
Redis構建處理海量資料的大型購物網站
本系列教程內容提要
Java工程師之Redis實戰系列教程教程是一個學習教程,是關於Java工程師的Redis知識的實戰系列教程,本系列教程均以解決特定問題為目標,使用Redis快速解決在實際生產中的相關問題,為了更方便的與大家一起探討與學習,每個章節均提供儘可能詳細的示例原始碼及註釋,所有示例原始碼均可在javacourse-redis-in-action找到相關幫助!
什麼是大型網站?
從技術上的角度來看,大型網站的實現是能夠應對各種突發事件,能夠處理海量資料等因素.... 這裡我們抓住“處理海量資料”這一點來進行探討學習。
何提高網站處理海量資料?
- 減少使用者請求體大小
- 響應資料進行快取

我們應該怎麼做?
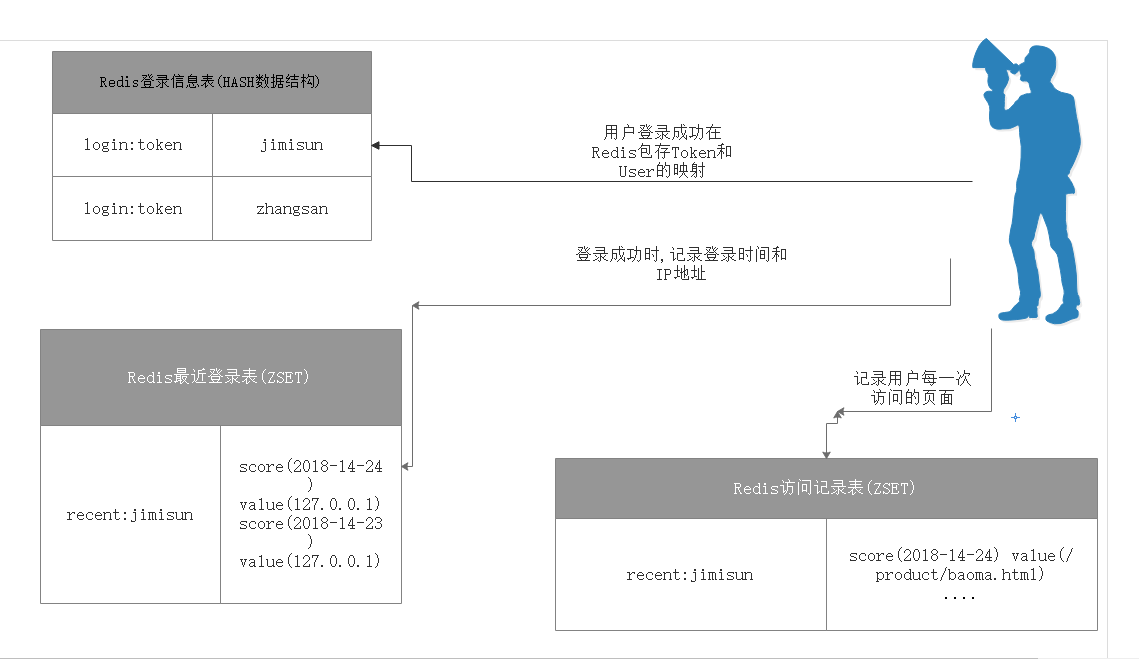
第一步:拒絕cookie,使用token令牌登入 github示例原始碼下載
Cookie是常見的記錄使用者會話的解決方案,但在某些場景下其並不適用,如前後端分離,如Cookie體積大時影響請求速率。
- 使用者發起操作請求
- Redis校驗是否擁有TOKEN令牌
- 沒有令牌跳轉登入
- 登入成功生成TOKEN儲存至Redis
- ......
Redis資料結構
核心原始碼
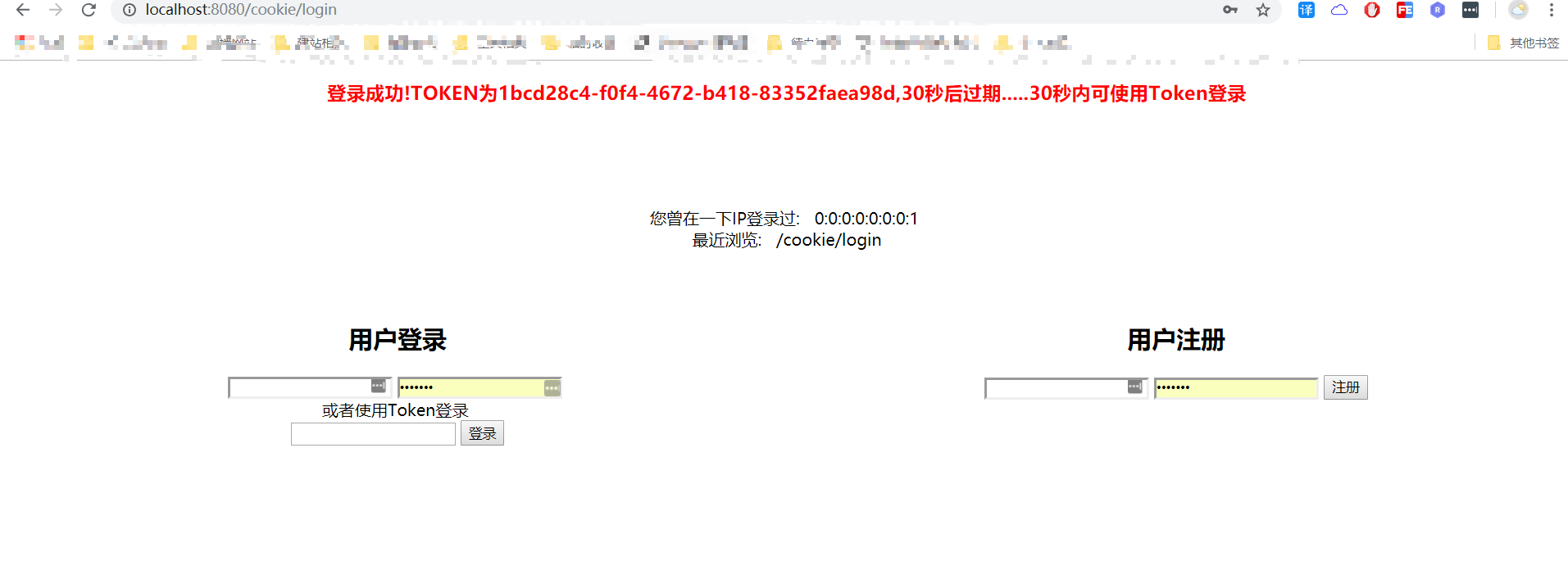
@RequestMapping("/register") public String register(User user, Model model) { userFactory.put(user.getUsername(), user); model.addAttribute("result", "註冊成功!"); return "RegAndLog"; } @RequestMapping("/login") public String login(User user, Model model, @RequestParam(required = false) String token, HttpServletRequest request) { Boolean exists = jedis.exists("login:" + token); String clientIp = getClientIp(request); String url = getURL(request); if (!exists) { User result = userFactory.get(user.getUsername()); if (result != null && user.getUsername().equals(result.getUsername()) && user.getPassword().equals(result.getPassword())) { /*將使用者登入快取到Redis*/ String tokenUUID = UUID.randomUUID().toString(); updateToken(jedis, tokenUUID, result, clientIp, url); /*獲取使用者的登入記錄*/ Set<String> IPList = jedis.zrange("recent:" + user.getUsername(), 0, -1); /*獲取使用者最新訪問的頁面*/ Set<String> URLList = jedis.zrange("viewed:" + user.getUsername(), 0, -1); model.addAttribute("record", IPList); model.addAttribute("URLList", URLList); model.addAttribute("result", "登入成功!TOKEN為" + tokenUUID + ",30秒後過期.....30秒內可使用Token登入"); return "RegAndLog"; } model.addAttribute("result", "登入失敗!"); return "RegAndLog"; } model.addAttribute("result", "使用Token登入成功!"); return "RegAndLog"; }
各位友友執行本小結原始碼:訪問 http://localhost:8080/cookie/LogOrReg
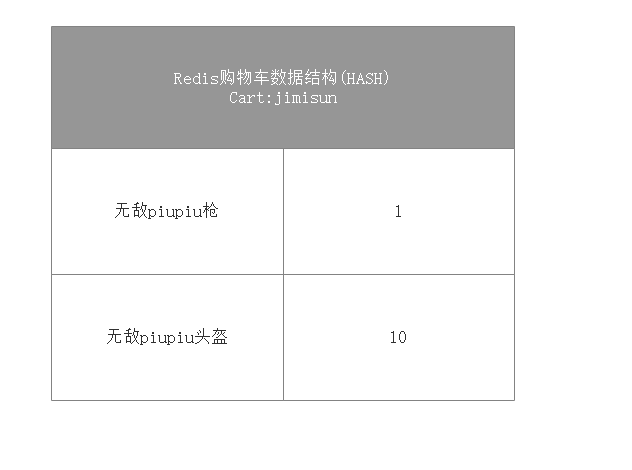
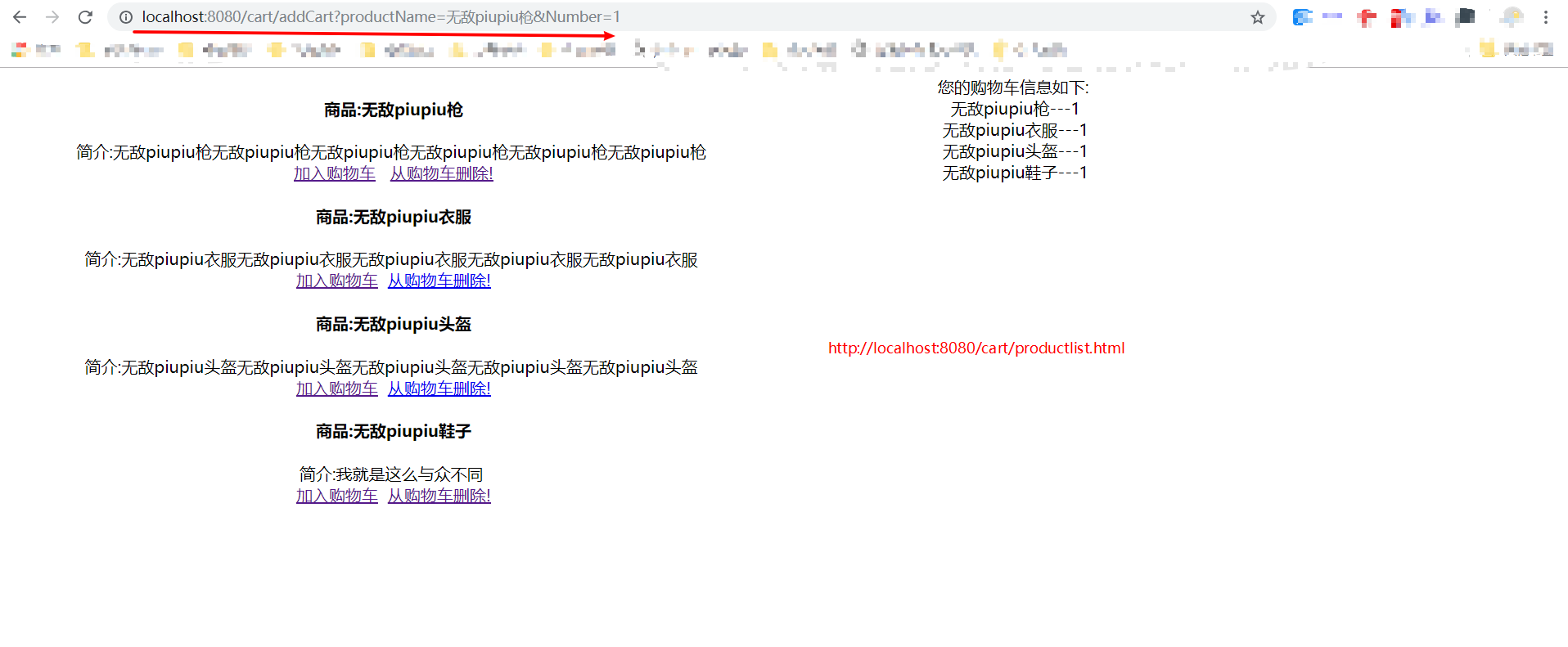
第二步:拒絕cookie,使用Redis構造購物車 github示例原始碼下載
對於一個購物網站來說,購物車就是一個必不可少的功能,從長遠來看對使用者購物車的資料的統計與分析有利於進行大資料的分析,提高網站的營業額。但在服務端每次解析,校驗,設定Cookie,會增加程式的響應時間。同樣;隨著Cookie體積的增大,也會增加使用者請求時間,所以我們在Redis上進行包存購物車。
Redis資料接結構
核心原始碼
@GetMapping("/addCart") public String addCart(Item item, Model model) { User user = getUser(); addTOCart(jedis, user, item); Map<String, String> cart = getCart(jedis, user); model.addAttribute("result", "新增購物車成功!"); model.addAttribute("cartList", cart); return "ProductList"; }
各位友友執行本小結原始碼:訪問 http://localhost:8080/cart/productlist.html
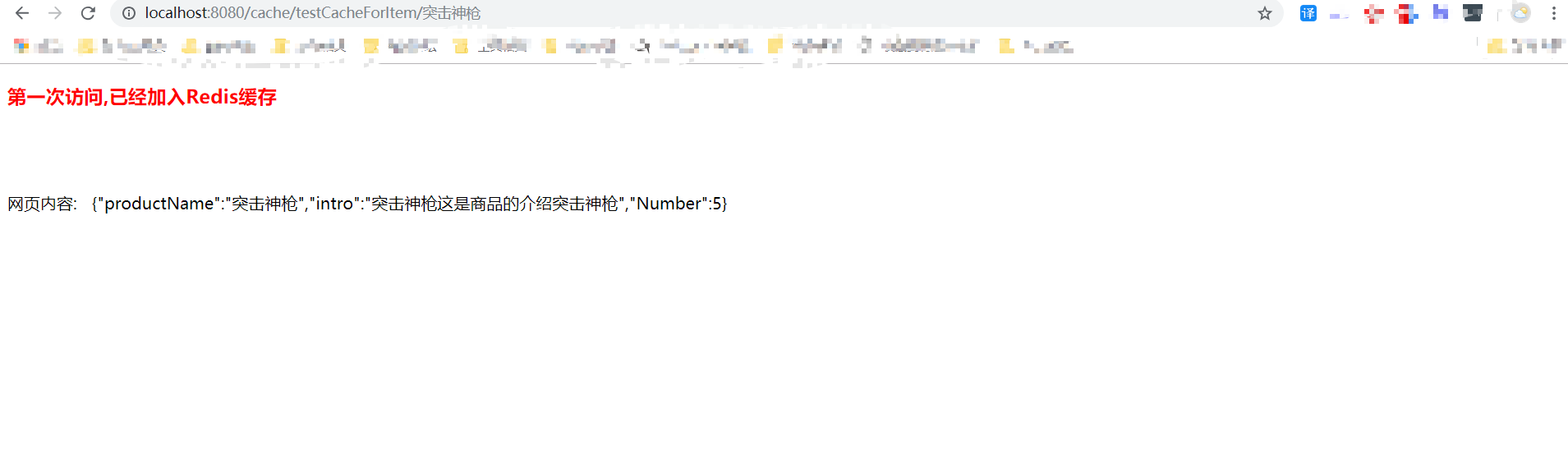
第三步:快取網頁資料,提高網頁響應 github示例原始碼下載
對於我們網站的大多數網頁,一般都很少改動,例如商品頁面,商品的標題和商品的介紹基本上不會改動,但是商品的剩餘數量你又不得不去資料庫實時查詢,這將會導致“使用者每開啟或重新整理一次網頁,你不得不去資料庫查詢一次資料”,對於一般的關係資料庫資料庫每秒處理200~2000上限,就成為了你網站的瓶頸所在。
Reids資料結構圖

核心原始碼
@RequestMapping("/testCacheForItem/{itemname}")
public String testCacheForItem(Model model, @PathVariable(required = true, name = "itemname") String itemname) {
/*模擬資料*/
Item item = new Item(itemname, itemname + "這是商品的介紹" + itemname, new Random().nextInt(10));
/*判斷是否被快取*/
Boolean hexists = jedis.exists("cache:" + itemname);
if (!hexists) {
Gson gson = new Gson();
String s = gson.toJson(item);
jedis.set("cache:" + itemname, s);
model.addAttribute("s", s);
model.addAttribute("result", "第一次訪問,已經加入Redis快取");
return "CacheItem";
}
String s = jedis.get("cache:" + itemname);
model.addAttribute("s", s);
model.addAttribute("result", "重複訪問,從Redis中讀取資料");
return "CacheItem";
}各位友友執行本小結原始碼:訪問 http://localhost:8080/cache/testCacheForItem/吃雞神槍

本章小結
對於真正實現一個能處理海量資料的購物網站來說,我們做的實在是太簡單了...是使用各種語言和工具的相互配置,程式邏輯的優化,才能構建出一個真正的能處理海量資料的網站。當然我們做的也不差....hhhh