Ubuntu18.04.1 LTS 安裝Spark
Spark部署模式主要有四種:Local模式(單機模式)、Standalone模式(使用Spark自帶的簡單叢集管理器)、YARN模式(使用YARN作為叢集管理器)和Mesos模式(使用Mesos作為叢集管理器)。
本文進行Local模式(單機模式)的 Spark2.1.0版本安裝。安裝spark前需保證:Hadoop2.7.1或以上與Java JDK1.8或以上均已正確安裝並配置
spark下載:http://spark.apache.org/downloads.html
sudo tar -zxf ~/Downloads/spark-2.1.0-bin-without-hadoop.tgz -C /usr/local/
cd 安裝後,還需要修改Spark的配置檔案spark-env.sh
cd /usr/local/spark
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
編輯spark-env.sh檔案(vim ./conf/spark-env.sh),在第一行新增以下配置資訊:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
有了上面的配置資訊以後,Spark就可以把資料儲存到Hadoop分散式檔案系統HDFS中,也可以從HDFS中讀取資料。如果沒有配置上面資訊,Spark就只能讀寫本地資料,無法讀寫HDFS資料。
然後通過如下命令,修改環境變數
vim ~/.bashrc
在.bashrc檔案中新增如下內容
export JAVA_HOME=/usr/lib/jvm/default-java export HADOOP_HOME=/usr/local/hadoop export SPARK_HOME=/usr/local/spark export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.4-src.zip:$PYTHONPATH export PYSPARK_PYTHON=python3 export PATH=$HADOOP_HOME/bin:$SPARK_HOME/bin:$PATH
PYTHONPATH環境變數主要是為了在Python3中引入pyspark庫,PYSPARK_PYTHON變數主要是設定pyspark執行的python版本。
.bashrc中必須包含JAVA_HOME,HADOOP_HOME,SPARK_HOME,PYTHONPATH,PYSPARK_PYTHON,PATH這些環境變數。如果已經設定了這些變數則不需要重新新增設定。
接著還需要讓該環境變數生效,執行如下程式碼:
source ~/.bashrc
配置完成後就可以直接使用,不需要像Hadoop執行啟動命令。
通過執行Spark自帶的示例,驗證Spark是否安裝成功。
cd /usr/local/sparkbin/run-example SparkPi
找到pi的例子(2>&1 可以將所有的資訊都輸出到 stdout 中):
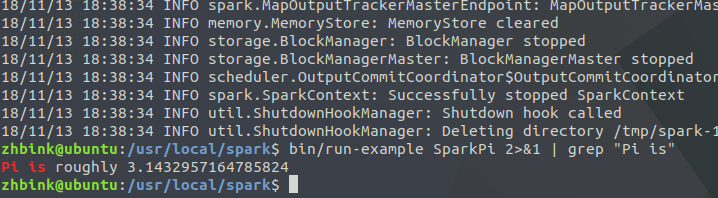
bin/run-example SparkPi 2>&1 | grep "Pi is"
這裡涉及到Linux Shell中管道的知識,詳情可以參考Linux Shell中的管道命令
過濾後的執行結果如下圖示,可以得到π 的 5 位小數近似值: