
編碼和編碼方式
一直在試圖搞清楚java中的編碼問題,也看了網上的一些文章,但還是雲裡霧裡。直到最近看了方立勳老師的web課程,才略略明白一點。
在此記錄一下自己的理解,看看自己能不能說清楚。
第一個問題:我在java程式碼中定義了一個字串,它是什麼編碼?
字串實質是一個char陣列。那麼char的編碼,其實就是字串的編碼。那麼char什麼編碼呢?為什麼'中'字轉int型別後的值是20013呢?
char c = '中'; System.out.println(c); // 中 System.out.println((int) c); // 20013
引入第一個概念:Unicode編碼
Unicode是一種“編碼”,所謂編碼就是一個編號(數字)到字元的一種對映關係,就僅僅是一種一對一的對映而已。
java的String使用的編碼是Unicode。
來個簡單的例子證明:
找個轉碼工具,將'中'字轉為Unicode編碼,結果是'\u4e2d'。用'\u4e2d'替換原來的'中'字。列印的結果和'中'字是一樣的。
char c = '\u4e2d'; System.out.println(c); // 中 System.out.println((int) c); // 20013
'\u'是什麼意思?
'\u'的意思就是使用了Unicode編碼。後面加上十六進位制程式碼來表示Unicode字元。下面這段程式碼可以驗證。
Integer num = Integer.valueOf("4e2d", 16);
System.out.println(num.intValue()); // 20013
第二個問題:編碼和編碼格式的區別是什麼?
這部分內容來自文章 java中的編碼和編碼格式問題 作者:風未馨
1. Unicode是一種“編碼”,所謂編碼就是一個編號(數字)到字元的一種對映關係,就僅僅是一種一對一的對映而已。
2. GBK、UTF-8是一種“編碼格式”,是用來序列化或儲存1中提到的那個“編號(數字)”的一種“格式”。
編碼和編碼格式:
java的String使用的編碼是Unicode,當String存在於記憶體中時(在程式碼中用string型別的引用對它進行操作時),是"只有編碼而沒有編碼格式的",所以java程式中的任何String物件,說它是gbk還是utf-8都是錯的,String在記憶體中不需要“編碼格式”, 它只是一個Unicode的字串而已。
當字串需要在網路中傳輸或要被寫入檔案時,就需要使用編碼格式了。亂碼問題也因此出現。
GBK和UTF-8:
GBK和UTF-8都是用來序列化或儲存Unicode編碼的資料的,但是分別是2種不同的格式,他們都是Unicode編碼的實現方式;他們倆除了格式不一樣之外,他們所關心的Unicode編碼範圍也不一樣。
UTF-8考慮了很多種不同國家的字元,涵蓋整個unicode碼錶,所以其儲存一個字元的編碼的時候,使用的位元組長度也從1位元組到4位元組不等;
而GBK只考慮中文——在Unicode中的一小部分的字元的編碼,所以它算好了只要2個位元組就能涵蓋到絕大多數常用中文(2個位元組能表示6w多種字元),所以它儲存一個字元的時候,所用的位元組長度是固定的;
ASCII碼和Unicode:
ASCII碼,和Unicode編碼一樣,也是一種"編碼"。
ASCII碼的範圍比較小,一共規定了128個字元的編碼。
Unicode編碼是一個很大的集合,現在的規模可以容納100多萬個符號。就像它的名字都表示的,這是一種包含所有符號的編碼。
當然也有其他的編碼,沒用過,我也不甚瞭解。
第三個問題:哪些地方會用到編碼格式?
前文中提到過一句話:當字串需要在網路中傳輸或要被寫入檔案時,就需要使用編碼格式了。
網路中傳輸:
對於java web開發人員,指的就是java web了。那在java web中,哪些地方需要設定編碼格式呢?
先上個圖(網上隨便拷貝來的)。假定瀏覽器就是ie,WEB伺服器是tomcat,頁面是jsp,應用伺服器用的是servlet。
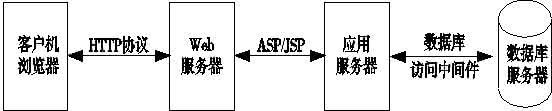
1. 瀏覽器中打開了一個頁面,這個頁面對映應用服務的某個jsp。此時瀏覽器中的解碼格式是什麼呢?
瀏覽器的解碼格式是在jsp中指定的,比如在jsp檔案中經常可以看到這樣兩行程式碼。

<!-- 這一句是和Tomcat說的:儲存在硬碟上的jsp檔案在被Tomcat翻譯成servlet的時候,使用utf-8解碼jsp檔案的內容。 如果不指定,會預設使用iso-8859-1來解碼。 -->
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%> <!-- 這一行是和瀏覽器說的:瀏覽器解碼的時候請使用utf-8解碼哦 -->
<meta http-equiv="content-type" content="text/html; charset=UTF-8">
這樣瀏覽在解析這個jsp的時候,就是使用utf-8編碼來解碼。
瀏覽器的解碼格式也是可以在瀏覽器上設定的:
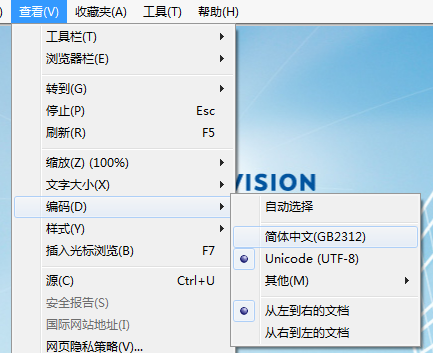
如果網頁中出現了亂碼,你換一種編碼格式來解碼,可能就不亂了。
2. response中也可以設定內容的編碼格式和指定瀏覽器的解碼格式。
開發人員應該都知道,jsp就是一個特殊一點的servlet。在servlet中, response有兩個設定編碼的方法,和jsp中的那兩行編碼配置有著相似的功能。
它們就是:
// 表示response的內容會以utf-8的編碼方式編碼後傳送給瀏覽器。
response.setCharacterEncoding("UTF-8");
// 告訴瀏覽器,解碼的時候也要使用utf-8解碼哦。
response.setContentType("text/html;charset=UTF-8");
3. 通過request物件可以指定應用服務用哪種編碼格式來解碼接收到的資料.
上面兩種情況,都是講servlet自己如何編碼,然後告訴瀏覽器如何解碼的。servlet也可以指定對接收到的物件使用哪種編碼格式來解碼。
// 通過這句話,可以指定用utf-8編碼格式來解碼瀏覽器傳來的資料。不過只對post方式傳來的資料有效。如果是get方法傳來的資料,還是會以預設的iso-8859-1來解碼。
request.setCharacterEncoding("UTF-8");
4. 設定tomcat伺服器配置檔案server.xml,指定以何種編碼解碼瀏覽器傳來的引數。
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8" />'URIEncoding="UTF-8"', 這個屬性的配置, 和"request.setCharacterEncoding("UTF-8");"這句程式碼的功能大致相同。都是指定tomcat伺服器接受到收據後如何解碼。
如果不指定,tomcat伺服器會預設使用iso-8859-1來解碼。
此處建議不要使用URIEncoding指定編碼,因為一個tomcat伺服器裡可能會有多個應用,因為某一個應用修改tomcat配置可能會導致其他應用出錯,編碼轉換在每個應用中單獨處理即可。
被寫入檔案:
1. 檔案內容在被寫入檔案時是被編碼了的,預設的編碼格式是gb2312(可能和系統有關,簡體中文系統測試,就是gb2312)。
可以在程式碼中指定檔案流在寫入檔案時用什麼編碼格式。比如指定用"utf-8".
Writer write = new OutputStreamWriter(new FileOutputStream(file), "UTF-8");
2. 檔案本身不同軟體是有選擇性的支援可以對哪些編碼進行解碼。
比如:
Excel支援gb2312,不支援UTF-8。
Txt記事本支援UTF-8編碼。
所以有時候,我下載一個csv檔案(指定內容使用utf-8編碼)。會遇到這樣的情況:
這個csv檔案在使用excel開啟的時候,中文是亂碼的,如果換成txt開啟,中文就正常顯示了。
這個時候如果想要在excel中不亂碼,就需要在程式碼中指定內容使用gb2312編碼。
也可以通過txt的'另存為',改變文字的編碼格式。
3. 如何確定檔案的編碼呢?
我在win7(簡體中文)系統中,右鍵->新建一個文字文件,nodepad++開啟後,檢視編碼,可以看到編碼是ANSI。
使用java程式碼生成一個txt檔案,未明確指定編碼格式,nodepad++開啟後,檢視編碼,可以看到編碼是utf-8。
Eclipse中做了一個小測試:
test1. 指定utf-8編碼格式
String fullPath = "D:\\test2.txt";
File file = new File(fullPath);
if (!file.exists()) {
file.createNewFile();
}
Writer write = new OutputStreamWriter(new FileOutputStream(file),
"utf-8");
write.write("你好");
write.flush();
write.close();
生成的檔案編碼格式是:
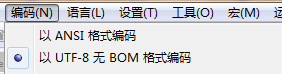
test2. 指定gb2312編碼格式
String fullPath = "D:\\test2.txt";
File file = new File(fullPath);
if (!file.exists()) {
file.createNewFile();
}
Writer write = new OutputStreamWriter(new FileOutputStream(file),
"gb2312");
write.write("你好");
write.flush();
write.close();
生成的檔案編碼格式是:
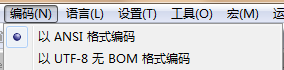
test3. 先使用utf-8生成檔案,輸出"你好",再使用gb2312,追加內容,輸出"你好",結果是這樣子的。
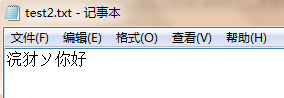
總結:
第一次使用utf-8編碼格式輸出你好,此時檔案內容 第一個"你好" 是utf-8編碼的,檔案的解碼方式也是utf-8.
第二次使用gb2312編碼格式輸出你好,此時的檔案追加的內容 第二個"你好" 是gb2312編碼的,檔案的解碼方式也變成了gb2312。
也就是說,Eclipse操作文字檔案TXT時,txt檔案會一直使用最後一次操作檔案使用的編碼格式來解碼檔案的內容。
所以第二次輸出"你好"後,第一次輸出的"你好"變成了亂碼。