
Task原理原始碼分析

在Executor類中的TaskRunner是執行Task的入口
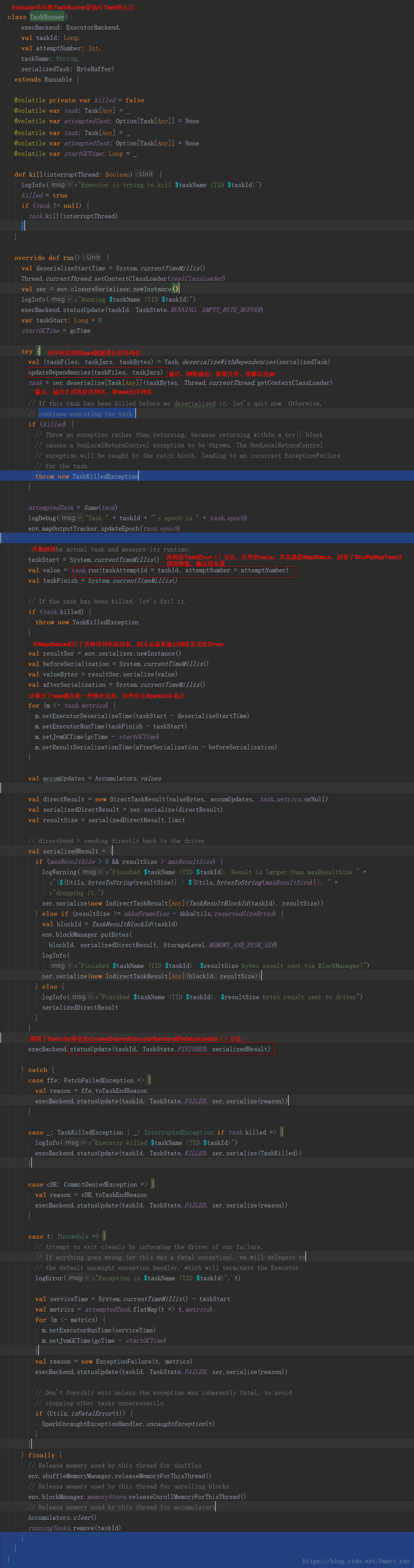
進入updateDependencies()函式

進入Task類中的run()方法
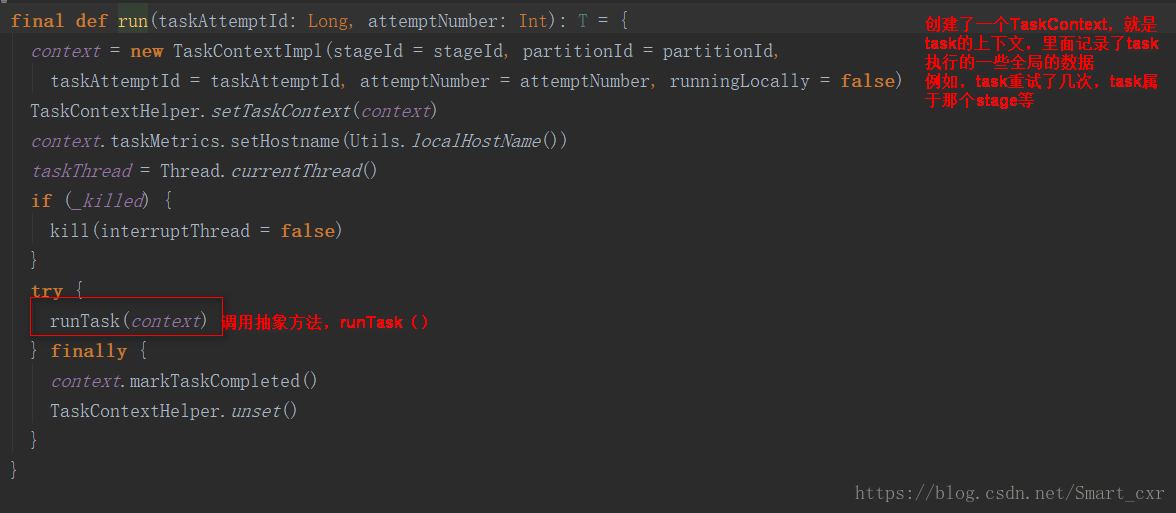
在上面的Task的run方法中,呼叫了抽象方法,runTask(),那就意味著關鍵的操作都要依賴於子類的實現,Task的子類ShuffleMapTask,ResultTask,要執行它們的runTask,才能執行我們自定義的運算元和邏輯
接下來是先進入ShuffleMapTask類進行分析
一個ShuffleMapTask會將一個RDD的元素,切分為多個bucket,基於一個在ShuffleDependency中指定的partitioner,預設就是HashPartitioner
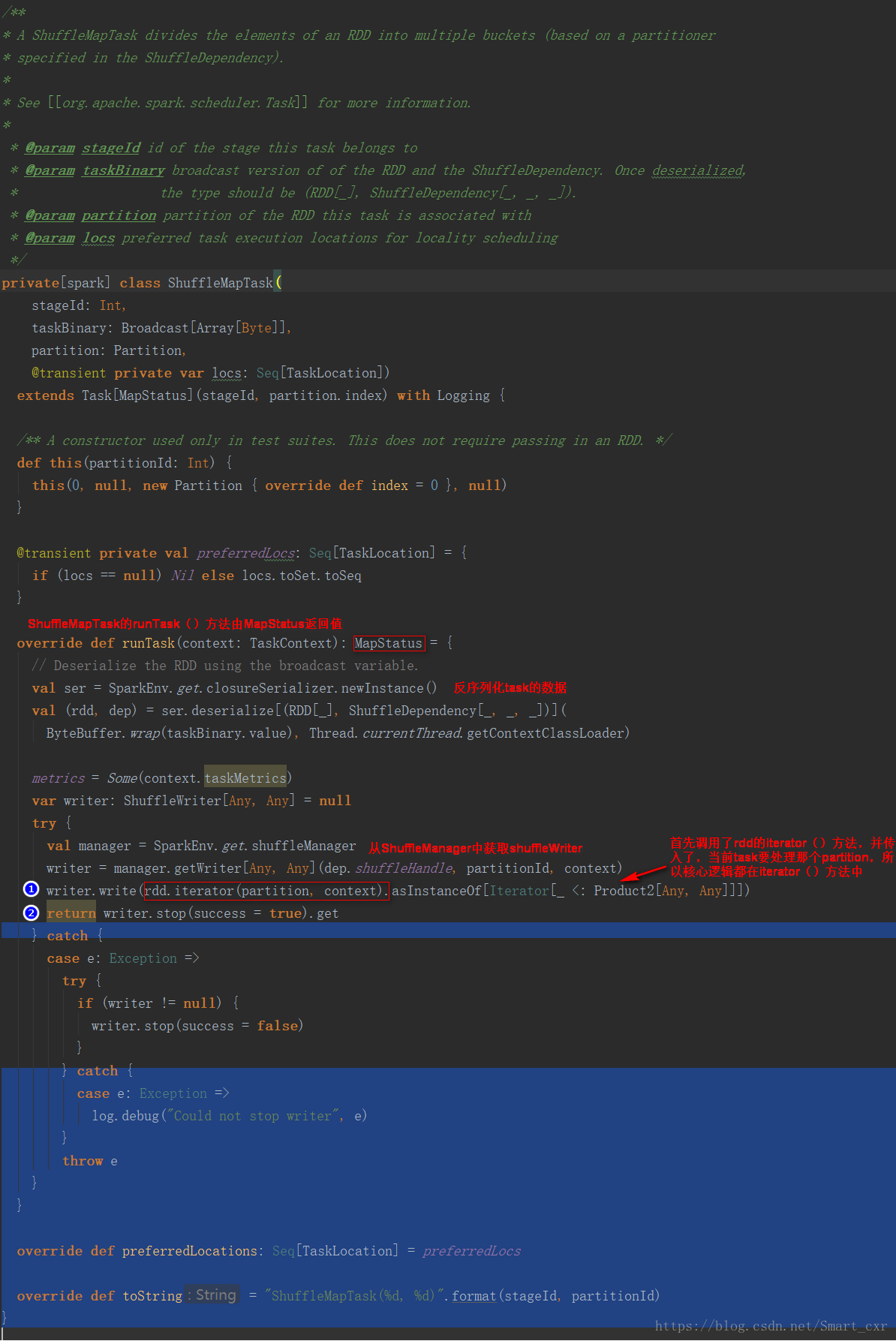
①首先呼叫了rdd的iterator()方法,並且傳入了,當前task要處理哪個partition,所以核心的邏輯就在rdd的iterator()方法中,在這裡,就實現了針對rdd的某個partition,執行我們自己定義的運算元或者函式,執行結束返回的資料都是通過ShuffleWriter,經過HashPartitioner進行分割槽之後,寫入自己對應的分割槽bucket
②返回結果MapStatus,MapStatus裡面封裝了ShuffleMapTask計算後的資料,其實就是BlockManager相關資訊,BlockManager,是spark底層的記憶體、資料、磁碟資料管理的元件
進入RDD類的iterator()方法
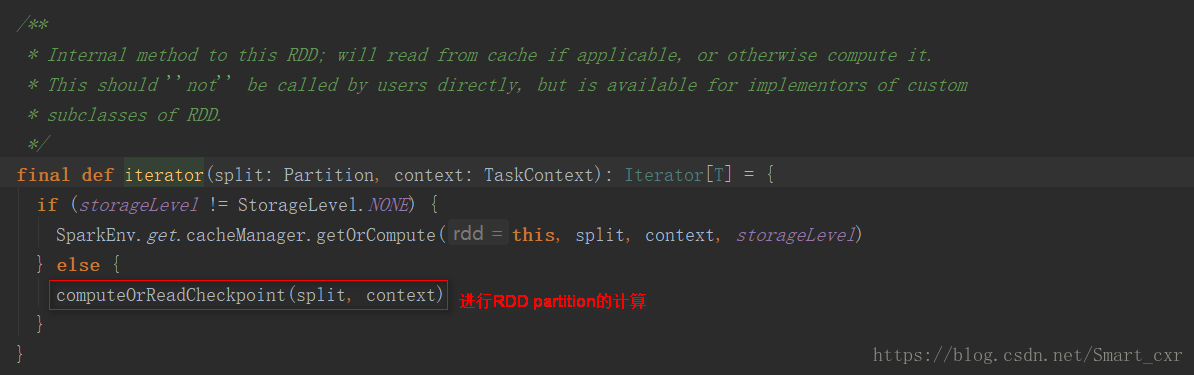
進入computeOrReadCheckpoint()方法

進入compute()方法
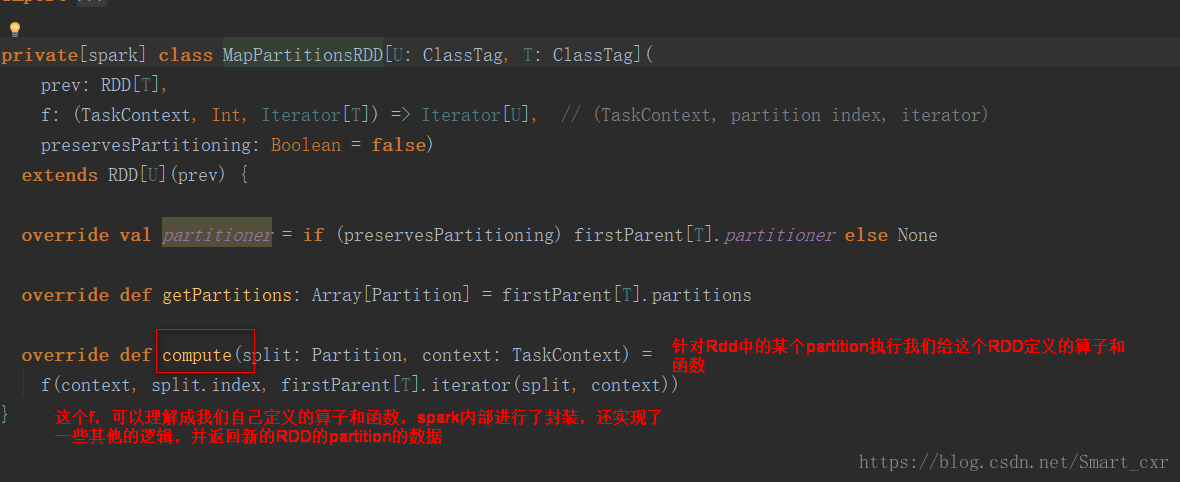
到這裡對ShuffleMapTask類進行分析已經結束了
接下來是繼續對第一張圖中的statusUpdate()方法剖析,進入CorassGrianeExecuBackend的statusUpdate()方法
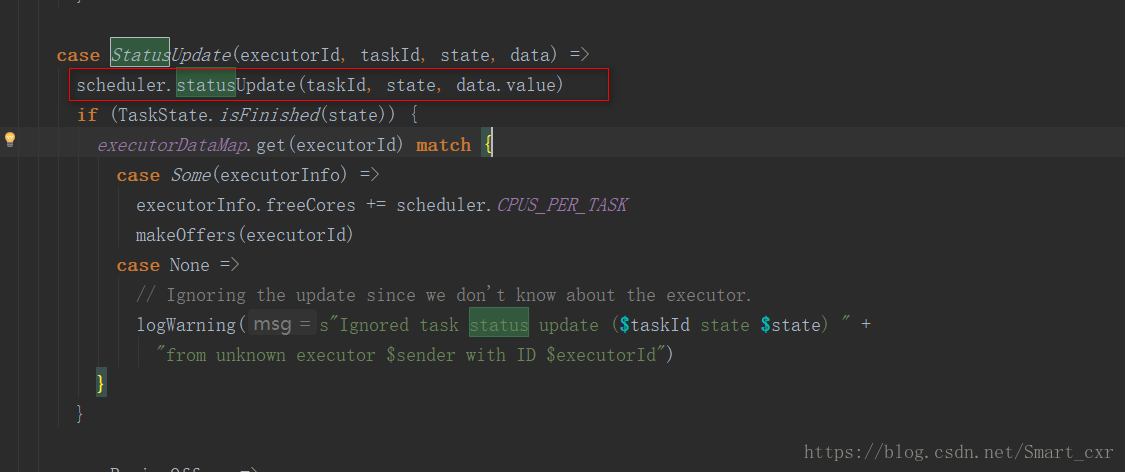
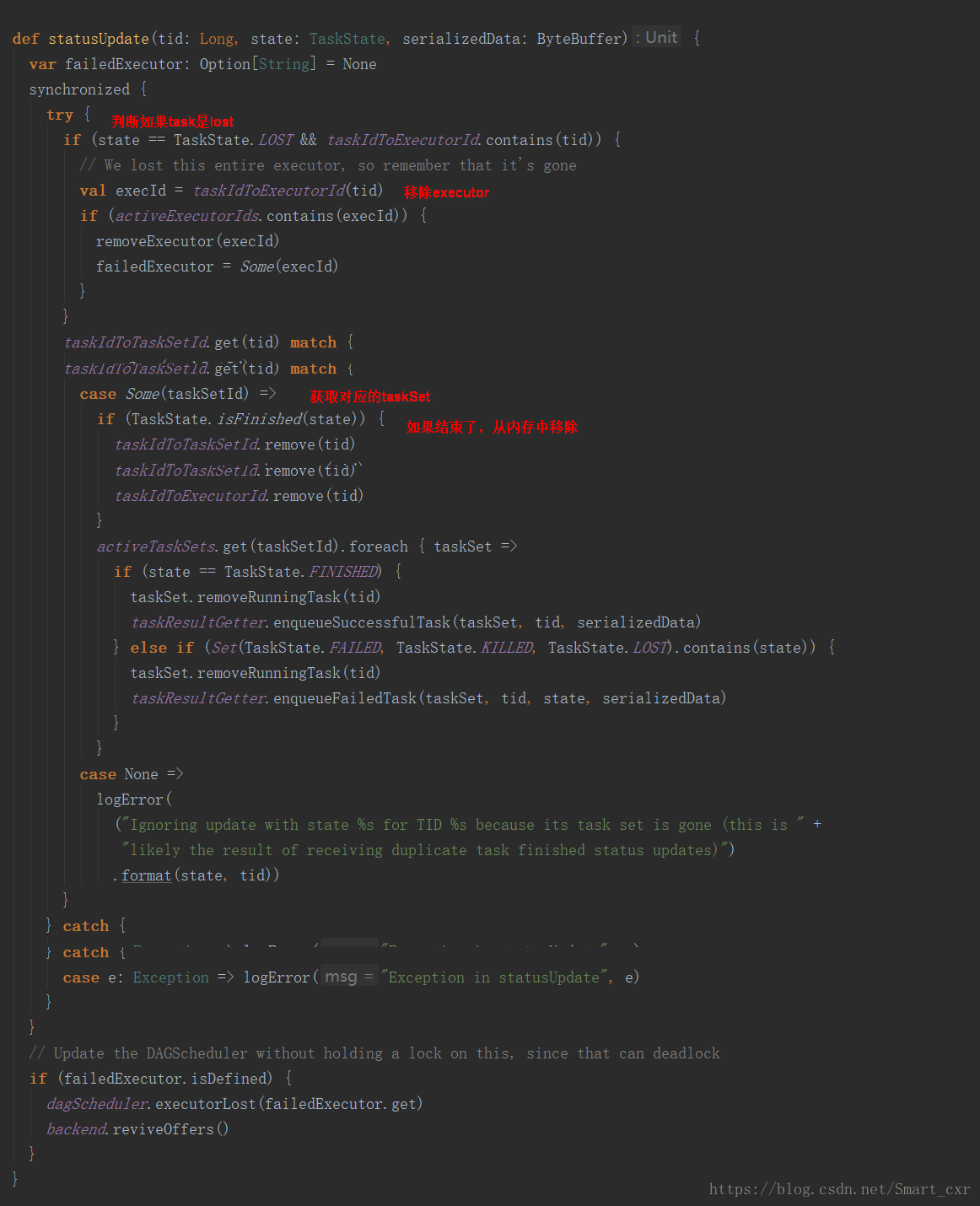
緊接著進入scheduler的statusUpdate()方法
最後對ResultTask的runTask進行剖析,因為ResultTask是最後一個Task因此它的方法內容比較簡單
