
Flume+Kafka+Storm+Redis構建大數據實時處理系統:實時統計網站PV、UV+展示
1 大數據處理的常用方法
前面在我的另一篇文章中《大數據采集、清洗、處理:使用MapReduce進行離線數據分析完整案例》中已經有提及到,這裏依然給出下面的圖示:
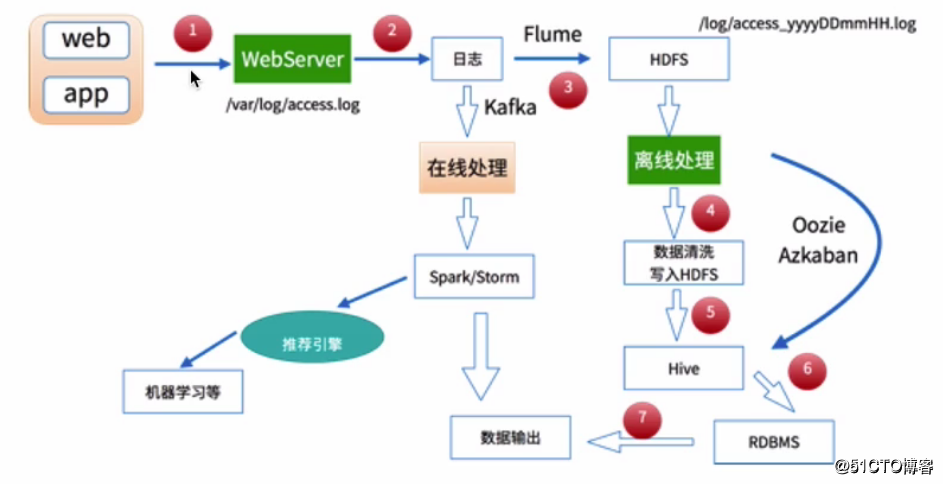
前面給出的那篇文章是基於MapReduce的離線數據分析案例,其通過對網站產生的用戶訪問日誌進行處理並分析出該網站在某天的PV、UV等數據,對應上面的圖示,其走的就是離線處理的數據處理方式,而這裏即將要介紹的是另外一條路線的數據處理方式,即基於Storm的在線處理,在下面給出的完整案例中,我們將會完成下面的幾項工作:
- 1.如何一步步構建我們的實時處理系統(Flume+Kafka+Storm+Redis)
- 2.實時處理網站的用戶訪問日誌,並統計出該網站的PV、UV
- 3.將實時分析出的PV、UV動態地展示在我們的前面頁面上
如果你對上面提及的大數據組件已經有所認識,或者對如何構建大數據實時處理系統感興趣,那麽就可以盡情閱讀下面的內容了。
需要註意的是,核心在於如何構建實時處理系統,而這裏給出的案例是實時統計某個網站的PV、UV,在實際中,基於每個人的工作環境不同,業務不同,因此業務系統的復雜度也不盡相同,相對來說,這裏統計PV、UV的業務是比較簡單的,但也足夠讓我們對大數據實時處理系統有一個基本的、清晰的了解與認識,是的,它不再那麽神秘了。
2 實時處理系統架構
我們的實時處理系統整體架構如下:
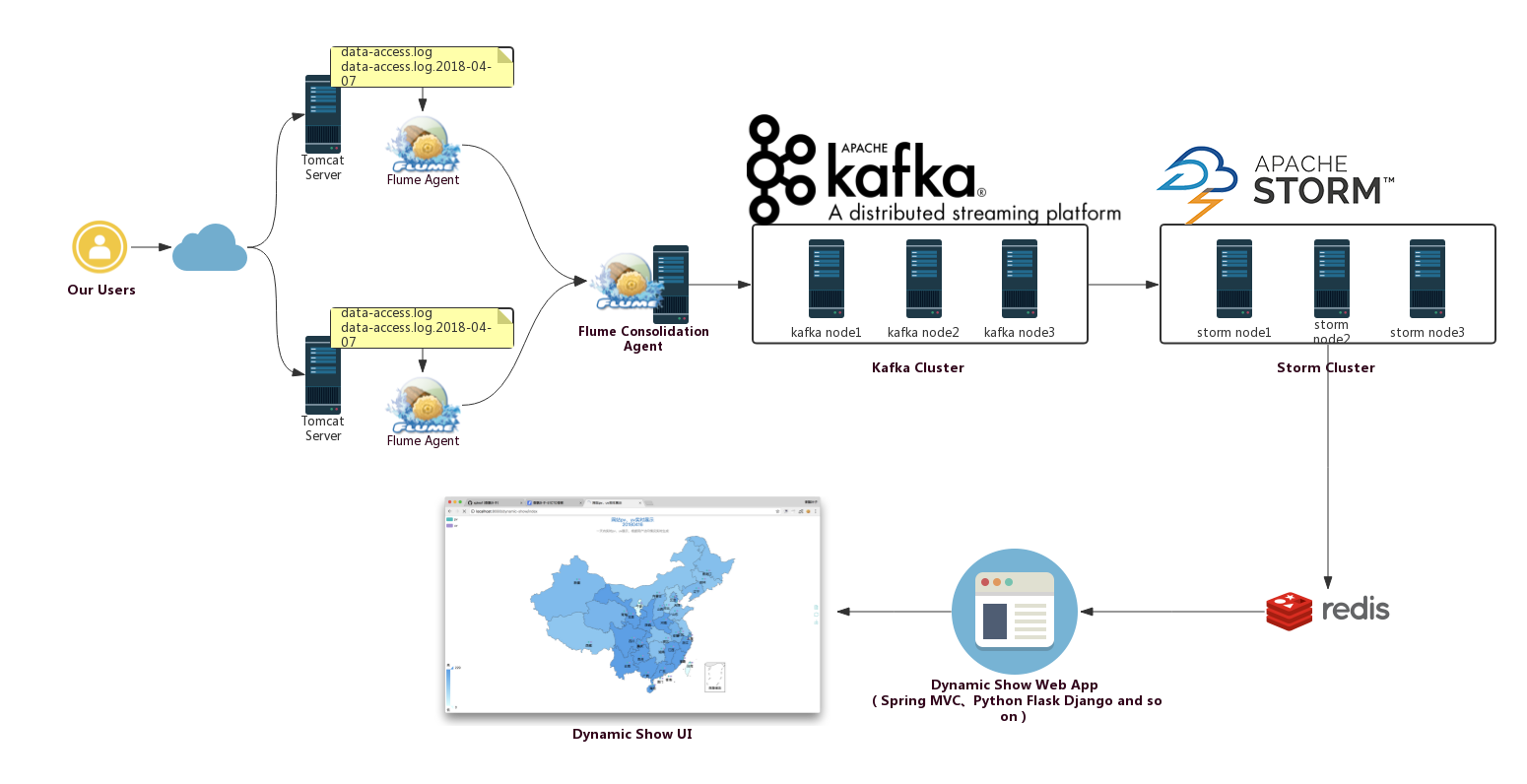
即從上面的架構中我們可以看出,其由下面的幾部分構成:
- Flume集群
- Kafka集群
- Storm集群
從構建實時處理系統的角度出發,我們需要做的是,如何讓數據在各個不同的集群系統之間打通(從上面的圖示中也能很好地說明這一點),即需要做各個系統之前的整合,包括Flume與Kafka的整合,Kafka與Storm的整合。當然,各個環境是否使用集群,依個人的實際需要而定,在我們的環境中,Flume、Kafka、Storm都使用集群。
3 Flume+Kafka整合
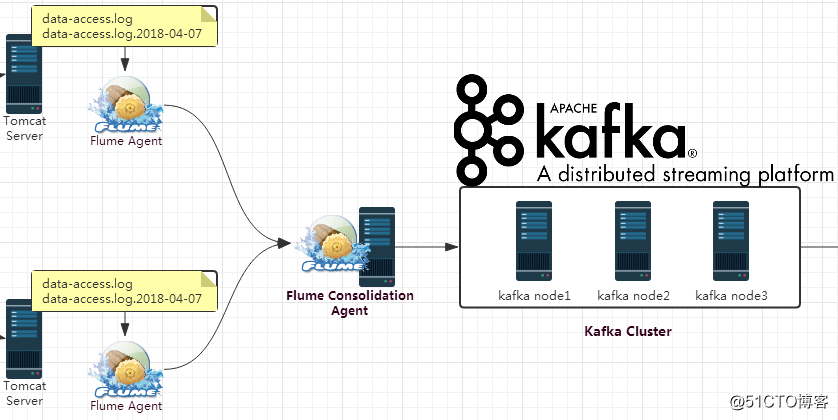
3.1 整合思路
對於Flume而言,關鍵在於如何采集數據,並且將其發送到Kafka上,並且由於我們這裏了使用Flume集群的方式,Flume集群的配置也是十分關鍵的。而對於Kafka,關鍵就是如何接收來自Flume的數據。從整體上講,邏輯應該是比較簡單的,即可以在Kafka中創建一個用於我們實時處理系統的topic,然後Flume將其采集到的數據發送到該topic上即可。
3.2 整合過程:Flume集群配置與Kafka Topic創建
3.2.1 Flume集群配置
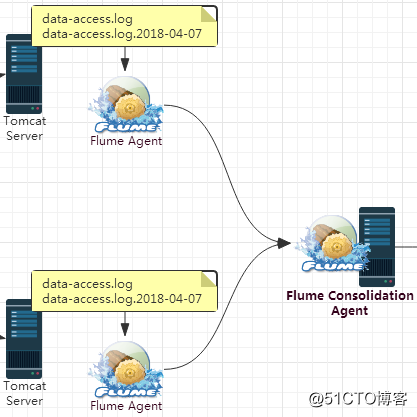
在我們的場景中,兩個Flume Agent分別部署在兩臺Web服務器上,用來采集Web服務器上的日誌數據,然後其數據的下沈方式都為發送到另外一個Flume Agent上,所以這裏我們需要配置三個Flume Agent.
3.2.1.1 Flume Agent01
該Flume Agent部署在一臺Web服務器上,用來采集產生的Web日誌,然後發送到Flume Consolidation Agent上,創建一個新的配置文件flume-sink-avro.conf,其配置內容如下:
#########################################################
##
##主要作用是監聽文件中的新增數據,采集到數據之後,輸出到avro
## 註意:Flume agent的運行,主要就是配置source channel sink
## 下面的a1就是agent的代號,source叫r1 channel叫c1 sink叫k1
#########################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#對於source的配置描述 監聽文件中的新增數據 exec
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/data-clean/data-access.log
#對於sink的配置描述 使用avro日誌做數據的消費
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = uplooking03
a1.sinks.k1.port = 44444
#對於channel的配置描述 使用文件做數據的臨時緩存 這種的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
#通過channel c1將source r1和sink k1關聯起來
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1配置完成後, 啟動Flume Agent,即可對日誌文件進行監聽:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-sink-avro.conf >/dev/null 2>&1 &3.2.1.2 Flume Agent02
該Flume Agent部署在一臺Web服務器上,用來采集產生的Web日誌,然後發送到Flume Consolidation Agent上,創建一個新的配置文件flume-sink-avro.conf,其配置內容如下:
#########################################################
##
##主要作用是監聽文件中的新增數據,采集到數據之後,輸出到avro
## 註意:Flume agent的運行,主要就是配置source channel sink
## 下面的a1就是agent的代號,source叫r1 channel叫c1 sink叫k1
#########################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#對於source的配置描述 監聽文件中的新增數據 exec
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/uplooking/data/data-clean/data-access.log
#對於sink的配置描述 使用avro日誌做數據的消費
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = uplooking03
a1.sinks.k1.port = 44444
#對於channel的配置描述 使用文件做數據的臨時緩存 這種的安全性要高
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/uplooking/data/flume/checkpoint
a1.channels.c1.dataDirs = /home/uplooking/data/flume/data
#通過channel c1將source r1和sink k1關聯起來
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1配置完成後, 啟動Flume Agent,即可對日誌文件進行監聽:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-sink-avro.conf >/dev/null 2>&1 &3.2.1.3 Flume Consolidation Agent
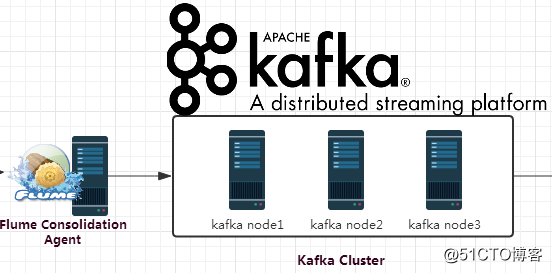
該Flume Agent用於接收其它兩個Agent發送過來的數據,然後將其發送到Kafka上,創建一個新的配置文件flume-source_avro-sink_kafka.conf,配置內容如下:
#########################################################
##
##主要作用是監聽目錄中的新增文件,采集到數據之後,輸出到kafka
## 註意:Flume agent的運行,主要就是配置source channel sink
## 下面的a1就是agent的代號,source叫r1 channel叫c1 sink叫k1
#########################################################
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#對於source的配置描述 監聽avro
a1.sources.r1.type = avro
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
#對於sink的配置描述 使用kafka做數據的消費
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = f-k-s
a1.sinks.k1.brokerList = uplooking01:9092,uplooking02:9092,uplooking03:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
#對於channel的配置描述 使用內存緩沖區域做數據的臨時緩存
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#通過channel c1將source r1和sink k1關聯起來
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 配置完成後, 啟動Flume Agent,即可對avro的數據進行監聽:
$ flume-ng agent --conf conf -n a1 -f app/flume/conf/flume-source_avro-sink_kafka.conf >/dev/null 2>&1 &3.2.2 Kafka配置
在我們的Kafka中,先創建一個topic,用於後面接收Flume采集過來的數據:
kafka-topics.sh --create --topic f-k-s --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181 --partitions 3 --replication-factor 33.3 整合驗證
啟動Kafka的消費腳本:
$ kafka-console-consumer.sh --topic f-k-s --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181如果在Web服務器上有新增的日誌數據,就會被我們的Flume程序監聽到,並且最終會傳輸到到Kafka的f-k-stopic中,這裏作為驗證,我們上面啟動的是一個kafka終端消費的腳本,這時會在終端中看到數據的輸出:
$ kafka-console-consumer.sh --topic f-k-s --zookeeper uplooking01:2181,uplooking02:2181,uplooking03:2181
1003 221.8.9.6 80 0f57c8f5-13e2-428d-ab39-9e87f6e85417 10709 0 GET /index HTTP/1.1 null null Mozilla/5.0 (Windows; U; Windows NT 5.2)Gecko/2008070208 Firefox/3.0.1 1523107496164
1002 220.194.55.244 fb953d87-d166-4cb4-8a64-de7ddde9054c 10201 0 GET /check/detail HTTP/1.1 null null Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko 1523107497165
1003 211.167.248.22 9d7bb7c2-00bf-4102-9c8c-3d49b18d1b48 10022 1 GET /user/add HTTP/1.1 null null Mozilla/4.0 (compatible; MSIE 8.0; Windows NT6.0) 1523107496664
1002 61.172.249.96 null 10608 0 POST /updateById?id=21 HTTP/1.1 null null Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko 1523107498166
1000 202.98.11.101 aa7f62b3-a6a1-44ef-81f5-5e71b5c61368 20202 0 GET /getDataById HTTP/1.0 404 /check/init Mozilla/5.0 (Windows; U; Windows NT 5.1)Gecko/20070803 Firefox/1.5.0.12 1523107497666這樣的話,我們的整合就沒有問題,當然kafka中的數據應該是由我們的storm來進行消費的,這裏只是作為整合的一個測試,下面就會來做kafka+storm的整合。
4 Kafka+Storm整合
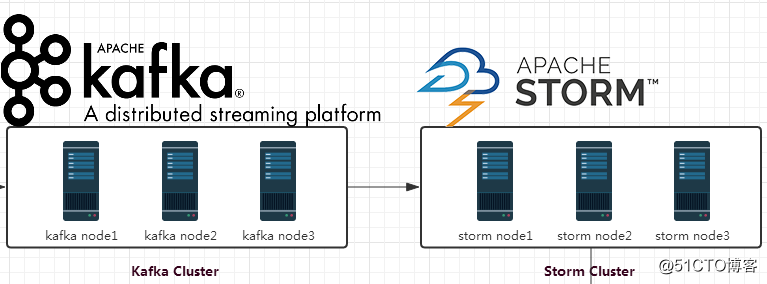
Kafka和Storm的整合其實在Storm的官網上也有非常詳細清晰的文檔:http://storm.apache.org/releases/1.0.6/storm-kafka.html,想對其有更多了解的同學可以參考一下。
4.1 整合思路
在這次的大數據實時處理系統的構建中,Kafka相當於是作為消息隊列(或者說是消息中間件)的角色,其產生的消息需要有消費者去消費,所以Kafka與Storm的整合,關鍵在於我們的Storm如何去消費Kafka消息topic中的消息(kafka消息topic中的消息正是由Flume采集而來,現在我們需要在Storm中對其進行消費)。
在Storm中,topology是非常關鍵的概念。
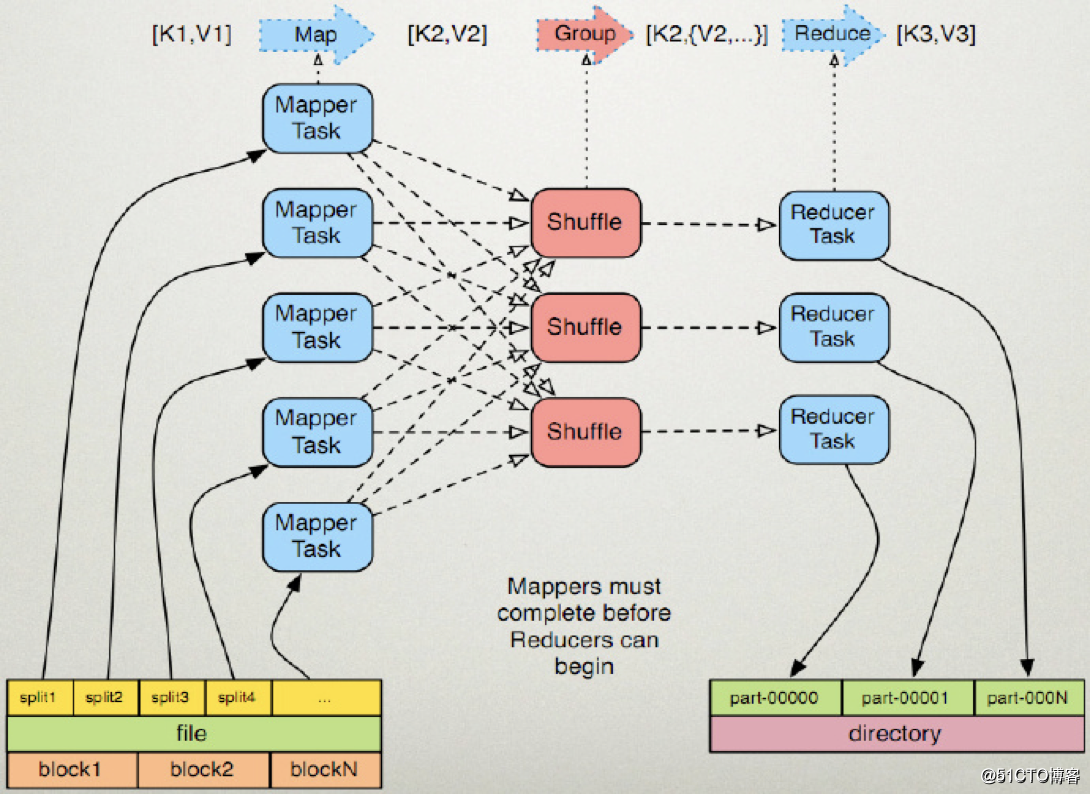
對比MapReduce,在MapReduce中,我們提交的作業稱為一個job,在一個Job中,又包含若幹個Mapper和Reducer,正是在Mapper和Reducer中有我們對數據的處理邏輯:
在Storm中,我們提交的一個作業稱為topology,其又包含了spout和bolt,在Storm中,對數據的處理邏輯正是在spout和bolt中體現:
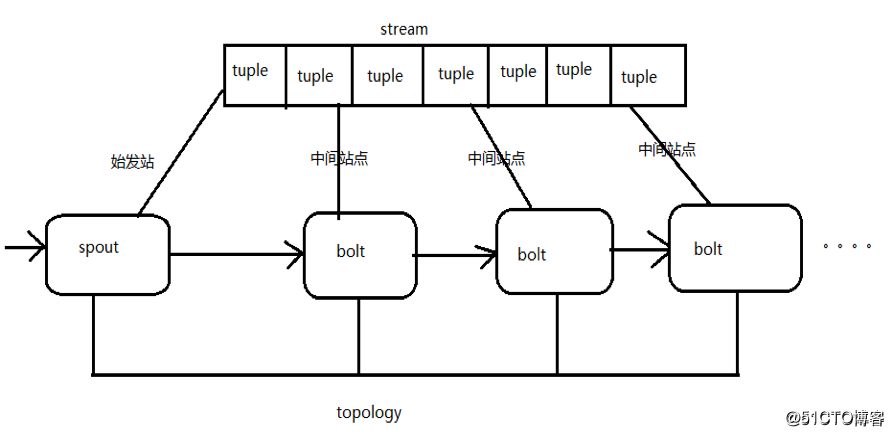
即在spout中,正是我們數據的來源,又因為其實時的特性,所以可以把它比作一個“水龍頭”,表示其源源不斷地產生數據:
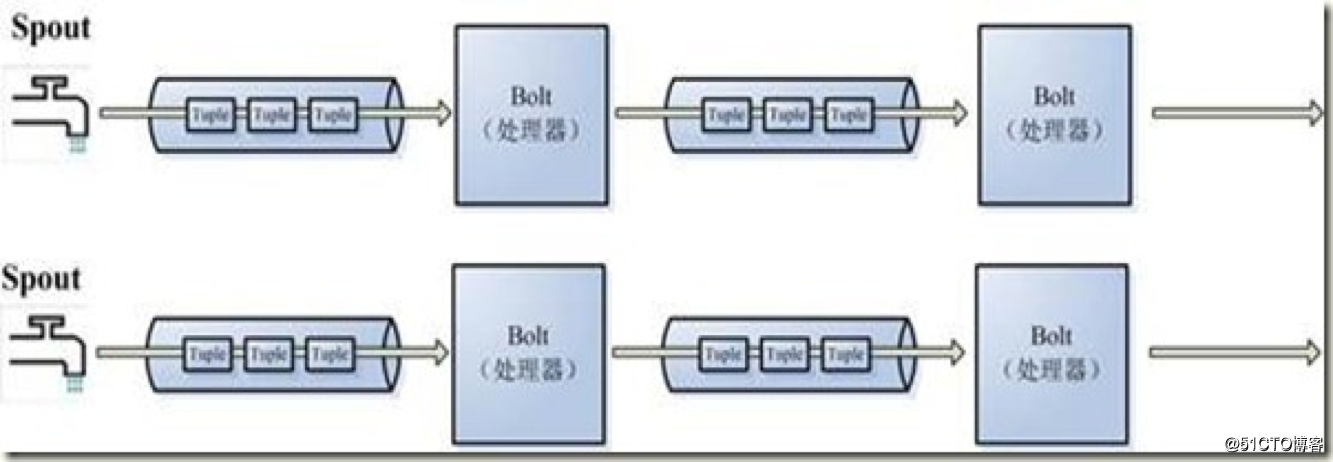
所以,問題的關鍵是spout如何去獲取來自kafka的數據?
好在,storm-kafka的整合庫中提供了這樣的API來供我們進行操作。
4.2 整合過程:KafkaSpout的應用
在代碼的邏輯中只需要創建一個由storm-kafkaAPI提供的KafkaSpout對象即可:
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);
return new KafkaSpout(spoutConf);下面給出完整的整合代碼:
package cn.xpleaf.bigdata.storm.statics;
import kafka.api.OffsetRequest;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.BrokerHosts;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
/**
* Kafka和storm的整合,用於統計實時流量對應的pv和uv
*/
public class KafkaStormTopology {
// static class MyKafkaBolt extends BaseRichBolt {
static class MyKafkaBolt extends BaseBasicBolt {
/**
* kafkaSpout發送的字段名為bytes
*/
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
byte[] binary = input.getBinary(0); // 跨jvm傳輸數據,接收到的是字節數據
// byte[] bytes = input.getBinaryByField("bytes"); // 這種方式也行
String line = new String(binary);
System.out.println(line);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 設置spout和bolt的dag(有向無環圖)
*/
KafkaSpout kafkaSpout = createKafkaSpout();
builder.setSpout("id_kafka_spout", kafkaSpout);
builder.setBolt("id_kafka_bolt", new MyKafkaBolt())
.shuffleGrouping("id_kafka_spout"); // 通過不同的數據流轉方式,來指定數據的上遊組件
// 使用builder構建topology
StormTopology topology = builder.createTopology();
String topologyName = KafkaStormTopology.class.getSimpleName(); // 拓撲的名稱
Config config = new Config(); // Config()對象繼承自HashMap,但本身封裝了一些基本的配置
// 啟動topology,本地啟動使用LocalCluster,集群啟動使用StormSubmitter
if (args == null || args.length < 1) { // 沒有參數時使用本地模式,有參數時使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地開發模式,創建的對象為LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
/**
* BrokerHosts hosts kafka集群列表
* String topic 要消費的topic主題
* String zkRoot kafka在zk中的目錄(會在該節點目錄下記錄讀取kafka消息的偏移量)
* String id 當前操作的標識id
*/
private static KafkaSpout createKafkaSpout() {
String brokerZkStr = "uplooking01:2181,uplooking02:2181,uplooking03:2181";
BrokerHosts hosts = new ZkHosts(brokerZkStr); // 通過zookeeper中的/brokers即可找到kafka的地址
String topic = "f-k-s";
String zkRoot = "/" + topic;
String id = "consumer-id";
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);
// 本地環境設置之後,也可以在zk中建立/f-k-s節點,在集群環境中,不用配置也可以在zk中建立/f-k-s節點
//spoutConf.zkServers = Arrays.asList(new String[]{"uplooking01", "uplooking02", "uplooking03"});
//spoutConf.zkPort = 2181;
spoutConf.startOffsetTime = OffsetRequest.LatestTime(); // 設置之後,剛啟動時就不會把之前的消費也進行讀取,會從最新的偏移量開始讀取
return new KafkaSpout(spoutConf);
}
}其實代碼的邏輯非常簡單,我們只創建了 一個由storm-kafka提供的KafkaSpout對象和一個包含我們處理邏輯的MyKafkaBolt對象,MyKafkaBolt的邏輯也很簡單,就是把kafka的消息打印到控制臺上。
需要註意的是,後面我們分析網站PV、UV的工作,正是在上面這部分簡單的代碼中完成的,所以其是非常重要的基礎。
4.3 整合驗證
上面的整合代碼,可以在本地環境中運行,也可以將其打包成jar包上傳到我們的Storm集群中並提交業務來運行。如果Web服務器能夠產生日誌,並且前面Flume+Kafka的整合也沒有問題的話,將會有下面的效果。
如果是在本地環境中運行上面的代碼,那麽可以在控制臺中看到日誌數據的輸出:
......
45016548 [Thread-16-id_kafka_spout-executor[3 3]] INFO o.a.s.k.ZkCoordinator - Task [1/1] Refreshing partition manager connections
45016552 [Thread-16-id_kafka_spout-executor[3 3]] INFO o.a.s.k.DynamicBrokersReader - Read partition info from zookeeper: GlobalPartitionInformation{topic=f-k-s, partitionMap={0=uplooking02:9092, 1=uplooking03:9092, 2=uplooking01:9092}}
45016552 [Thread-16-id_kafka_spout-executor[3 3]] INFO o.a.s.k.KafkaUtils - Task [1/1] assigned [Partition{host=uplooking02:9092, topic=f-k-s, partition=0}, Partition{host=uplooking03:9092, topic=f-k-s, partition=1}, Partition{host=uplooking01:9092, topic=f-k-s, partition=2}]
45016552 [Thread-16-id_kafka_spout-executor[3 3]] INFO o.a.s.k.ZkCoordinator - Task [1/1] Deleted partition managers: []
45016552 [Thread-16-id_kafka_spout-executor[3 3]] INFO o.a.s.k.ZkCoordinator - Task [1/1] New partition managers: []
45016552 [Thread-16-id_kafka_spout-executor[3 3]] INFO o.a.s.k.ZkCoordinator - Task [1/1] Finished refreshing
1003 221.8.9.6 80 0f57c8f5-13e2-428d-ab39-9e87f6e85417 10709 0 GET /index HTTP/1.1 null null Mozilla/5.0 (Windows; U; Windows NT 5.2)Gecko/2008070208 Firefox/3.0.1 1523107496164
1000 202.98.11.101 aa7f62b3-a6a1-44ef-81f5-5e71b5c61368 20202 0 GET /getDataById HTTP/1.0 404 /check/init Mozilla/5.0 (Windows; U; Windows NT 5.1)Gecko/20070803 Firefox/1.5.0.12 1523107497666
1002 220.194.55.244 fb953d87-d166-4cb4-8a64-de7ddde9054c 10201 0 GET /check/detail HTTP/1.1 null null Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko 1523107497165
1003 211.167.248.22 9d7bb7c2-00bf-4102-9c8c-3d49b18d1b48 10022 1 GET /user/add HTTP/1.1 null null Mozilla/4.0 (compatible; MSIE 8.0; Windows NT6.0) 1523107496664
1002 61.172.249.96 null 10608 0 POST /updateById?id=21 HTTP/1.1 null null Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko 1523107498166
......如果是在Storm集群中提交的作業運行,那麽也可以在Storm的日誌中看到Web服務器產生的日誌數據:
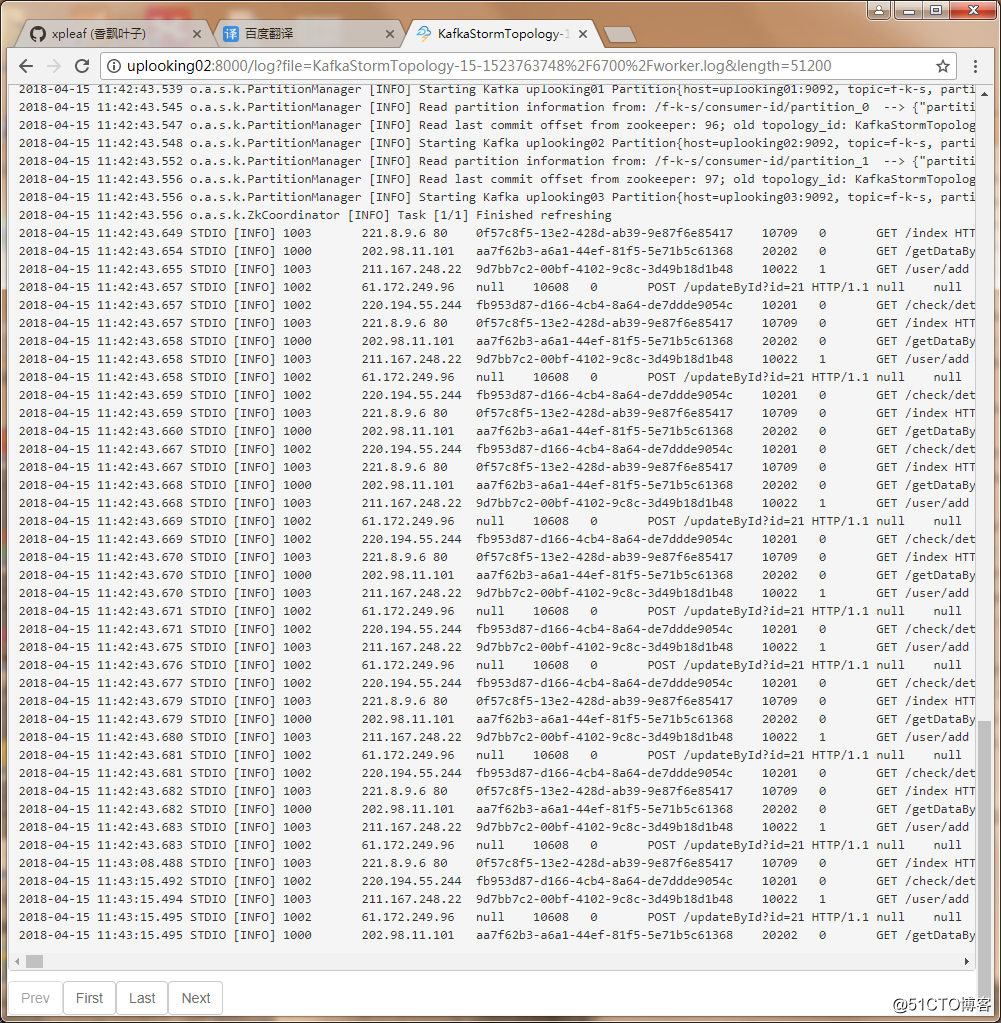
這樣的話就完成了Kafka+Storm的整合。
5 Storm+Redis整合
5.1 整合思路
其實所謂Storm和Redis的整合,指的是在我們的實時處理系統中的數據的落地方式,即在Storm中包含了我們處理數據的邏輯,而數據處理完畢後,產生的數據處理結果該保存到什麽地方呢?顯然就有很多種方式了,關系型數據庫、NoSQL、HDFS、HBase等,這應該取決於具體的業務和數據量,在這裏,我們使用Redis來進行最後分析數據的存儲。
所以實際上做這一步的整合,其實就是開始寫我們的業務處理代碼了,因為通過前面Flume-Kafka-Storm的整合,已經打通了整個數據的流通路徑,接下來關鍵要做的是,在Storm中,如何處理我們的數據並保存到Redis中。
而在Storm中,spout已經不需要我們來寫了(由storm-kafka的API提供了KafkaSpout對象),所以問題就變成,如何根據業務編寫分析處理數據的bolt。
5.2 整合過程:編寫Storm業務處理Bolt
5.2.1 日誌分析
我們實時獲取的日誌格式如下:
1002 202.103.24.68 1976dc2e-f03a-44f0-892f-086d85105f7e 14549 1 GET /top HTTP/1.1 200 /tologin Mozilla/5.0 (Windows; U; Windows NT 5.2)AppleWebKit/525.13 (KHTML, like Gecko) Version/3.1Safari/525.13 1523806916373
1000 221.8.9.6 80 542ccf0a-9b14-49a0-93cd-891d87ddabf3 12472 1 GET /index HTTP/1.1 500 /top Mozilla/4.0 (compatible; MSIE 5.0; WindowsNT) 1523806916874
1003 211.167.248.22 0e4c1875-116c-400e-a4f8-47a46ad04a42 12536 0 GET /tologin HTTP/1.1 200 /stat Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML,like Gecko) Chrome/0.2.149.27 Safari/525.13 1523806917375
1000 219.147.198.230 07eebc1a-740b-4dac-b53f-bb242a45c901 11847 1 GET /userList HTTP/1.1 200 /top Mozilla/4.0 (compatible; MSIE 6.0; Windows NT5.1) 1523806917876
1001 222.172.200.68 4fb35ced-5b30-483b-9874-1d5917286675 13550 1 GET /getDataById HTTP/1.0 504 /tologin Mozilla/5.0 (Windows; U; Windows NT 5.2)AppleWebKit/525.13 (KHTML, like Gecko) Version/3.1Safari/525.13 1523806918377其中需要說明的是第二個字段和第三個字段,因為它對我們統計pv和uv非常有幫助,它們分別是ip字段和mid字段,說明如下:
ip:用戶的IP地址
mid:唯一的id,此id第一次會種在瀏覽器的cookie裏。如果存在則不再種。作為瀏覽器唯一標示。移動端或者pad直接取機器碼。因此,根據IP地址,我們可以通過查詢得到其所在的省份,並且創建一個屬於該省份的變量,用於記錄pv數,每來一條屬於該省份的日誌記錄,則該省份的pv就加1,以此來完成pv的統計。
而對於mid,我們則可以創建屬於該省的一個set集合,每來一條屬於該省份的日誌記錄,則可以將該mid添加到set集合中,因為set集合存放的是不重復的數據,這樣就可以幫我們自動過濾掉重復的mid,根據set集合的大小,就可以統計出uv。
在我們storm的業務處理代碼中,我們需要編寫兩個bolt:
- 第一個bolt用來對數據進行預處理,也就是提取我們需要的ip和mid,並且根據IP查詢得到省份信息;
- 第二個bolt用來統計pv、uv,並定時將pv、uv數據寫入到Redis中;
當然上面只是說明了整體的思路,實際上還有很多需要註意的細節問題和技巧問題,這都在我們的代碼中進行體現,我在後面寫的代碼中都加了非常詳細的註釋進行說明。
5.2.2 編寫第一個Bolt:ConvertIPBolt
根據上面的分析,編寫用於數據預處理的bolt,代碼如下:
package cn.xpleaf.bigdata.storm.statistic;
import cn.xpleaf.bigdata.storm.utils.JedisUtil;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import redis.clients.jedis.Jedis;
/**
* 日誌數據預處理Bolt,實現功能:
* 1.提取實現業務需求所需要的信息:ip地址、客戶端唯一標識mid
* 2.查詢IP地址所屬地,並發送到下一個Bolt
*/
public class ConvertIPBolt extends BaseBasicBolt {
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
byte[] binary = input.getBinary(0);
String line = new String(binary);
String[] fields = line.split("\t");
if(fields == null || fields.length < 10) {
return;
}
// 獲取ip和mid
String ip = fields[1];
String mid = fields[2];
// 根據ip獲取其所屬地(省份)
String province = null;
if (ip != null) {
Jedis jedis = JedisUtil.getJedis();
province = jedis.hget("ip_info_en", ip);
// 需要釋放jedis的資源,否則會報can not get resource from the pool
JedisUtil.returnJedis(jedis);
}
// 發送數據到下一個bolt,只發送實現業務功能需要的province和mid
collector.emit(new Values(province, mid));
}
/**
* 定義了發送到下一個bolt的數據包含兩個域:province和mid
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("province", "mid"));
}
}5.2.3 編寫第二個Bolt:StatisticBolt
這個bolt包含我們統計網站pv、uv的代碼邏輯,因此非常重要,其代碼如下:
package cn.xpleaf.bigdata.storm.statistic;
import cn.xpleaf.bigdata.storm.utils.JedisUtil;
import org.apache.storm.Config;
import org.apache.storm.Constants;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
import redis.clients.jedis.Jedis;
import java.text.SimpleDateFormat;
import java.util.*;
/**
* 日誌數據統計Bolt,實現功能:
* 1.統計各省份的PV、UV
* 2.以天為單位,將省份對應的PV、UV信息寫入Redis
*/
public class StatisticBolt extends BaseBasicBolt {
Map<String, Integer> pvMap = new HashMap<>();
Map<String, HashSet<String>> midsMap = null;
SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMdd");
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
if (!input.getSourceComponent().equalsIgnoreCase(Constants.SYSTEM_COMPONENT_ID)) { // 如果收到非系統級別的tuple,統計信息到局部變量mids
String province = input.getStringByField("province");
String mid = input.getStringByField("mid");
pvMap.put(province, pvMap.get(province) + 1); // pv+1
if(mid != null) {
midsMap.get(province).add(mid); // 將mid添加到該省份所對應的set中
}
} else { // 如果收到系統級別的tuple,則將數據更新到Redis中,釋放JVM堆內存空間
/*
* 以 廣東 為例,其在Redis中保存的數據格式如下:
* guangdong_pv(Redis數據結構為hash)
* --20180415
* --pv數
* --20180416
* --pv數
* guangdong_mids_20180415(Redis數據結構為set)
* --mid
* --mid
* --mid
* ......
* guangdong_mids_20180415(Redis數據結構為set)
* --mid
* --mid
* --mid
* ......
*/
Jedis jedis = JedisUtil.getJedis();
String dateStr = sdf.format(new Date());
// 更新pvMap數據到Redis中
String pvKey = null;
for(String province : pvMap.keySet()) {
int currentPv = pvMap.get(province);
if(currentPv > 0) { // 當前map中的pv大於0才更新,否則沒有意義
pvKey = province + "_pv";
String oldPvStr = jedis.hget(pvKey, dateStr);
if(oldPvStr == null) {
oldPvStr = "0";
}
Long oldPv = Long.valueOf(oldPvStr);
jedis.hset(pvKey, dateStr, oldPv + currentPv + "");
pvMap.replace(province, 0); // 將該省的pv重新設置為0
}
}
// 更新midsMap到Redis中
String midsKey = null;
HashSet<String> midsSet = null;
for(String province: midsMap.keySet()) {
midsSet = midsMap.get(province);
if(midsSet.size() > 0) { // 當前省份的set的大小大於0才更新到,否則沒有意義
midsKey = province + "_mids_" + dateStr;
jedis.sadd(midsKey, midsSet.toArray(new String[midsSet.size()]));
midsSet.clear();
}
}
// 釋放jedis資源
JedisUtil.returnJedis(jedis);
System.out.println(System.currentTimeMillis() + "------->寫入數據到Redis");
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
/**
* 設置定時任務,只對當前bolt有效,系統會定時向StatisticBolt發送一個系統級別的tuple
*/
@Override
public Map<String, Object> getComponentConfiguration() {
Map<String, Object> config = new HashMap<>();
config.put(Config.TOPOLOGY_TICK_TUPLE_FREQ_SECS, 10);
return config;
}
/**
* 初始化各個省份的pv和mids信息(用來臨時存儲統計pv和uv需要的數據)
*/
public StatisticBolt() {
pvMap = new HashMap<>();
midsMap = new HashMap<String, HashSet<String>>();
String[] provinceArray = {"shanxi", "jilin", "hunan", "hainan", "xinjiang", "hubei", "zhejiang", "tianjin", "shanghai",
"anhui", "guizhou", "fujian", "jiangsu", "heilongjiang", "aomen", "beijing", "shaanxi", "chongqing",
"jiangxi", "guangxi", "gansu", "guangdong", "yunnan", "sicuan", "qinghai", "xianggang", "taiwan",
"neimenggu", "henan", "shandong", "shanghai", "hebei", "liaoning", "xizang"};
for(String province : provinceArray) {
pvMap.put(province, 0);
midsMap.put(province, new HashSet());
}
}
}5.2.4 編寫Topology
我們需要編寫一個topology用來組織前面編寫的Bolt,代碼如下:
package cn.xpleaf.bigdata.storm.statistic;
import kafka.api.OffsetRequest;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.BrokerHosts;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.TopologyBuilder;
/**
* 構建topology
*/
public class StatisticTopology {
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 設置spout和bolt的dag(有向無環圖)
*/
KafkaSpout kafkaSpout = createKafkaSpout();
builder.setSpout("id_kafka_spout", kafkaSpout);
builder.setBolt("id_convertIp_bolt", new ConvertIPBolt()).shuffleGrouping("id_kafka_spout"); // 通過不同的數據流轉方式,來指定數據的上遊組件
builder.setBolt("id_statistic_bolt", new StatisticBolt()).shuffleGrouping("id_convertIp_bolt"); // 通過不同的數據流轉方式,來指定數據的上遊組件
// 使用builder構建topology
StormTopology topology = builder.createTopology();
String topologyName = KafkaStormTopology.class.getSimpleName(); // 拓撲的名稱
Config config = new Config(); // Config()對象繼承自HashMap,但本身封裝了一些基本的配置
// 啟動topology,本地啟動使用LocalCluster,集群啟動使用StormSubmitter
if (args == null || args.length < 1) { // 沒有參數時使用本地模式,有參數時使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地開發模式,創建的對象為LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
/**
* BrokerHosts hosts kafka集群列表
* String topic 要消費的topic主題
* String zkRoot kafka在zk中的目錄(會在該節點目錄下記錄讀取kafka消息的偏移量)
* String id 當前操作的標識id
*/
private static KafkaSpout createKafkaSpout() {
String brokerZkStr = "uplooking01:2181,uplooking02:2181,uplooking03:2181";
BrokerHosts hosts = new ZkHosts(brokerZkStr); // 通過zookeeper中的/brokers即可找到kafka的地址
String topic = "f-k-s";
String zkRoot = "/" + topic;
String id = "consumer-id";
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);
// 本地環境設置之後,也可以在zk中建立/f-k-s節點,在集群環境中,不用配置也可以在zk中建立/f-k-s節點
//spoutConf.zkServers = Arrays.asList(new String[]{"uplooking01", "uplooking02", "uplooking03"});
//spoutConf.zkPort = 2181;
spoutConf.startOffsetTime = OffsetRequest.LatestTime(); // 設置之後,剛啟動時就不會把之前的消費也進行讀取,會從最新的偏移量開始讀取
return new KafkaSpout(spoutConf);
}
}5.3 整合驗證
將上面的程序打包成jar包,並上傳到我們的集群提交業務後,如果前面的整合沒有問題,並且Web服務也有Web日誌產生,那麽一段時間後,我們就可以在Redis數據庫中看到數據的最終處理結果,即各個省份的uv和pv信息:
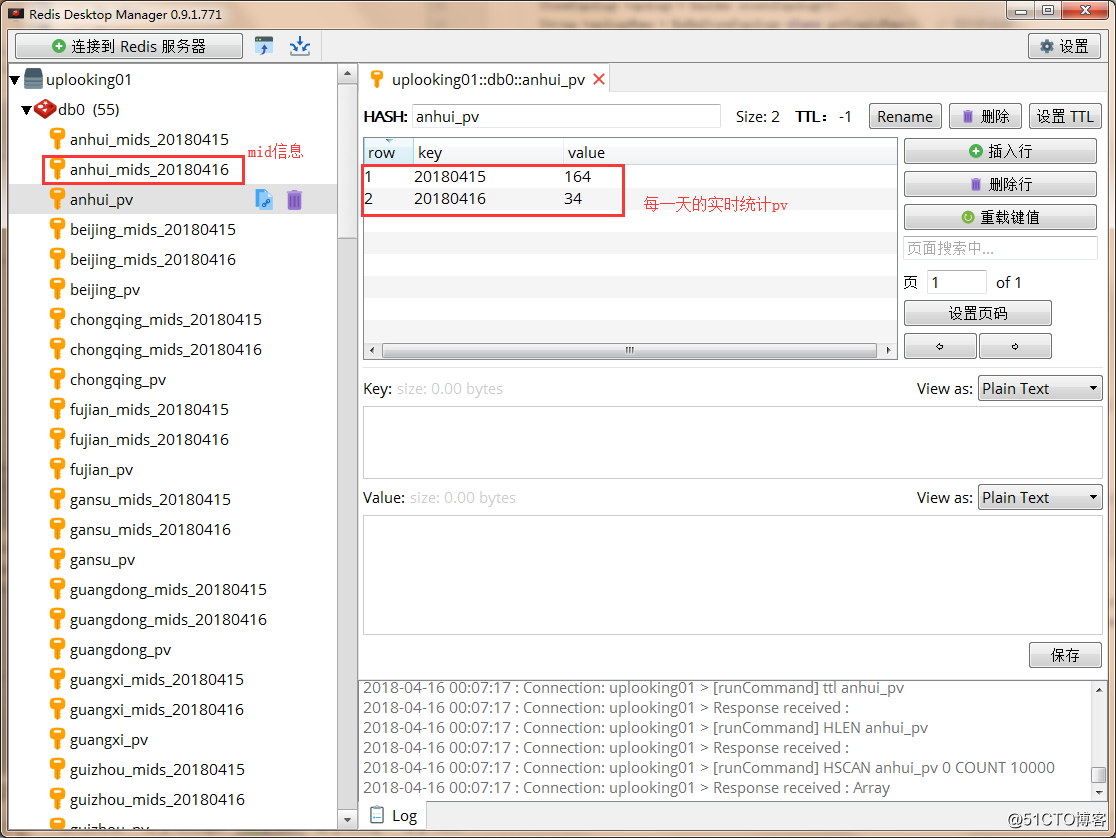
需要說明的是mid信息是一個set集合,只要求出該set集合的大小,也就可以求出uv值。
至此,準確來說,我們的統計pv、uv的大數據實時處理系統是構建完成了,處理的數據結果的用途根據不同的業務需求而不同,但是對於網站的pv、uv數據來說,是非常適合用作可視化處理的,即用網頁動態將數據展示出來,我們下一步正是要構建一個簡單的Web應用將pv、uv數據動態展示出來。
6 數據可視化處理
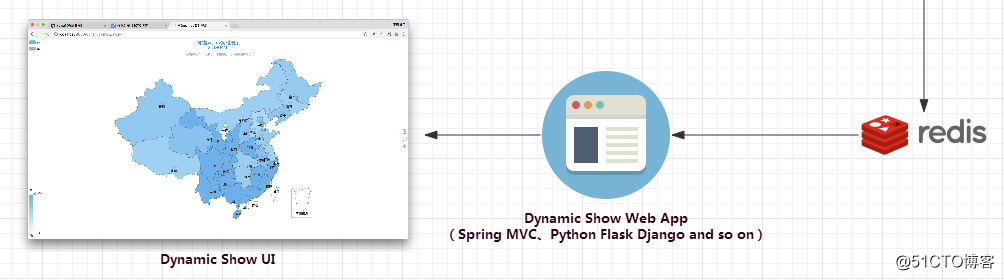
數據可視化處理目前我們需要完成兩部分的工作:
- 1.開發一個Web項目,能夠查詢Redis中的數據,同時提供訪問的頁面
- 2.自行開發或找一個符合我們需求的前端UI,將Web項目中查詢到的數據展示出來
對於Web項目的開發,因個人的技術棧能力而異,選擇的語言和技術也有所不同,只要能夠達到我們最終數據可視化的目的,其實都行的。這個項目中我們要展示的是pv和uv數據,難度不大,因此可以選擇Java Web,如Servlet、SpringMVC等,或者Python Web,如Flask、Django等,Flask我個人非常喜歡,因為開發非常快,但因為前面一直用的是Java,因此這裏我還是選擇使用SpringMVC來完成。
至於UI這一塊,我前端能力一般,普通的開發沒有問題,但是要做出像上面這種地圖類型的UI界面來展示數據的話,確實有點無能為力。好在現在第三方的UI框架比較多,對於圖表類展示的,比如就有highcharts和echarts,其中echarts是百度開源的,有豐富的中文文檔,非常容易上手,所以這裏我選擇使用echarts來作為UI,並且其剛好就有能夠滿足我們需求的地圖類的UI組件。
因為難度不大,具體的開發流程的這裏就不提及了,有興趣的同學可以直接參考後面我提供的源代碼,這裏我們就直接來看一下效果好了。
因為實際上在本次項目案例中,這一塊的代碼也是非常少的,使用SpringMVC開發的話,只要把JavaEE三層構架搭起來了,把依賴引入好了,後面的開發確實不難的;而如果有同學會Flask或者Django的話,其項目本身的構建和代碼上也都會更容易。
啟動我們的Web項目後,輸入地址就可以訪問到數據的展示界面了:
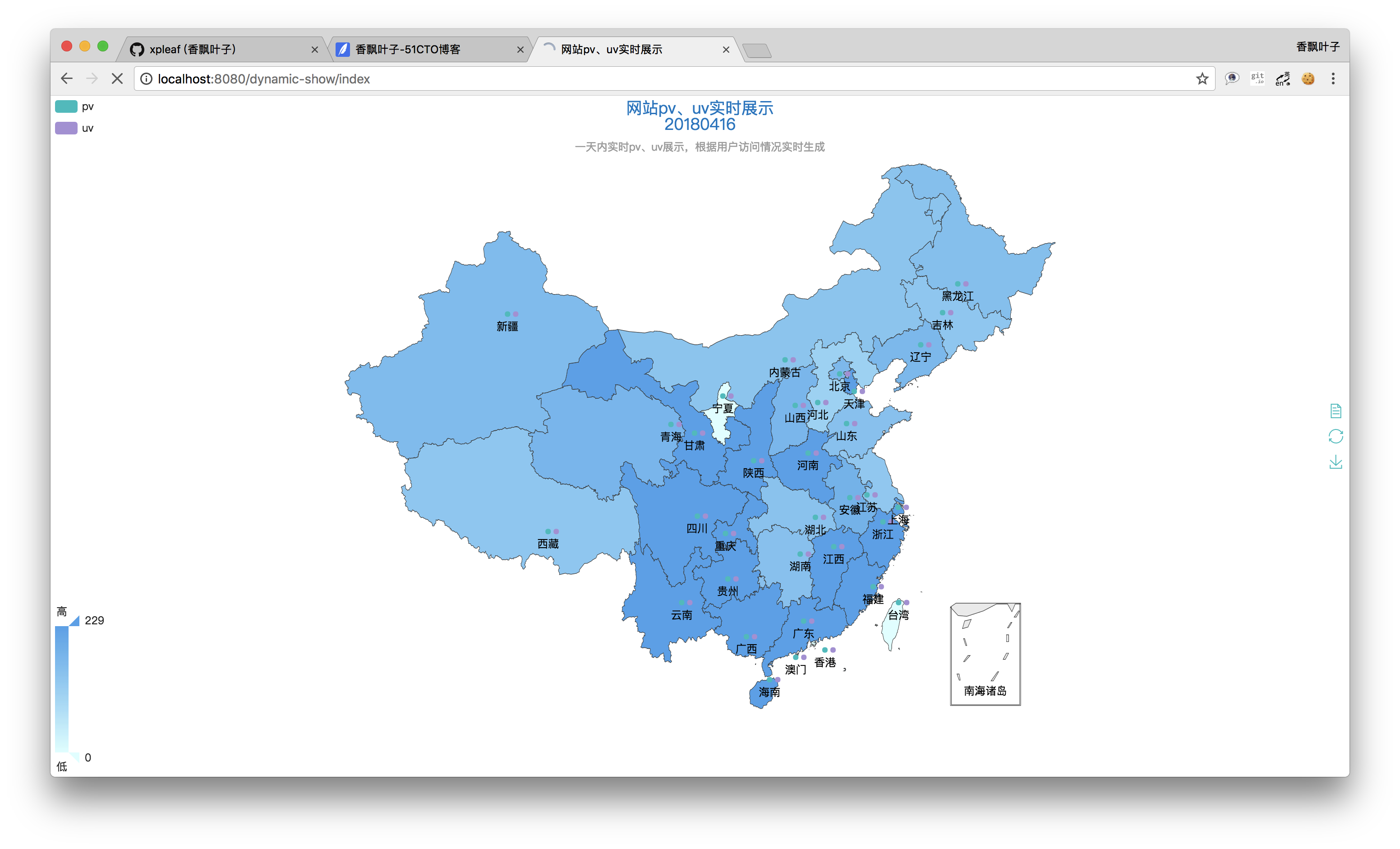
可以看到,echarts的這個UI還是比較好看的,而且也真的能夠滿足我們的需求。每個省份上的兩個不同顏色的點表示目前我們需要展示的數據有兩種,分別為pv和uv,在左上角也有體現,而顏色的深淺就可以體現pv或者uv的數量大小關系了。
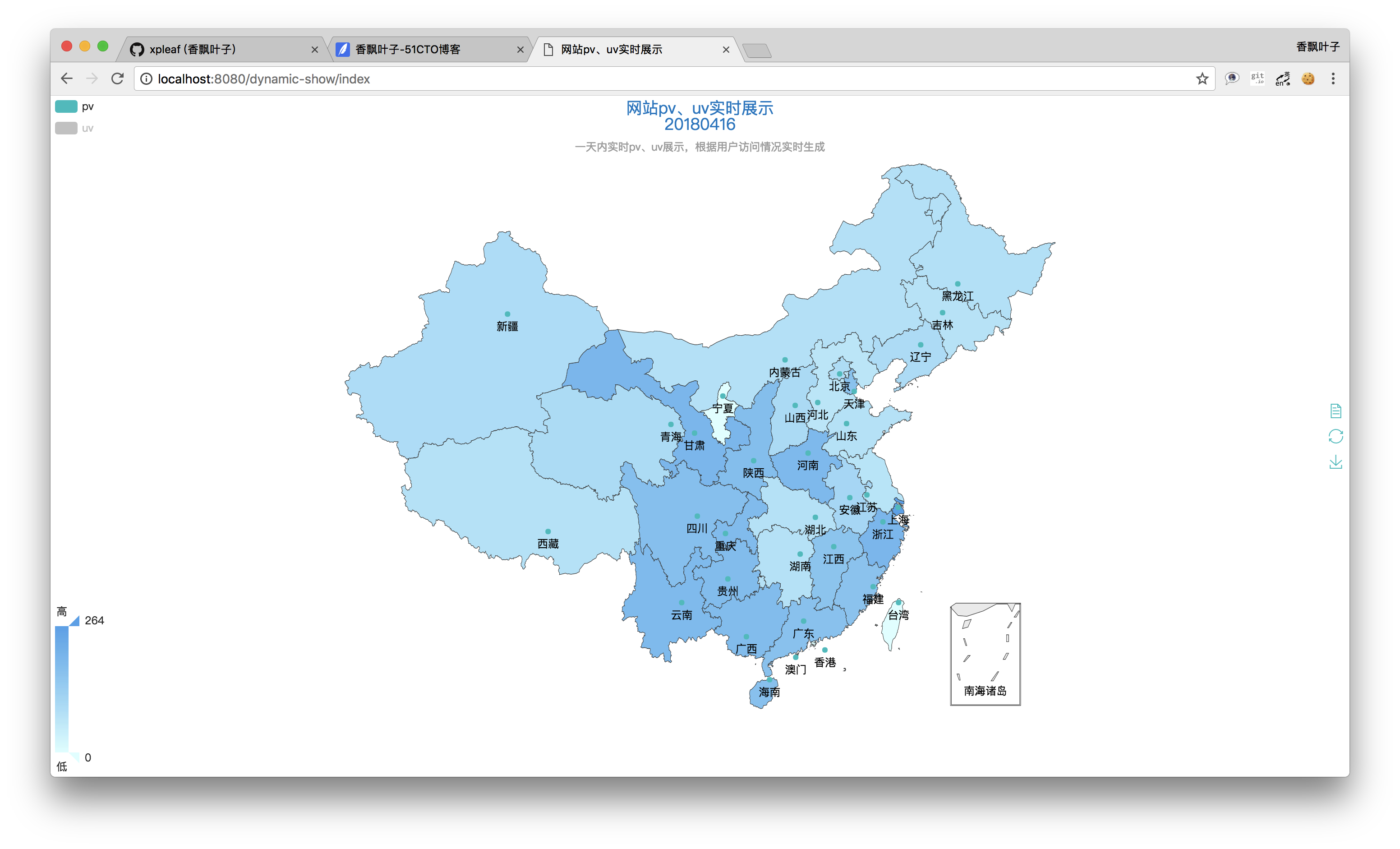
在這個界面上,點擊左上角的uv,表示不查看uv的數據,這樣我們就會只看到pv的情況:
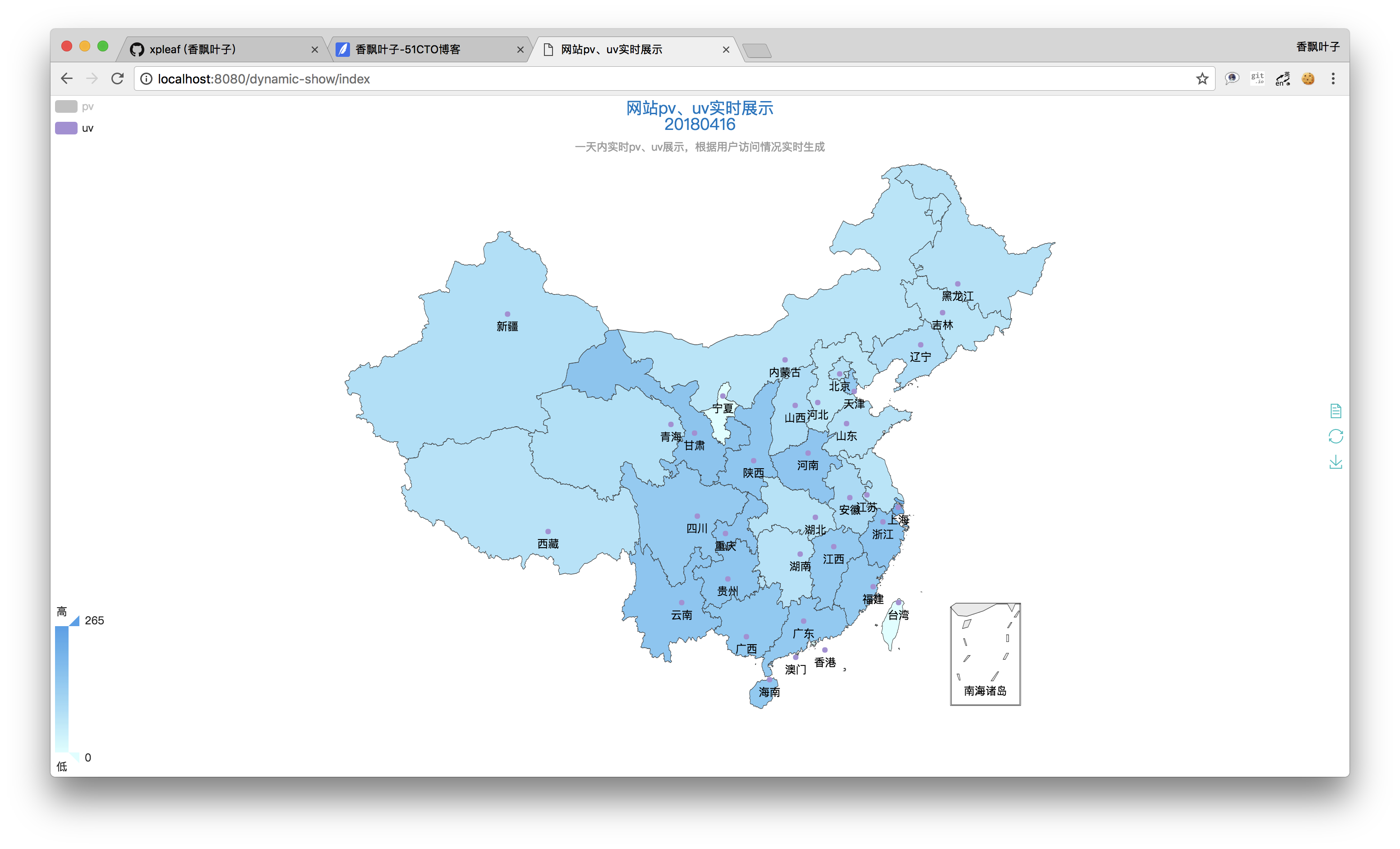
當然,也可以只查看uv的情況:
當鼠標停留在某個省份上時,就可以查看這個省份具體的pv或uv值,比如下面我們把鼠標停留在“廣東”上時,就可以看到其此時的pv值為170,查看其它省份的也是如此:
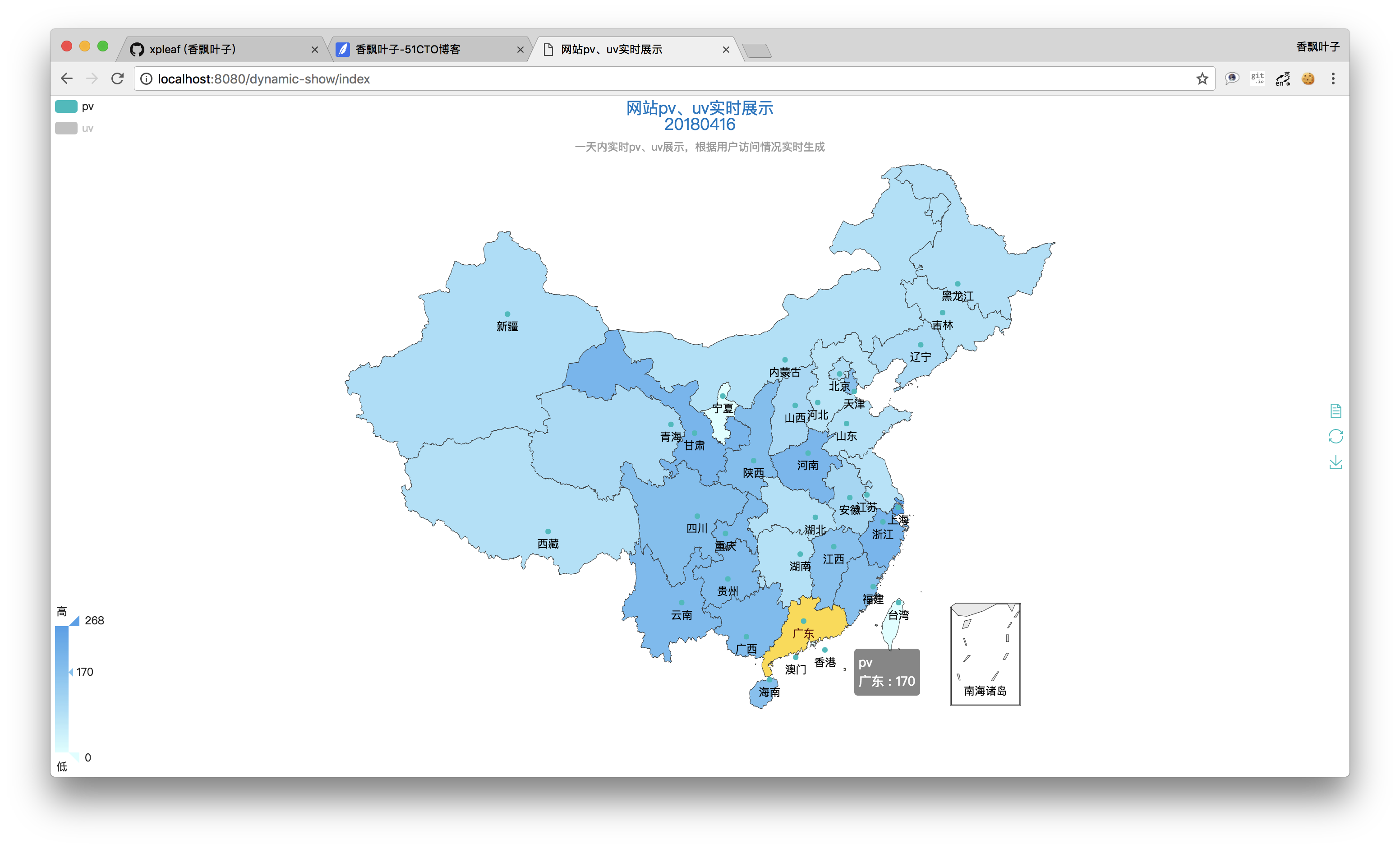
那麽數據是可以查看了,又怎麽體現動態呢?
對於頁面數據的動態刷新有兩種方案,一種是定時刷新頁面,另外一種則是定時向後端異步請求數據。
目前我采用的是第一種,頁面定時刷新,有興趣的同學也可以嘗試使用第二種方法,只需要在後端開發相關的返回JSON數據的API即可。
7 總結
那麽至此,從整個大數據實時處理系統的構建到最後的數據可視化處理工作,我們都已經完成了,可以看到整個過程下來涉及到的知識層面還是比較多的,不過我個人覺得,只要把核心的原理牢牢掌握了,對於大部分情況而言,環境的搭建以及基於業務的開發都能夠很好地解決。
寫此文,一來是對自己實踐中的一些總結,二來也是希望把一些比較不錯的項目案例分享給大家,總之希望能夠對大家有所幫助。
項目案例涉及到的代碼我已經上傳到GitHub上面,分為兩個,一個是storm的項目代碼,另外一個是數據可視化處理的代碼,如下:
storm-statistic:https://github.com/xpleaf/storm-statistic
dynamic-show:https://github.com/xpleaf/dynamic-show
Flume+Kafka+Storm+Redis構建大數據實時處理系統:實時統計網站PV、UV+展示