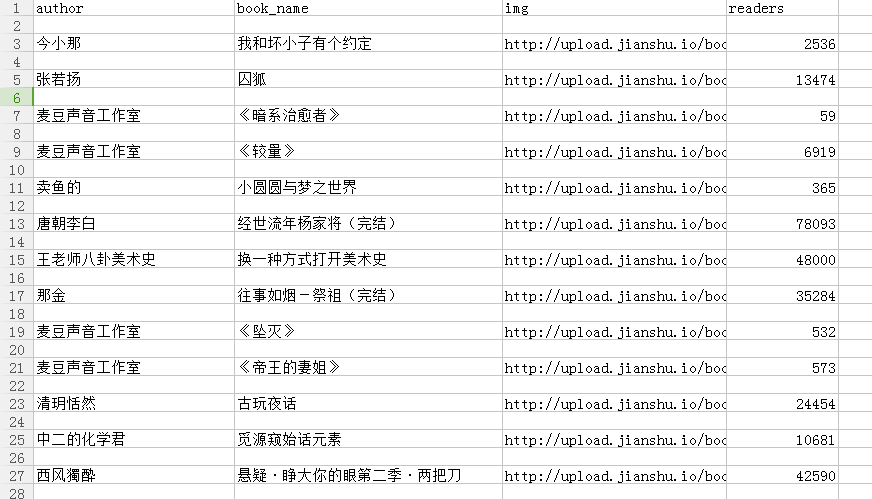
.csv檔案的內容:
下載的照片:

初入爬蟲,還有很多不足需要改正,還有很多知識需要學習,希望有疑問或建議的朋友多多指正或留言。謝謝。