
利用HOG+SVM實現行人檢測
阿新 • • 發佈:2018-11-24
利用HOG+SVM實現行人檢測
很久以前做的行人檢測,現在稍加溫習,上傳記錄一下。
首先解析視訊,提取視訊的每一幀形成圖片存到磁碟。程式碼如下
import os import cv2 videos_src_path = 'D:\\test1' videos_save_path = 'D:\\test2' videos = os.listdir(videos_src_path) videos = filter(lambda x: x.endswith('avi'), videos) for each_video in videos: print (each_video) # get the name of each video, and make the directory to save frames each_video_name, _ = each_video.split('.') os.mkdir(videos_save_path + '/' + each_video_name) each_video_save_full_path = os.path.join(videos_save_path, each_video_name) + '/' # get the full path of each video, which will open the video tp extract frames each_video_full_path = os.path.join(videos_src_path, each_video) cap = cv2.VideoCapture(each_video_full_path) frame_count = 1 success = True while(success): success, frame = cap.read() print ('Read a new frame: ', success) params = [] params.append(1) params.append(1) cv2.imwrite(each_video_save_full_path + each_video_name + "_%05d.ppm" % frame_count, frame, params) frame_count = frame_count + 1 cap.release()
對於圖片的行人檢測應用了梯度方向直方圖和支援向量機。程式碼如下
這段程式碼可以實現對行人的標記。
# import the necessary packages from __future__ import print_function from imutils.object_detection import non_max_suppression from imutils import paths import numpy as np import argparse import imutils import cv2 import os # initialize the HOG descriptor/person detector hog = cv2.HOGDescriptor() hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector()) list = [] path = 'D:\\test2\\111' videos = os.listdir(path) videos = filter(lambda x: x.endswith('ppm'), videos) for each in videos: new_path=path + "\\" + each list.append(new_path) # loop over the image paths for imagePath in list: # load the image and resize it to (1) reduce detection time # and (2) improve detection accuracy image = cv2.imread(imagePath) image = imutils.resize(image, width=min(400, image.shape[1])) orig = image.copy() # detect people in the image (rects, weights) = hog.detectMultiScale(image, winStride=(4, 4), padding=(8, 8), scale=1.05) # draw the original bounding boxes for (x, y, w, h) in rects: cv2.rectangle(orig, (x, y), (x + w, y + h), (0, 0, 255), 2) # apply non-maxima suppression to the bounding boxes using a # fairly large overlap threshold to try to maintain overlapping # boxes that are still people rects = np.array([[x, y, x + w, y + h] for (x, y, w, h) in rects]) pick = non_max_suppression(rects, probs=None, overlapThresh=0.65) # draw the final bounding boxes for (xA, yA, xB, yB) in pick: cv2.rectangle(image, (xA, yA), (xB, yB), (0, 255, 0), 2) # show some information on the number of bounding boxes filename = imagePath[imagePath.rfind("/") + 1:] print("[INFO] {}: {} original boxes, {} after suppression".format( filename, len(rects), len(pick))) # show the output images cv2.imshow("Before NMS", orig) cv2.imshow("After NMS", image) cv2.waitKey(1)
在這裡應用了非極大值抑制方法(NMS),處理了重疊標記的問題。但是這裡存在一個問題就是,部分兩個人物距離過近或者產生重疊的情況下,優化後會將兩個人標記稱為一個人,這個問題還沒有解決。
最後,將多張標記後的圖片按一定幀數還原成視訊,就完成了對視訊的行人檢測。 完整程式碼如下
# import the necessary packages from __future__ import print_function from imutils.object_detection import non_max_suppression from imutils import paths import numpy as np import argparse import imutils import cv2 import os ''' # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-i", "--images", required=True, help="path to images directory") args = vars(ap.parse_args()) ''' # initialize the HOG descriptor/person detector hog = cv2.HOGDescriptor() hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector()) list = [] path = 'D:\\test2\\111' videos = os.listdir(path) videos = filter(lambda x: x.endswith('ppm'), videos) for each in videos: new_path=path + "\\" + each list.append(new_path) fourcc = cv2.VideoWriter_fourcc(*'I420') videoWriter = cv2.VideoWriter('D:\\test2\\111\\saveVideo.avi',-1,24,(720,404)) # loop over the image paths for imagePath in list: # load the image and resize it to (1) reduce detection time # and (2) improve detection accuracy image = cv2.imread(imagePath) if image is None: break image = imutils.resize(image, width=min(400, image.shape[1])) orig = image.copy() # detect people in the image (rects, weights) = hog.detectMultiScale(image, winStride=(4, 4), padding=(8, 8), scale=1.05) # draw the original bounding boxes for (x, y, w, h) in rects: cv2.rectangle(orig, (x, y), (x + w, y + h), (0, 0, 255), 2) # apply non-maxima suppression to the bounding boxes using a # fairly large overlap threshold to try to maintain overlapping # boxes that are still people rects = np.array([[x, y, x + w, y + h] for (x, y, w, h) in rects]) pick = non_max_suppression(rects, probs=None, overlapThresh=0.65) # draw the final bounding boxes for (xA, yA, xB, yB) in pick: cv2.rectangle(image, (xA, yA), (xB, yB), (0, 255, 0), 2) # show some information on the number of bounding boxes filename = imagePath[imagePath.rfind("/") + 1:] print("[INFO] {}: {} original boxes, {} after suppression".format( filename, len(rects), len(pick))) # show the output images cv2.imshow("Before NMS", orig) cv2.imshow("After NMS", image) videoWriter.write(image) cv2.waitKey(1) videoWriter.release()
執行截圖如下
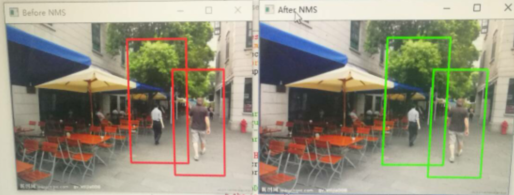
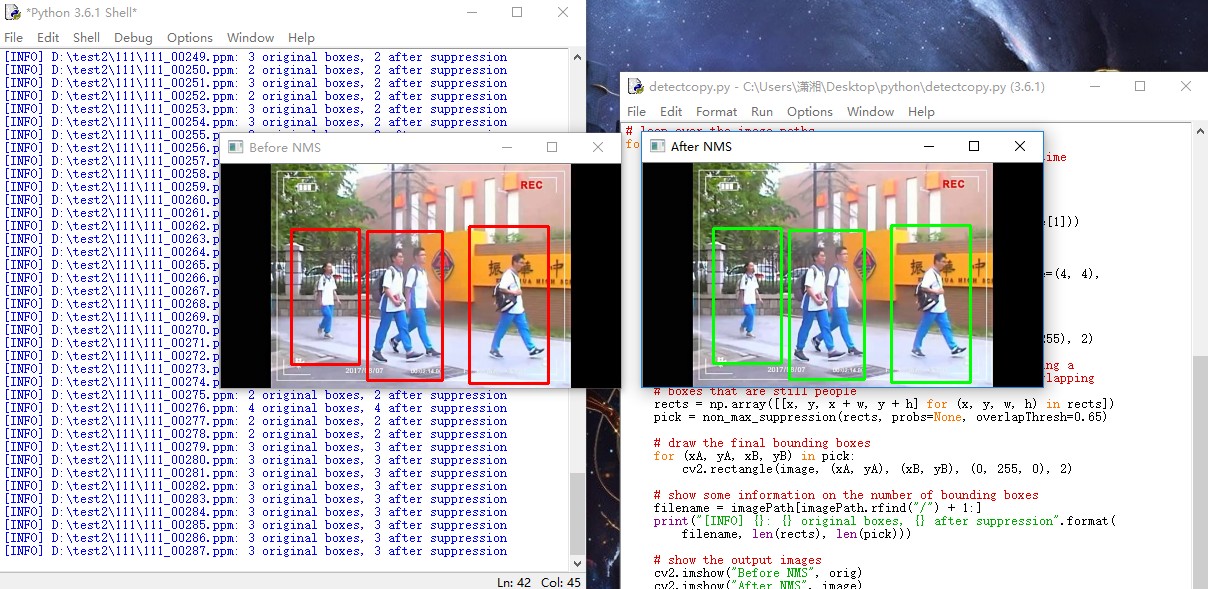
優化:預處理部分影象結果存在的磁碟上,導致執行速度偏難,可以先載入到記憶體中,以便加速。
關於視訊,沒有進行上下文處理,只是單純的將圖片合成視訊,沒有相互關聯起來。