
《推薦系統實踐》第四章 利用使用者標籤資料
目前流行的推薦系統基本上通過3種方式聯絡使用者興趣和物品。
第一種方式是利用使用者喜歡過的物品,給使用者推薦與他喜歡過的物品相似的物品,這就是前面提到的基於物品的演算法。
第二種方式是利用和使用者興趣相似的其他使用者,給使用者推薦那些和他們興趣愛好相似的其他使用者喜歡的物品,這是前面提到的基於使用者的演算法。
第三種重要的方式是通過一些特徵(feature)聯絡使用者和物品,給使用者推薦那些具有使用者喜歡的特徵的物品。

根據給物品打標籤的人的不同,標籤應用一般分為兩種:一種是讓作者或者專家給物品打標籤;另一種是讓普通使用者給物品打標籤,也就是UGC(User Generated Content,使用者生成的內容)的標籤應用。UGC的標籤系統是一種表示使用者興趣和物品語義的重要方式。
4.1 UGC 標籤系統的代表應用
使用UGC標籤系統的代表網站——UGC標籤系統的鼻祖Delicious、論文書籤網站CiteULike、音樂網站Last.fm、視訊網站Hulu、書和電影評論網站豆瓣等。
Delicious,允許使用者給網際網路上的每個網頁打標籤,從而通過標籤重新組織整個網際網路。
CiteULike,允許研究人員提交或者收藏自己感興趣的論文並且給論文打標籤,從而幫助使用者更好地發現和自己研究領域相關的優秀論文。
Last.fm,讓使用者用標籤標記音樂和歌手。
豆瓣,允許使用者對圖書和電影打標籤,藉此獲得圖書和電影的內容資訊和語義,並用這種資訊改善推薦效果。
Hulu,讓使用者對電視劇和電影進行標記。
標籤系統的最大優勢在於可以發揮群體的智慧,獲得對物品內容資訊比較準確的關鍵詞描述,而準確的內容資訊是提升個性化推薦系統性能的重要資源。
標籤系統的不同作用,以及每種作用能夠影響多大的人群,如下所示。
(1)表達:標籤系統幫助我表達對物品的看法。(30%的使用者同意。)
(2)組織:打標籤幫助我組織我喜歡的電影。(23%的使用者同意。)
(3)學習:打標籤幫助我增加對電影的瞭解。(27%的使用者同意。)
(4)發現:標籤系統使我更容易發現喜歡的電影。(19%的使用者同意。)
(5)決策:標籤系統幫助我判定是否看某一部電影。(14%的使用者同意。)
4.2 標籤系統中的推薦問題
標籤系統中的推薦問題主要有以下兩個。
(1)如何利用使用者打標籤的行為為其推薦物品(基於標籤的推薦)?
(2)如何在使用者給物品打標籤時為其推薦適合該物品的標籤(標籤推薦)?
為了研究上面的兩個問題,我們首先需要解答下面3個問題。
使用者為什麼要打標籤?
使用者怎麼打標籤?
使用者打什麼樣的標籤?
4.2.1 使用者為什麼進行標註
首先是社會維度,有些使用者標註是給內容上傳者使用的(便於上傳者組織自己的資訊),而有些使用者標註是給廣大使用者使用的(便於幫助其他使用者找到資訊)。另一個維度是功能維度,有些標註用於更好地組織內容,方便使用者將來的查詢,而另一些標註用於傳達某種資訊,比如照片的拍攝時間和地點等。
4.2.2 使用者如何打標籤
Delicious資料集(參見 http://www.dai-labor.de/en/competence_centers/irml/datasets/),該資料集包含2003年9月到2007年12月Delicious使用者4.2億條標籤行為記錄。
標籤的流行度分佈也呈現非常典型的長尾分佈,它的雙對數曲線幾乎是一條直線。

4.2.3 使用者打什麼樣的標籤
Delicious上的標籤分為如下幾類。
(1)表明物品是什麼,比如是一隻鳥,就會有“鳥”這個詞的標籤。
(2)表明物品的種類,比如在Delicious的書籤中,表示一個網頁類別的標籤包括 article(文章)、blog(部落格)、 book(圖書)等。
(3)表明誰擁有物品,比如很多部落格的標籤中會包括部落格的作者等資訊。
(4)表達使用者的觀點,比如使用者認為網頁很有趣,就會打上標籤funny(有趣),認為很無聊,就會打上標籤boring(無聊)。
(5)使用者相關的標籤,比如 my favorite(我最喜歡的)、my comment(我的評論)等。
(6)使用者的任務,比如 to read(即將閱讀)、job search(找工作)等。
很多不同的網站也設計了自己的標籤分類系統,比如Hulu對視訊的標籤就做了分類。
型別(Genre) 主要表示這個電視劇的類別,比如《豪斯醫生》屬於醫學劇情片(medical drama)。
時間(Time) 主要包括電視劇釋出的時間,有時也包括電視劇中事件發生的時間,比如20世紀90年代。
人物(People) 主要包括電視劇的導演、演員和劇中重要人物等。
地點(Place) 劇情發生的地點,或者視訊拍攝的地點等。
語言(Language) 這部電視劇使用的語言。
獎項(Awards) 這部電視劇獲得的相關獎項。
其他(Details) 包含不能歸類到上面各類中的其他所有標籤。
4.3 基於標籤的推薦系統
一個使用者標籤行為的資料集一般由一個三元組的集合表示,其中記錄(u, i, b) 表示使用者u給物品i打上了標籤b。
採用兩個不同的資料集評測基於標籤的物品推薦演算法。一個是Delicious資料集,另一個是CiteULike資料集。
4.3.1 實驗設定
將資料集隨機分成10份。這裡分割的鍵值是使用者和物品,不包括標籤。也就是說,使用者對物品的多個標籤記錄要麼都被分進訓練集,要麼都被分進測試集,不會一部分在訓練集,另一部分在測試集中。然後,我們挑選1份作為測試集,剩下的9份作為訓練集,通過學習訓練集中的使用者標籤資料預測測試集上使用者會給什麼物品打標籤。
對於使用者u,令R(u)為給使用者u的長度為N的推薦列表,裡面包含我們認為使用者會打標籤的物品。令T(u)是測試集中使用者u實際上打過標籤的物品集合。然後,我們利用準確率(precision)和召回率(recall)評測個性化推薦演算法的精度。
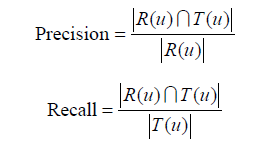
覆蓋率的計算公式如下:
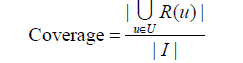
用物品標籤向量的餘弦相似度度量物品之間的相似度。
def CosineSim(item_tags, i, j):
ret = 0
for b,wib in item_tags[i].items():
if b in item_tags[j]:
ret += wib * item_tags[j][b]
ni = 0
nj = 0
for b, w in item_tags[i].items():
ni += w * w
for b, w in item_tags[j].items():
nj += w * w
if ret == 0:
return 0
return ret / math.sqrt(ni * nj)在得到物品之間的相似度度量後,我們通過如下公式計算一個推薦列表的多樣性。推薦系統的多樣性為所有使用者推薦列表多樣性的平均值。
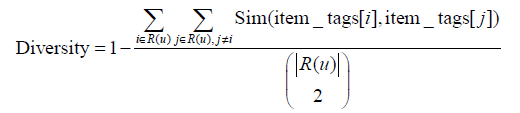
def Diversity(item_tags, recommend_items):
ret = 0
n = 0
for i in recommend_items.keys():
for j in recommend_items.keys():
if i == j:
continue
ret += CosineSim(item_tags, i, j)
n += 1
return ret / (n * 1.0)至於推薦結果的新穎性,我們簡單地用推薦結果的平均熱門程度(AveragePopularity)度量。對於物品i,定義它的流行度item_pop(i)為給這個物品打過標籤的使用者數。而對推薦系統,我們定義它的平均熱門度如下:
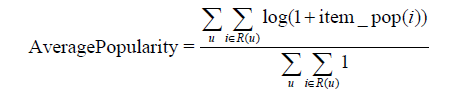
4.3.2 一個最簡單的演算法
最簡單的個性化推薦演算法:
(1)統計每個使用者最常用的標籤。
(2)對於每個標籤,統計被打過這個標籤次數最多的物品。
(3)對於一個使用者,首先找到他常用的標籤,然後找到具有這些標籤的最熱門物品推薦給這個使用者。
對於上面的演算法,使用者u對物品i的興趣公式如下:
![]() ,B(u)是使用者u打過的標籤集合,B(i)是物品i被打過的標籤集合,
,B(u)是使用者u打過的標籤集合,B(i)是物品i被打過的標籤集合,是使用者u打過標籤b的次數,
i是物品i被打過標籤b的次數。

4.3.3 演算法的改進
1. TF-IDF
前面的演算法傾向於給熱門標籤對應的熱門物品很大的權重,因此會造成推薦熱門的物品給使用者,從而降低推薦結果的新穎性。另外,這個公式利用使用者的標籤向量對使用者興趣建模,其中每個標籤都是使用者使用過的標籤,而標籤的權重是使用者使用該標籤的次數。這種建模方法的缺點是給熱門標籤過大的權重,從而不能反應使用者個性化的興趣。這裡我們可以借鑑TF-IDF的思想,對這一公式進行改進:
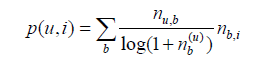 ,
,記錄了標籤b被多少個不同的使用者使用過。這個演算法記為TagBasedTFIDF。

同理,我們也可以借鑑TF-IDF的思想對熱門物品進行懲罰,從而得到如下公式:
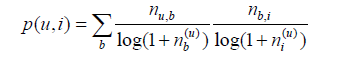 ,
,記錄了物品i被多少個不同的使用者打過標籤。這個演算法記為TagBasedTFIDF++。

適當懲罰熱門標籤和熱門物品,在增進推薦結果個性化的同時並不會降低推薦結果的離線精度。
2. 資料稀疏性
為了提高推薦的準確率,我們可能要對標籤集合做擴充套件,我們可以將這個標籤的相似標籤也加入到使用者標籤集合中。
進行標籤擴充套件有很多方法,其中常用的有話題模型(topic model),不過這裡遵循簡單的原則介紹一種基於鄰域的方法。
標籤擴充套件的本質是對每個標籤找到和它相似的標籤,也就是計算標籤之間的相似度。
如果認為同一個物品上的不同標籤具有某種相似度,那麼當兩個標籤同時出現在很多物品的標籤集合中時,我們就可以認為這兩個標籤具有較大的相似度。對於標籤b,令N(b)為有標籤b的物品的集合,n_{b,i}為給物品i打上標籤b的使用者數,我們可以通過如下餘弦相似度公式計算標籤b和標籤b'的相似度:
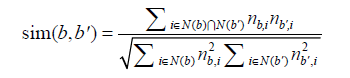
對於曾經打過的標籤數少於20的使用者,我們找到其所打標籤的相關標籤,然後將這些標籤聚合排序,將排序結果中前20個標籤作為使用者相關的標籤。表4-8展示了考慮標籤擴充套件後的推薦演算法效能。

進行標籤擴充套件確實能夠提高基於標籤的物品推薦的準確率和召回率,但可能會稍微降低推薦結果的覆蓋率和新穎度。
3. 標籤清理
不是所有標籤都能反應使用者的興趣。同時,標籤系統裡經常出現詞形不同、詞義相同的標籤。
標籤清理的另一個重要意義在於將標籤作為推薦解釋。如果我們要把標籤呈現給使用者,將其作為給使用者推薦某一個物品的解釋,對標籤的質量要求就很高。
一般來說有如下標籤清理方法:
去除詞頻很高的停止詞;
去除因詞根不同造成的同義詞;
去除因分隔符造成的同義詞;
為了控制標籤的質量,很多網站也採用了讓使用者進行反饋的思想,即讓使用者告訴系統某個標籤是否合適。
4.3.4 基於圖的推薦演算法
首先,我們需要將使用者打標籤的行為表示到一張圖上。在使用者標籤資料集上,有3種不同的元素,即使用者、物品和標籤。因此,我們需要定義3種不同的頂點,即使用者頂點、物品頂點和標籤頂點。然後,如果我們得到一個表示使用者u給物品i打了標籤b的使用者標籤行為(u,i,b),那麼最自然的想法就是在圖中增加3條邊,首先需要在使用者u對應的頂點v(u)和物品i對應的頂點v(i)之間增加一條邊(如果這兩個頂點已經有邊相連,那麼就應該將邊的權重加1),同理,在v(u)和v(b)之間需要增加一條邊,v(i)和v(b)之間也需要邊相連線。

在定義出使用者—物品—標籤圖後,我們可以用第2章提到的PersonalRank演算法計算所有物品節點相對於當前使用者節點在圖上的相關性,然後按照相關性從大到小的排序,給使用者推薦排名最高的N個物品。
4.3.5 基於標籤的推薦解釋
基於標籤的推薦其最大好處是可以利用標籤做推薦解釋,這方面的代表性應用是豆瓣的個性化推薦系統。
豆瓣讀書推薦結果包括兩部分。上面是一個標籤雲,表示使用者的興趣分佈,標籤的尺寸越大,表示使用者對這個標籤相關的圖書越感興趣。單擊標籤雲中的每一個標籤,都可以在標籤雲下方得到和這個標籤相關的圖書推薦。
豆瓣這樣組織推薦結果頁面有很多好處,首先是提高了推薦結果的多樣性。同時,標籤雲也提供了推薦解釋功能。
對基於標籤的解釋進行了深入研究,發現:
使用者對標籤的興趣對幫助使用者理解為什麼給他推薦某個物品更有幫助;
使用者對標籤的興趣和物品標籤相關度對於幫助使用者判定自己是否喜歡被推薦物品具有同
樣的作用;
物品標籤相關度對於幫助使用者判定被推薦物品是否符合他當前的興趣更有幫助;
客觀事實類標籤相比主觀感受類標籤對使用者更有作用。
4.4 給使用者推薦標籤
4.4.1 為什麼要給使用者推薦標籤
一般認為,給使用者推薦標籤有以下好處。
方便使用者輸入標籤
提高標籤質量
4.4.2 如何給使用者推薦標籤
第0種方法就是給使用者u推薦整個系統裡最熱門的標籤(這裡將這個演算法稱為PopularTags)。
第1種方法就是給使用者u推薦物品i上最熱門的標籤(這裡將這個演算法稱為ItemPopularTags)。
第2種方法是給使用者u推薦他自己經常使用的標籤(這裡將這個演算法稱為UserPopularTags)。
第3種演算法是前面兩種的融合(這裡記為HybridPopularTags),該方法通過一個係數將上面的推薦結果線性加權,然後生成最終的推薦結果。
def RecommendHybridPopularTags(user,item, user_tags, item_tags, alpha, N):
max_user_tag_weight = max(user_tags[user].values())
for tag, weight in user_tags[user].items():
ret[tag] = (1 – alpha) * weight / max_user_tag_weight
max_item_tag_weight = max(item_tags[item].values())
for tag, weight in item_tags[item].items():
if tag not in ret:
ret[tag] = alpha * weight / max_item_tag_weight
else:
ret[tag] += alpha * weight / max_item_tag_weight
return sorted(ret[user].items(), key=itemgetter(1), reverse=True)[0:N]4.4.3 實驗設定
法將資料集按照9∶1分成訓練集和測試集,然後通過訓練集學習使用者標註的模型。
對於測試集中的每一個使用者物品對(u,i),我們都會推薦N個標籤給使用者u作參考。令R(u,i)為我們給使用者u推薦的應該在物品i上打的標籤集合,令T(u,i)為使用者u實際給物品i打的標籤的集合,我們可以利用準確率和召回率評測標籤推薦的精度:

實驗結果



很多應用在給使用者推薦標籤時會直接給出使用者最常用的標籤,以及物品最經常被打的標籤。
基於統計使用者常用標籤和物品常用標籤的演算法有一個缺點,就是對新使用者或者不熱門的物品很難有推薦結果。解決這一問題有兩個思路。
第一個思路是從物品的內容資料中抽取關鍵詞作為標籤。
第二個思路是針對有結果,但結果不太多的情況。可以做一些關鍵詞擴充套件。
4.4.4 基於圖的標籤推薦演算法
圖模型同樣可以用於標籤推薦。在根據使用者打標籤的行為生成圖之後(如圖4-11所示),我們可以利用PersonalRank演算法進行排名。但這次遇到的問題和之前不同。這次的問題是,當用戶u遇到物品i時,會給物品i打什麼樣的標籤。因此,我們可以重新定義頂點的啟動概率,如下所示:
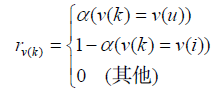
也就是說,只有使用者u和物品i對應的頂點有非0的啟動概率,而其他頂點的啟動概率都為0。在上面的定義中,v(u)和v(i)的啟動概率並不相同,v(u)的啟動概率是a,而v(i)的啟動概率是1-a。引數α可以通過離線實驗選擇。
4.5 擴充套件閱讀
基於標籤的推薦系統比賽,比賽介紹見 http://www.kde.cs.uni-kassel.de/ws/rsdc08/program.html。
在這些研究中湧現了很多新的方法,比如張量分解(tensor factorization)(參見Panagiotis Symeonidis、Alexandros Nanopoulos和Yannis Manolopoulos的“Tag recommendations based on tensor dimensionality reduction”(ACM 2008 Article,2008))、基於LDA的演算法(參見Ralf Krestel、 Peter Fankhauser和Wolfgang Nejdl的“Latent dirichlet allocation for tag recommendation”(ACM 2009 Article,2009))、基於圖的演算法(參見Andreas Hotho、 Robert Jäschke、 Christoph Schmitz和Gerd Stumme的“Folkrank: A ranking algorithm for folksonomies”(Proc. FGIR 2006,2006))等。不過這些演算法很多具有較高的複雜度,在實際系統中應用起來還有很多實際的困難需要解決。
研究如何利用標籤聯絡使用者和物品並給使用者進行個性化電影推薦,參見Shilad Wieland Sen、 Jesse Vig和John Riedl的“Tagommenders: Connecting Users to Items through Tags”(ACM 2009 Article,2009)。
研究如何利用標籤進行推薦解釋,他將使用者和物品之間的關係轉化為使用者對標籤的興趣(tag preference)以及標籤和物品的相關度(tag relevance)兩種因素。參見Jesse Vig、Shilad Wieland Sen和John Riedl的“Tagsplanations: Explaining Recommendations Using Tags”(ACM 2009 Article,2009)。
研究如何對標籤進行清理,以及如何選擇合適的標籤進行解釋。參見Shilad Wieland Sen、F. Maxwell Harper、Adam LaPitz和John Riedl的“The quest for quality tags”(ACM 2007 Article,2007)。