
95、自然語言處理svd詞向量
阿新 • • 發佈:2017-08-12
atp ear logs plt images svd分解 range src for
import numpy as np import matplotlib.pyplot as plt la = np.linalg words = ["I","like","enjoy","deep","learning","NLP","flying","."] X = np.array([[0,2,1,0,0,0,0,0], [2,0,0,1,0,1,0,0], [1,0,0,0,0,0,1,0], [0,1,0,0,1,0,0,0], [0,0,0,1,0,0,0,1], [0,1,0,0,0,0,0,1], [0,0,1,0,0,0,0,1], [0,0,0,0,1,1,1,0]]) U,s,Vh=la.svd(X, full_matrices=False) for i in range(len(words)): print(U[i,1],U[i,1],words[i]) plt.text(U[i,0],U[i,1],words[i]) plt.xlim(-1,1) plt.ylim(-1,1) plt.show()
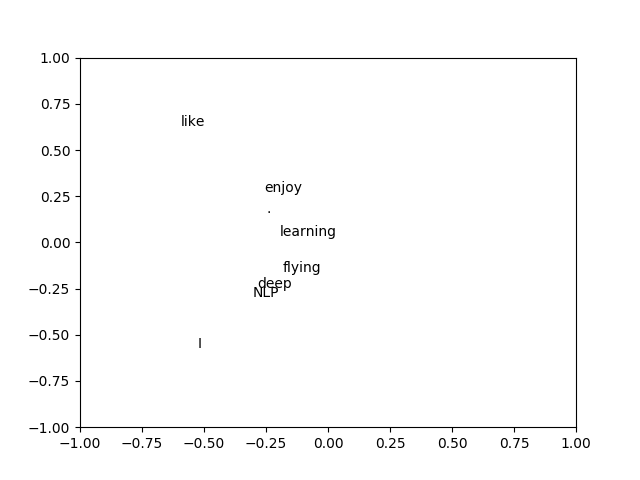
這是根據斯坦福cs224d課程寫出來的,
這是課程裏邊最開始所講的詞向量,
1、首先將所有的詞組織成一個詞典
2、對於詞典中的每一個詞,
掃描詞典中的其他詞,
對於掃描到的每一個詞,
統計原始詞在被掃描到的詞的前邊或者後邊出現的次數,
這樣就構成了一個由詞頻所構成的對角陣
3、對該對角陣進行SVD分解得到
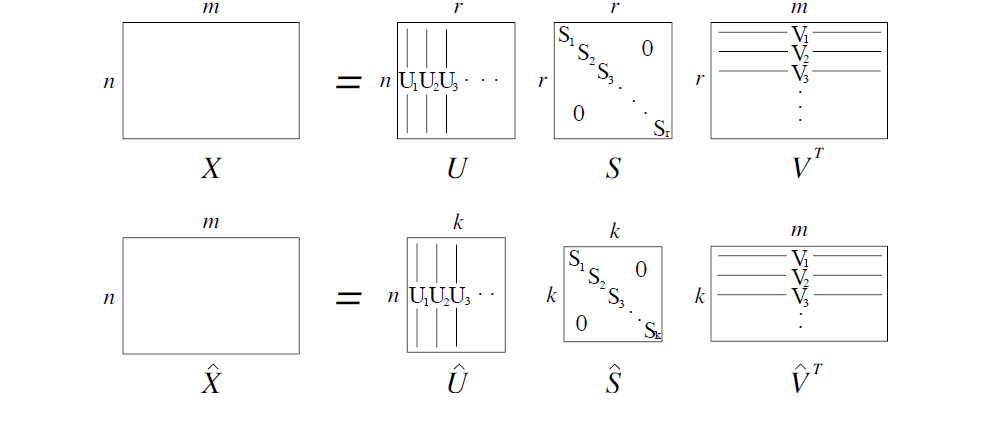
得到的U矩陣便是經過降維後的詞向量矩陣
將每個詞的詞向量前兩個值畫在圖中
便得到了如最上面圖所示的
詞關系圖
Thanks
WeiZhen
95、自然語言處理svd詞向量