
Word embeddings-詞向量
版權宣告:博主原創文章,轉載請註明來源,謝謝合作!!
https://blog.csdn.net/hl791026701/article/details/84351289
Word embeddings
詞語和句子的嵌入已經成為了任何基於深度學習的自然語言處理系統必備的組成部分,它們將詞語和句子編碼成稠密的定長向量,從而大大地提升通過神經網路處理文字資料的能力。當前主要的研究趨勢是追求一種通用的嵌入技術:在大型語料庫中預訓練的嵌入,它能夠被新增到各種各樣下游的任務模型中(情感分析、分類、翻譯等),從而通過引入一些從大型資料集中學習到的通用單詞或句子的表徵來自動地提升它們的效能。在過去的五年中,人們提出了大量可行的詞嵌入方法。目前最常用的模型是 word2vec 和 GloVe,它們都是基於分佈假設(在相同的上下文中出現的單詞往往具有相似的含義)的無監督學習方法。
儘管此後有
- lecture slides
- 蒐集的一些視訊: course intro, lecture, seminar
- Stanford CS224N的講座視訊 - intro, embeddings (english)
詞向量空間分佈

三種常見的詞向量表達方法
- On hierarchical & sampled softmax estimation for word2vec page
- GloVe project page
- FastText project repo
- Semantic change over time - oberved through word embeddings - arxiv
word2vec
Word2vec就是用來將一個個的詞變成詞向量的工具。 包含兩種結構,一種是skip-gram結構,一種是cbow結構,skip-gram結構是利用中間詞預測鄰近詞,cbow模型是利用上下文詞預測中間詞 :
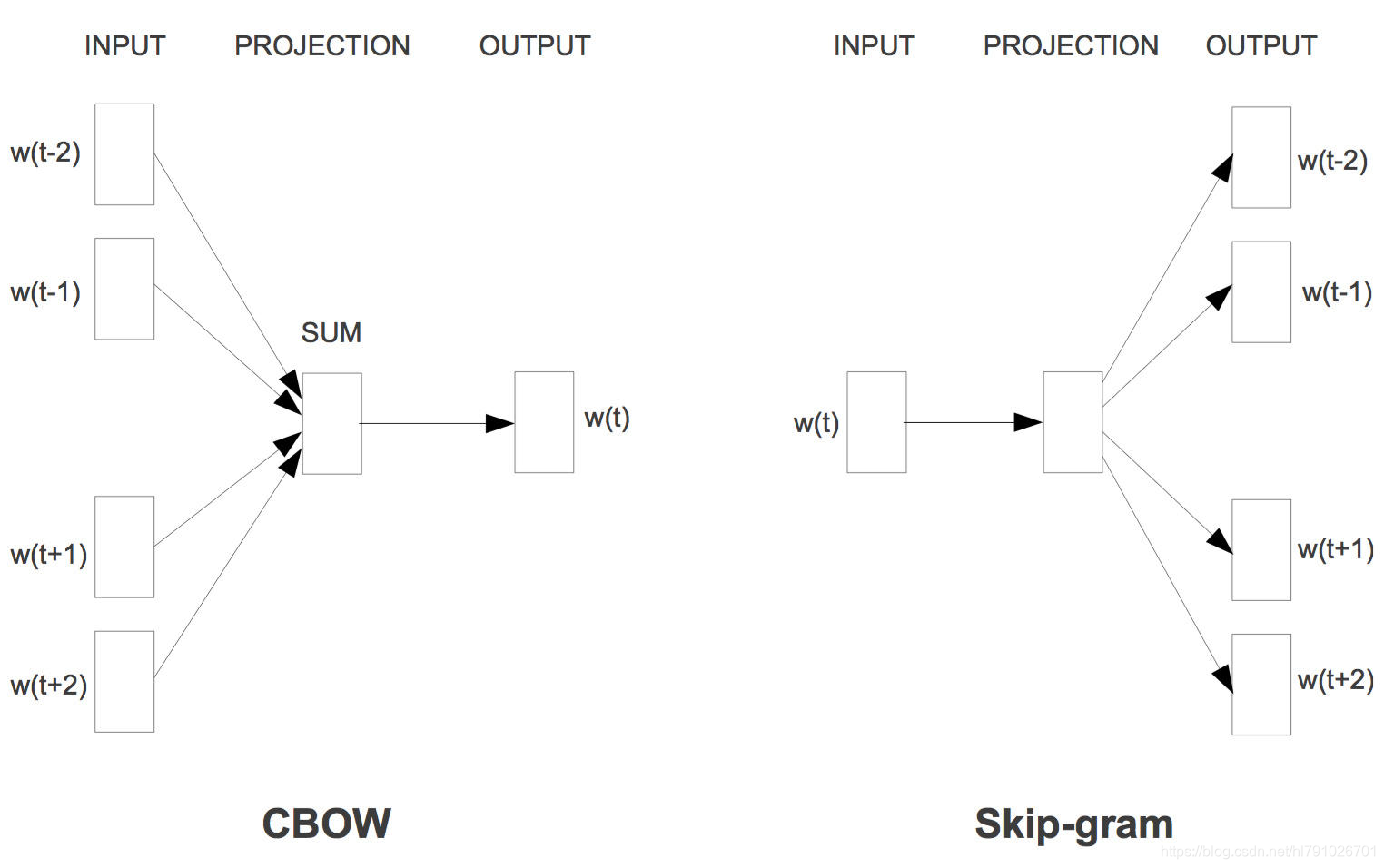
- CBOW(Continuous Bag-of-Words Model)是一種根據上下文的詞語預測當前詞語的出現概率的模型,其圖示如上圖左。CBOW是已知上下文,估算當前詞語的語言模型;而Skip-gram只是逆轉了CBOW的因果關係而已,即已知當前詞語,預測上下文,其圖示如上圖右,最後在輸出層加上Hierarchical Softmax(層次Softmax)和Negative Sampling(負取樣)兩個降低複雜度的近似方法。
- Hierarchical Softmax使用的辦法其實是藉助了分類的概念。假設我們是把所有的詞都作為輸出,那麼“足球”、“籃球”都是混在一起的。而Hierarchical Softmax則是把這些詞按照類別進行區分的,二叉樹上的每一個節點可以看作是一個使用哈夫曼編碼構造的二分類器。在演算法的實現中,模型會賦予這些抽象的中間節點一個合適的向量,真正的詞會共用這些向量。這種近似的處理會顯著帶來效能上的提升同時又不會丟失很大的準確性。
- Negative Sampling也是用二分類近似多分類,區別在於它會取樣一些負例,調整模型引數使得可以區分正例和負例。換一個角度來看,就是Negative Sampling有點懶,它不想把分母中的所有詞都算一次,就稍微選幾個算算。
- 如果感興趣具體的推到和原理可以看這裡 :word2vec原理推導與程式碼分析 , word2vec、glove和 fasttext 的比較
Glove
GloVe和word2vec的思路相似 但是充分考慮了詞的共現情況,以及其他一些trick來進行傳統矩陣分解運算進而得到word vectors,比率遠比原始概率更能區分詞的含義。
GloVe 演算法包含以下步驟:
- 使用詞共現矩陣收集詞共現資訊。每個 Xij 元素代表詞彙 i 出現在詞彙 j上下文的概率。一般我們需要掃描一遍我們的語料庫:對於每一個欄位,我們檢視在這個欄位之前或者之後,使用 window_size 定義的一定範圍內的上下文。一個詞距離這個欄位越遠,我們給予這個詞的權重越低。一般使用這個公式:
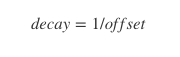
- 對於每一組詞對,
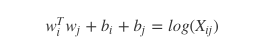
這裡 wi 向量代表主詞,wj 代表上下文詞的向量。bi, bj 是主詞和上下文詞的常數偏倚。 - 定義損失函式
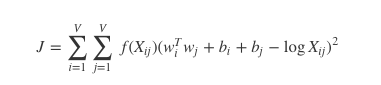
這裡 f 是幫助我們避免只學習到常見詞到一個權重函式。GloVe 到作者選擇如下到函式:
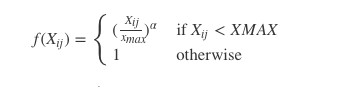
上面說到,GloVe每個詞涉及到兩個詞向量,一個詞語本身的向量wi,一個詞的context向量w~i。最初這樣設計,將word和context的向量分開,不用一套,是為了在更新引數的時候能夠簡單地套用SGD。
但是呢,我們可以看到,公式本身是對稱的,context和word其實並沒有什麼區別。
那麼兩個向量應該是一樣語義空間中的差不多的詞向量,context word vector這個副產品自然不能落下,GloVe經過一番試驗,最終發現,兩個向量加起來最後起到的效果最好。
GloVe 使用
GloVe已經在github開源,原始碼以及binary可以在GloVe Github找到。
GloVe的程式碼寫的比較糙,每一步是獨立的程式,因此要按照以下步驟進行:
- 執行./vocab_count 進行詞頻統計
- 執行./cooccur 進行共現統計
- 執行./shuffle 進行打散
- 執行./glove 進行訓練詞向量
簡單的應用
- glove+LSTM: 命名實體識別
- 用(Keras)實現,glove詞向量來源: http://nlp.stanford.edu/data/glove.6B.zip- 用(Keras)實現,glove詞向量來源: http://nlp.stanford.edu/data/glove.6B.zip
- 一開始輸入的是7類golve詞向量。The model is an LSTM over a convolutional layer which itself trains over a sequence of seven glove embedding vectors (three previous words, word for the current label, three following words).
- CV分類準確度和加權F1約為98.2%。 為了評估測試集的效能,我們將每個CV摺疊的模型輸出和預測的平均值進行整合。
來源於github:https://github.com/thomasjungblut/ner-sequencelearning
FastText
FastText, 一種技術, 也是 An NLP library by Facebook.
它由兩部分組成: word representation learning 與 text classification.
fastText簡單來說就是將句子中的每個詞先通過一個lookup層對映成詞向量,然後對詞向量取平均作為真個句子的句子向量,然後直接用線性分類器進行分類,從而實現文字分類,不同於其他的文字分類方法的地方在於,這個fastText完全是線性的,沒有非線性隱藏層,得到的結果和有非線性層的網路差不多,這說明對句子結構比較簡單的文字分類任務來說,線性的網路結構完全可以勝任,而線性結構相比於非線性結構的優勢在於結構簡單,訓練的更快。
這是對於句子結構簡單的文字來說,但是這種方法顯然沒有考慮詞序資訊,對於那些對詞序很敏感的句子分類任務來說(比如情感分類)fastText就不如有隱藏層等非線性結構的網路效果好,比如線面這幾個句子是對詞序很敏感的型別:
‘The movie is not very good , but i still like it . ’
‘The movie is very good , but i still do not like it .’
‘I do not like it , but the movie is still very good .’
這幾個句子的詞序差不多,用到的詞也差不多,但是表達的意思是完全相反的,如果直接把詞向量取平均,顯然得到的平均詞向量也是相差不到,在經過線性分類器分類很容易把這兩個不同的類別分到同一類裡,所以fastText很難學出詞序對句子語義的影響,對複雜任務還是需要用複雜網路學習任務的語義表達。
原理
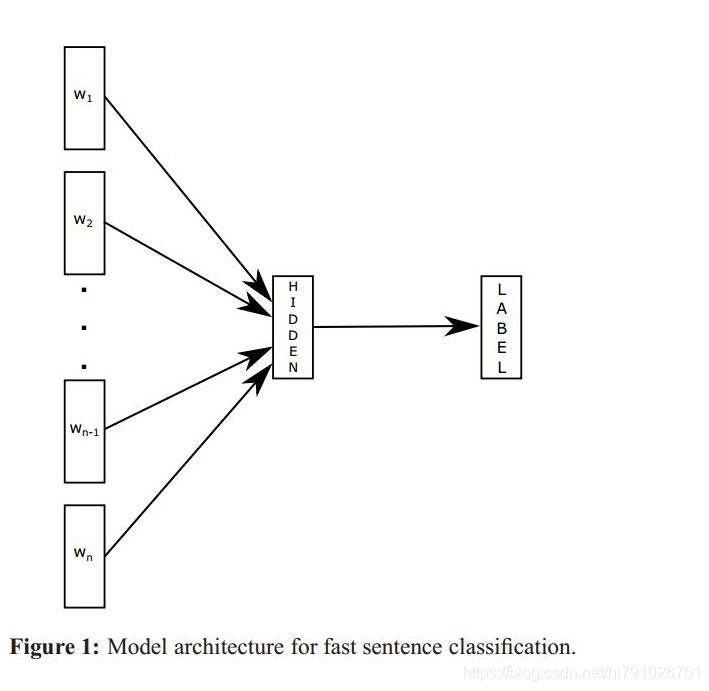
FastText優勢
適合大型資料+高效的訓練速度:能夠訓練模型“在使用標準多核CPU的情況下10分鐘內處理超過10億個詞彙”,特別是與深度模型對比,fastText能將訓練時間由數天縮短到幾秒鐘。使用一個標準多核 CPU,得到了在10分鐘內訓練完超過10億詞彙量模型的結果。此外, fastText還能在五分鐘內將50萬個句子分成超過30萬個類別。
Fasttext使用
- 安裝
pip install fasttext
- 文字分類
輸出資料格式: 樣本 + 樣本標籤 :
ex:
outline = outline.encode("utf-8") + "\t__label__" + e + "\n"
ex :姚 明 喜 歡 打 籃 球 __label__1
classifier = fasttext.supervised('data.train.txt', 'model', label_prefix='__label__')
- 測試模型和使用模型分類
#載入模型
classifier = fasttext.load_model("fasttext.model.bin",label_prefix = "__label__")
# 測試模型 其中 fasttext_test.txt 就是測試資料,格式和 fasttext_train.txt 一樣
result = classifier.test("fasttext_test.txt")
result = classifier.predict([line])
- 生成詞向量
輸入資料格式和上面一樣
model = fasttext.skipgram("all.train.txt", "model",dim = 300)
這其中還有一些其他的配置引數可以選擇,具體的引數可以檢視參考文獻。
訓練完成之後,會產生模型檔案bin和詞向量檔案vec,詞向量檔案裡面第一行是字典的長度和維度,下面是具體的詞向量。
參考:
文字分類(六):使用fastText對文字進行分類–小插曲
使用fasttext完成文字處理及文字預測
相關論文
-
Distributed Representations of Words and Phrases and their Compositionality Mikolov et al., 2013 [arxiv]
-
Efficient Estimation of Word Representations in Vector Space Mikolov et al., 2013 [arxiv]
-
Distributed Representations of Sentences and Documents Quoc Le et al., 2014 [arxiv]
-
GloVe: Global Vectors for Word Representation Pennington et al., 2014 [article]
Multilingual Embeddings. Unsupervised MT.
-
Enriching word vectors with subword information Bojanowski et al., 2016 [arxiv]
-
Exploiting similarities between languages for machine translation Mikolov et al., 2013 [arxiv]
-
Improving vector space word representations using multilingual correlation Faruqui and Dyer, EACL 2014 [pdf]
-
Learning principled bilingual mappings of word embeddings while preserving monolingual invariance Artetxe et al., EMNLP 2016 [pdf]
-
Offline bilingual word vectors, orthogonal transformations and the inverted softmax [arxiv]
Smith et al., ICLR 2017 -
Word Translation Without Parallel Data Conneau et al., 2018 [arxiv]