
Scrapy爬取前程無憂(51job)相關職位資訊
阿新 • • 發佈:2018-12-22
Scrapy爬取前程無憂(51job)python職位資訊
開始是想做資料分析的,上網上找教程,看到相關部落格我就跟著做,但是沒資料就只能開始自己爬唄。順便給51job的工作人員提提建議,我爬的時候Scrapy訪問量開到128,relay僅有兩秒,還以為會封ip。沒想到只是改請求頭就能萬事大吉。。。這基本算是沒有反扒機制吧。而且後面資料清洗的時候發現很多虛假的招聘廣告,這個應該官方可以控制下吧。
靈感來源:https://www.jianshu.com/p/309493fe5c7b ,https://blog.csdn.net/lbship/article/details/79452459
簡單分析
進入官網搜尋python,跳轉到:https://search.51job.com/list/000000%252C00,000000,0000,00,9,99,python,2,1.html,後面還有一長串不知道是什麼的資訊,經過測試沒什麼用。自主要的是.html前的數字,你可以改成2,就明白我的意思了。沒有scrapy的可以先看這篇:https://www.imooc.com/learn/1017
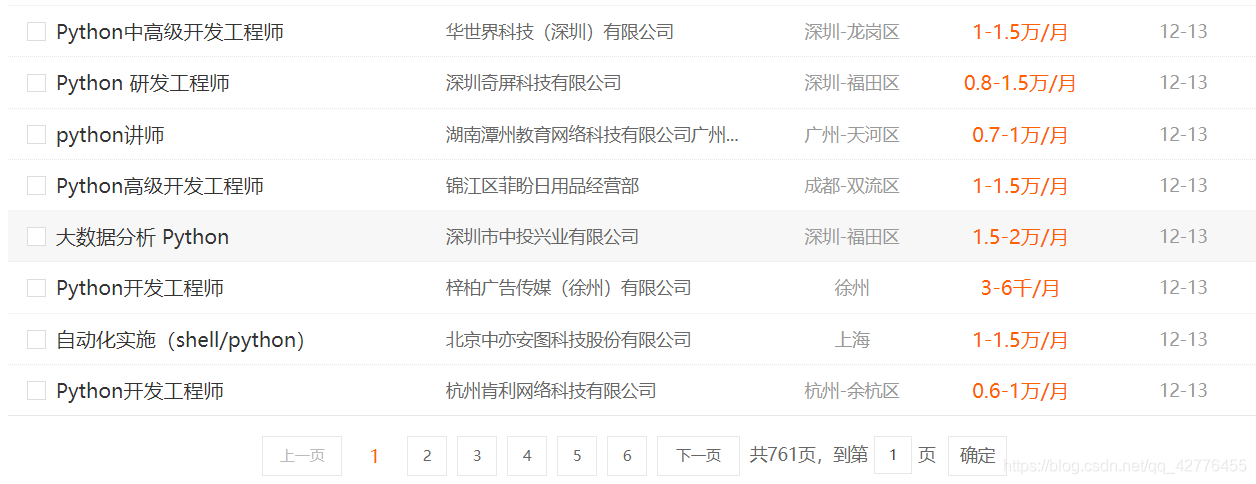
網頁結構很清晰,parse()函式裡xpath或者css拿到對應的列表資訊,再解析每一條yield item,最後爬取完一頁之後,判斷是否為最後一頁,跳到下一頁繼續爬取。
class JobspiderSpider(scrapy.Spider): name = 'jobSpider' allowed_domains = ['51job.com'] start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html'] def parse(self, response): jobs = response.xpath('//*[@id="resultList"]/div[@class="el"]') item = S1JobobpypositionItem() for job in jobs: position = job.xpath('./p//a/@title').extract_first() company = job.xpath('./span[1]/a/@title').extract_first() location = job.xpath('./span[2]/text()').extract_first() salary = job.xpath('./span[3]/text()').extract_first() time = job.xpath('./span[4]/text()').extract_first() item['position'] = position item['company'] = company item['location'] = location item['salary'] = salary item['time'] = time print (item) yield item page_total = response.xpath('//*[@id="resultList"]//span[@class="td"]/text()').extract_first() next_page_url = response.css('#resultList li.bk a::attr(href)').extract()[-1] if next_page_url: yield scrapy.Request(url=next_page_url,callback=self.parse)
item裡的資料在piplines中儲存到mysql資料庫(有關mysql資料庫的連結:https://blog.csdn.net/qq_42776455/article/details/82959857 ):
class saveMysql(object): def __init__(self): self.client = pymysql.Connect( host='localhost', port=3306, user='root', passwd='root', db='51job', charset='utf8' ) self.cursor = self.client.cursor() def process_item(self,item,spider): sql = 'insert into python_jobs (position,company,salary,location,time) values ("%s","%s","%s","%s","%s")' self.cursor.execute(sql % (item['position'],item['company'],item['salary'],item['location'],item['time'])) self.client.commit() def close_spider(self, spider): self.cursor.close() self.client.close()
記得在settings裡新增配置。
新增中介軟體構造請求頭:https://blog.csdn.net/qq_42776455/article/details/83150012
結果:
