
第二章 網路應用
目錄
1.網路應用體系結構
客戶機/伺服器(C/S):
伺服器:提供服務,永久域名,可擴充套件性
客戶機:使用服務,間歇性,動態IP,不與其他客戶機直接通訊
P2P(peer to peer):
無永遠線上的伺服器,任意結點可直接通訊,間歇性,動態IP->高度可伸縮、難於管理
(存在客戶機程序和伺服器程序之分)
補充:P2P是指網上各臺計算機有相同的功能,無主從之分,一臺計算機都是既可作為伺服器,設定共享資源供網路中其他計算機所使用,又可以作為工作站,沒有專用的伺服器,也沒有專用的工作站。對等網路是小型區域網常用的組網方式。
P2P拓撲結構效能對比圖:來源(https://www.cnblogs.com/linsanshu/p/5546948.html)
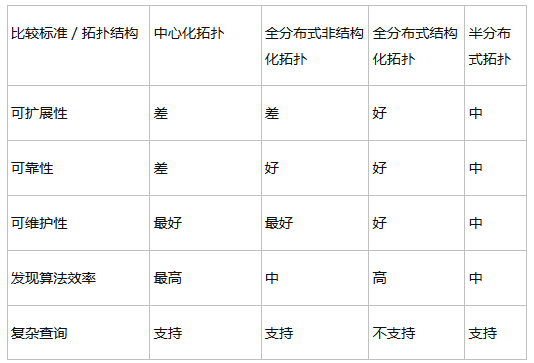
混合結構(Hybrid):
•Napster
檔案傳輸使用P2P結構(速度快)
檔案的搜尋使用C/S結構——集中式
每個節點向中央伺服器登記自己的內容
每個節點向中央伺服器提交查詢請求,查詢感興趣的內容
2.網路應用的服務需求
可靠性/資料丟失(data loss)/可靠性(reliability)
頻寬(bandwidth)
時延(delay)/時間(timing)
3.Internet傳輸層服務模型
TCP
面向連線:
可靠的傳輸
流量控制
擁塞控制(網路負載過重時可限制發方的傳送速度)
不提供時間延遲保障
不提供最小頻寬保障
UDP
無連線、不可靠、無控制
功能交給應用層實現
簡潔對比圖:

4.特定網路應用協議
Web應用
•物件的定址(addressing):
URL(Uniform Resource Locator):統一資源定位器
Scheme://host:port/path
HTTP
HTTP協議
•超文字傳輸協議(Hypertext Transfer Protocol)
•採用客戶/伺服器架構
客戶-Browser:請求、接收、展示web物件
伺服器-Web Server:響應客戶的請求,傳送物件
•HTTP版本:
1.0:RFC 1945
1.1:RFC 2068
•使用TCP傳輸服務

•無狀態(stateless)
伺服器不維護任何有關客戶端過去所發請求的資訊
HTTP連線
非永續性連結(Nonpersistent HTTP)
每個TCP連線最多允許傳輸一個物件
HTTP 1.0版本使用非永續性連線
分析:


RTT(Round Trip Time):從客戶端傳送一個很小的資料包到伺服器並返回所經歷的時間
永續性連結(Persistent HTTP)
每個TCP連線允許傳輸多個物件
HTTP 1.1版本預設使用永續性連線
•無流水的永續性連線:
客戶端只有收到前一個響應後才傳送新請求
每個被引用物件耗1個RTT
•帶流水機制的永續性連線:
HTTP1.1預設選項
客戶端只要遇到一個引用物件就儘快發出請求
理想情況下,收到所有引用物件只耗時約1個RTT
HTTP訊息格式
1.請求訊息(ASCII):

通用格式:
上傳輸入的方法:
POST方法:網頁經常需要填寫表格、在請求訊息的Entity body中上傳客戶端的輸入
URL方法:使用GET方法,輸入資訊通過request line的URL欄位上傳
其他的一些方法:
HEAD:請求Server不要將所請求的物件放入響應訊息中
PUT:將訊息體中的檔案上傳到URL欄位所指定的路徑(HTTP/1.1)
DELETE:刪除URL欄位所指定的檔案(HTTP/1.1)

2.響應訊息:

(status line)狀態行示例:200 OK 、404 Not Found、...
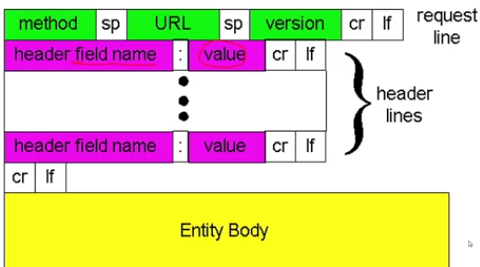
3.HTTP中的Cookie技術:
(關於Cookie的內容推薦部落格:http://www.cnblogs.com/jasonwang2y60/p/6563875.html)
Cookie技術:某些網站為了辨別使用者身份、進行session跟蹤而儲存在使用者本地終端上的資料(通常經過加密)
Cookie補充:從定義上來說,Cookie就是由伺服器發給客戶端的特殊資訊,而這些資訊以文字檔案的方式存放在客戶端,然後客戶端每次向伺服器傳送請求的時候都會帶上這些特殊的資訊。讓我們說得更具體一些:當用戶使用瀏覽器訪問一個支援Cookie的網站的時候,使用者會提供包括使用者名稱在內的個人資訊並且提交至伺服器;接著,伺服器在向客戶端回傳相應的超文字的同時也會發回這些個人資訊,當然這些資訊並不是存放在HTTP響應體(Response Body)中的,而是存放於HTTP響應頭(Response Header);當客戶端瀏覽器接收到來自伺服器的響應之後,瀏覽器會將這些資訊存放在一個統一的位置
Cookie中的元件:

(Cookie其實是HTTP頭的一部分)
Cookie的原理:
Cookie的作用:身份認證、購物車、推薦...
缺點:隱私問題;會增加寬頻,增加流量消耗
SMTP,POP,IMAP
Email應用
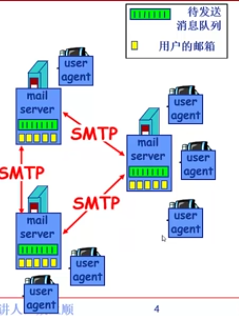
Email應用(非同步)的構成元件:
郵件客戶端:讀寫收發資訊,與伺服器互動
郵件服務端:儲存發給使用者的Email
訊息佇列:儲存等待發送的Email
SMTP協議:
•郵件伺服器之間傳遞訊息所使用的協議
•SMTP協議:Email訊息的傳輸/交換協議
•使用TCP進行Email訊息的可靠傳輸
•埠25
•傳輸過程的三個階段
握手、訊息的傳輸、關閉
•命令/響應互動模式
命令(Command): ASCII文字
響應(Response): 狀態程式碼和語句
•Email訊息只能包含7位ASCII碼
•使用永續性連線
•要求訊息必須由7位ASCII碼構成
•SMTP伺服器利用CRLF.CRLF確定訊息的結束
•與HTTP對比
HTTP: 拉式(Pull)
SMTP: 退式(Push)
都使用命令/響應互動模式
命令和狀態程式碼都是ASCII碼
HTTP: 每個物件封裝在獨立的響應訊息中
SMTP: 多個物件在由多個部分構成的訊息中傳送
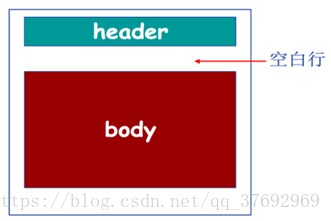
Email訊息格式
•RFC 822文字訊息格式標準
頭部行(Header):
To
From
Subject
訊息體(Body)
訊息本身
只能是ASCII字元
•MIME:多媒體郵件擴充套件
通過在郵件頭部增加額外行以宣告MIME的內容型別

郵件訪問協議
從伺服器獲取郵件
•POP:Post Office Protocol
認證/授權(客戶端<——>伺服器)和下載

POP協議模式:
(1)下載並刪除模式
使用者如果換了客戶端軟體,無法重讀該郵件
(2)下載並保持模式:不同客戶端都可以保留訊息的拷貝
(3)POP是無狀態的
•IMAP:Internet Mail Access Protocol
更多功能、更加複雜
能夠操縱伺服器上儲存的訊息
(1)所有訊息儲存在伺服器
(2)允許使用者利用資料夾組織訊息
(3)支援跨會話(Session)的使用者狀態:資料夾的名字、資料夾與訊息ID之間的對映等
•HTTP:163,QQ Mail等,通過瀏覽器使用郵箱
DNS
解決Internet上主機/路由器的識別問題.(在網路應用層實現)
域名解析系統DNS(Internet核心功能):IP地址<->域名
1、由多層命名伺服器構成的分散式資料庫
2、應用層協議:完成名字的解析
DNS的服務:
1、域名向IP地址的翻譯
2、主機別名
3、郵件伺服器別名
4、負載均衡:web伺服器(?)
問題:為什麼不使用集中式的DNS?
1、單點失敗問題
2、流量問題->流量大、成本高
3、距離問題->RTT大
4、維護性問題
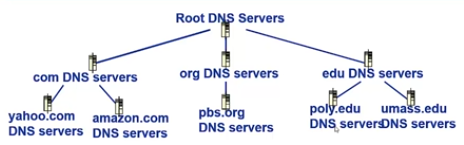
分散式層次式資料庫示意圖:
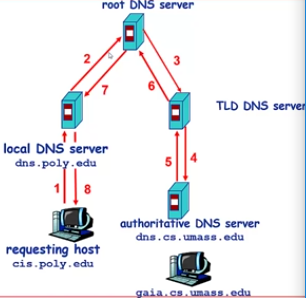
運作過程:

根域名伺服器(Root DNS Servers):
本地域名解析伺服器無法解析域名時,需要訪問根域名伺服器。若根域名伺服器不知道IP對映,則需訪問權威伺服器,從而獲得對映,接著向本地域名伺服器返回對映。
頂級域名伺服器TLD(top-level domain):負責com,org,net,edu等,國家頂級域名:如cn,uk,fr等。
權威域名伺服器:組織的域名解析伺服器,提供組織內部伺服器的解析服務。可由組織自身負責維護或者服務提供商負責維護。
本地域名解析伺服器:每個ISP(Internet Server Provider)都有一個本地域名伺服器(預設域名解析伺服器)。當主機進行DNS查詢時,本地域名伺服器作為代理,會將查詢轉發給層級時的域名解析伺服器系統。
補充:

DNS查詢示例:
迭代查詢:
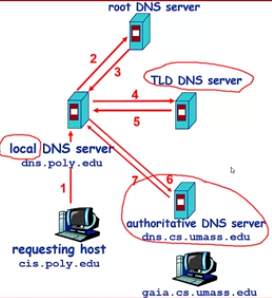
遞迴查詢:
DNS記錄快取和更新:
只要域名解析伺服器獲得域名-IP對映,即快取這一對映;本地域名伺服器一般會快取頂級域名伺服器的對映
DNS記錄:
資源記錄RR(resource records)
fomat:(name,value,type,ttl)
Type=A:
Name:主機域名
Value:IP地址
Type=NS:
Name:域
Value:該域權威域名解析伺服器的主機域名
Type=CNAME:
Name:某一真實域名的別名
Value:真實域名
Type=MX:
Value是與name相對應的郵件伺服器
DNS協議與訊息格式:
DNS協議:
查詢/回覆
訊息格式(查詢/回覆格式相同):
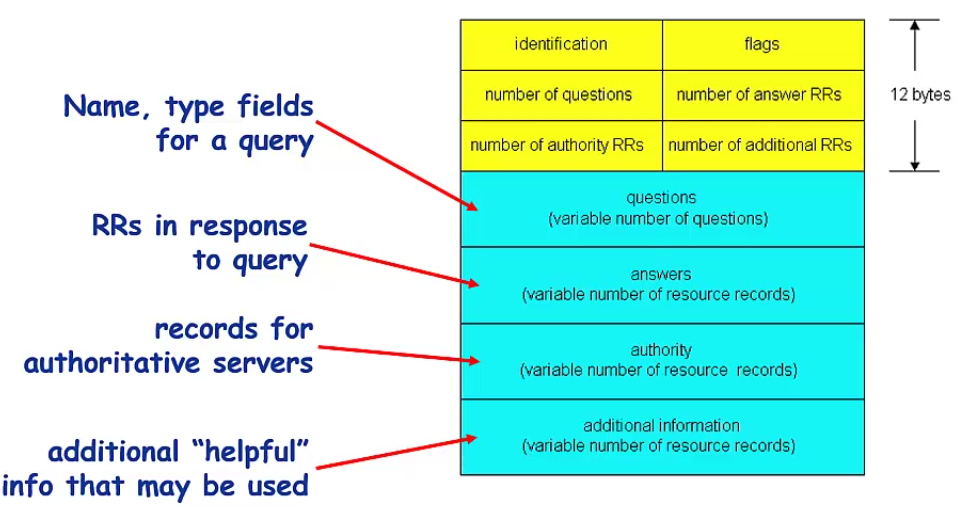
詳細解析推薦部落格:https://blog.csdn.net/tianxuhong/article/details/74922454
DNS->TCP or UDP?
註冊域名
P2P應用
1.原理與檔案分發
| 客戶機/伺服器 |
P2P |
| •伺服器序列地傳送N個副本 時間:NF/Us
•客戶機i需要F/di時間下載
•Max{NF/Us, F/min(di)} |
•伺服器必須傳送一個副本 時間:F/Us •客戶機i需要F/di時間下載 •總共需要下載NF位元 •互相分享,最快可能上傳速率:Us+Σui •Max{F/Us, F/min(di), NF/(Us+Σui)} |
客戶端上傳速率=U,F/U=1小時,Us=10U,dmin>=Us.
•客戶端/伺服器隨N線性增長
•P2P隨N增長趨於穩定

檔案分發:BitTorrent:
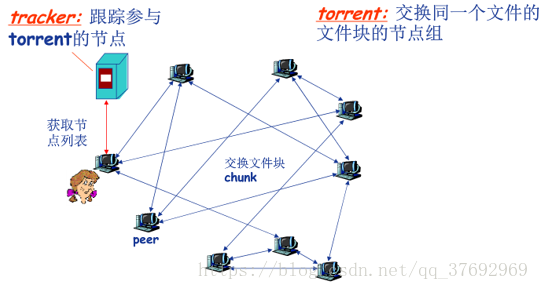
•檔案劃分為256KB的chunk
•節點加入torrent
沒有chunk,但是會逐漸積累;
向tracker註冊以獲得節點清單,與某些節點(“鄰居”)建立連線
•下載的同時,節點需要向其他節點上傳chunk
•節點可能加入或離開
•一旦節點獲得完整的檔案,它可能(自私地)離開或(無私地)留下
•獲取chunk
給定任一時刻,不同的節點持有檔案的不同chunk集合
節點(Alice)定期查詢每個鄰居所持有的chunk列表
節點發送請求,請求獲取缺失的chunk(稀缺優先)
•傳送chunk: tit-for-tat(一報還一報)
Alice向4個鄰居傳送chunk: 正在向其傳送Chunk, 速率最快的4個。
每10秒重新評估top 4。
每30秒 隨機選擇一一個其他節點,向其傳送chunk。
新選擇節點可能加入top 4。
“optimistically unchoke"
思考題:BitTorrent技術對網路效能有哪些潛在的危害?
答:答案參考https://zhidao.baidu.com/question/2078727157674570108
對硬碟的損害。BT三大指控:高溫、重複讀寫、扇區斷塊;對網路頻寬的損害;助長了病毒的傳播;可能面臨著版權侵害的風險
2.索引技術
P2P系統的索引:資訊到節點位置(IP地址+埠號)的對映
例如:檔案共享(電驢)

例如:即時訊息(QQ)

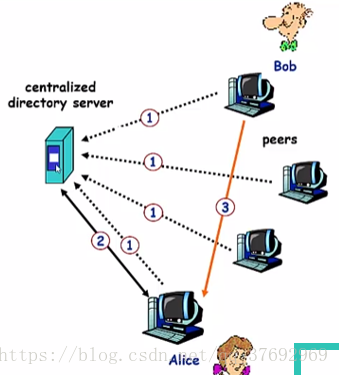
一、集中式索引

Napster最早採用這種設計
1)節點加入時,通知中央伺服器:
IP地址
內容
2) Alice查詢“Hey Jude”
3) Alice從Bob處請求檔案
缺點:
內容和檔案傳輸是分散式的,但是內容定位是高度集中式的。
•單點失效問題
•效能瓶頸
•版權問題
二、洪泛式查詢:Query flooding
•完全分散式架構
•Gnutella採用這種架構
•每個節點對它共享的檔案進行索引,且只對它共享的檔案進行索引
利用覆蓋網路進行洪泛式搜尋。什麼是覆蓋網路?
覆蓋網路(overlay network): Graph
•節點X與Y之間如果有TCP連線, 那麼構成一個邊
•所有的活動節點和邊構成覆蓋網路
•邊;虛擬鏈路
•節點一般鄰居數少於10個
洪泛式查詢工作原理:
•查詢訊息通過已有的TCP連線傳送
•節點轉發查詢訊息
•如果查詢命中,則利用反向路徑發回查詢節點
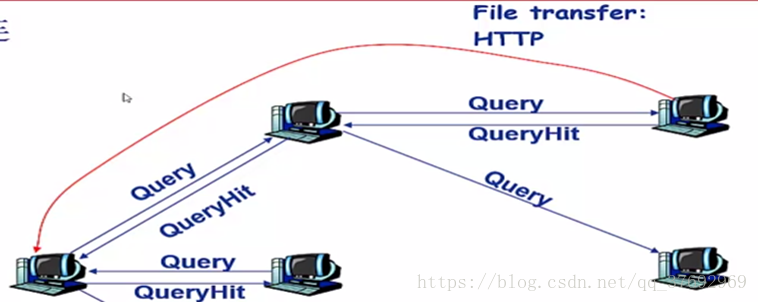
洪泛式查詢缺點:
•像洪水一樣氾濫,給網路帶來很大負擔。大量消耗網路頻寬,導致網路擁塞。
•節點剛加入時需要複雜的處理。
三、層次式覆蓋網路
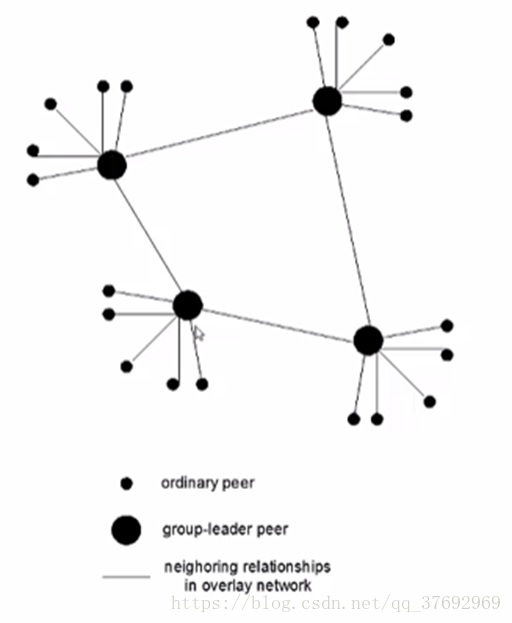
•介介於集中式索引和洪泛查詢之間的方法
•每個節點或者是一個超級節點,或者被分配一個超級節點
1)節點和超級節點間維持TCP連線;
2)某些超級節點對之間維持TCP連線。
•超級節點負責跟蹤子節點的內容
案例應用:Skype
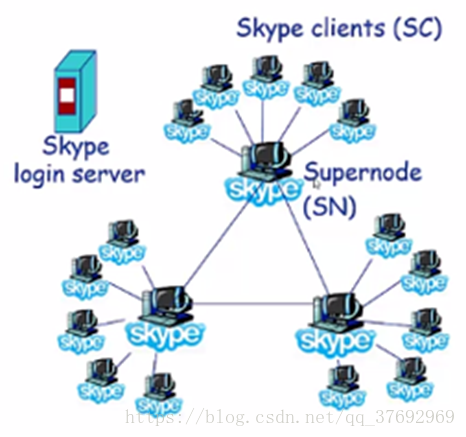
•本質上是P2P的:使用者/節點對之間直接通訊
•私有應用層協議
•採用層次式覆蓋網路架構
•索引負責維護使用者名稱與IP地址間的對映
•索引分佈在超級節點上
5.Socket程式設計
Socket API
網路程式設計介面
Socket API:
•標識通訊端點(對外) :IP地址+埠號
•作業系統/程序管理套接字(對內) :套接字描述符(socket descriptor)
Socket抽象:

•類似於檔案的抽象
•當應用程序建立套接字時,作業系統分配一個數據結構儲存該套接字相關資訊
•返回套接字描述符
地址結構:

Socket API函式(WInSock):
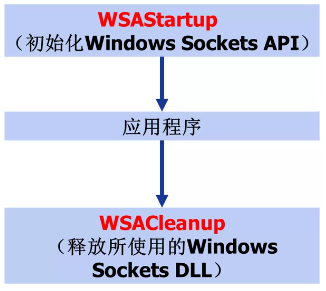
WSAStartup:
int WSAStartup(WORD wVersionRequested, LPWSADATA IpWSAData);
Socket的應用程式在使用Socket之前必須首先呼叫該函式;
兩個引數:
第一個引數:指明程式請求使用的WinSock版本,其中,高位位元組指明副版本號、低位位元組指明主版本。如0x102表示2.1版
第二個引數:返回實際的WinSock版本資訊,指向WSADATA結構的指標
•例:使用2.1 版本的WinSock的程式程式碼段
wVersionRequested = MAKEWORD(2, 1 );
err = WSAStartup( wVersionRequested, &wsaData );
WSACleanup:
int WSACleanup (void)
應用程式完成對Socket庫的使用後,最後要呼叫WSACleanup函式->解除與Socket庫的繫結,釋放Socket庫佔用的系統資源
socket:
sd = socket(protofamily,type,proto);
呼叫socket建立套接字,作業系統返回套接字描述符(sd)
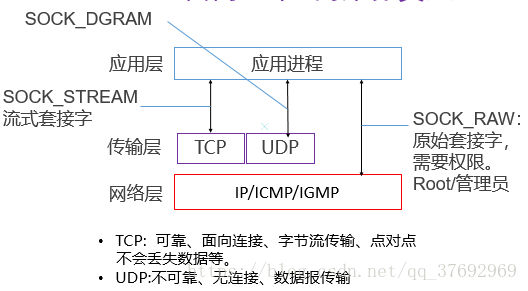
•第一個引數(協議族):protofamily= PF_ INET (TCP/IP),判斷是面向什麼協議的。
•第二個引數(套接字型別):type = SOCK_STREAM,SOCK_ DGRAM or SOCK_ RAW (TCP/IP)
•第三個引數(協議號):0為預設
•例: 建立一個流套接字的程式碼段
struct protoent *p; p=getprotobyname("tcp");
SOCKET sd=socket(PF_ INET,SOCK_ STREAM,p->p_ _proto);
其中,第二個引數的具體應用:
Closesocket:
int closesocket(SOCKET sd);
性質:
•關閉一個描述符為sd的套接字
•如果多個程序共享一一個套接字,呼叫closesocket將套接字引用計數減1,減至0才關閉
•一個程序中的多執行緒對一個套接字的使用無計數.
如果程序中的一個執行緒呼叫closesocket將-一個套接字關閉, 該程序中的其他執行緒也將不能訪問該套接字
•返回值:
0: 成功
SOCKET_ ERROR:失敗
bind:
int bind (sd, localaddr,addrlen) ;
繫結套接字的本地端點地址
• IP地址+埠號
引數:
• 套接字描述符(sd)
• 端點地址(localaddr)
結構sockaddr_ in
客戶程式一般不必呼叫bind函式
伺服器端
• 熟知埠號
• IP地址:繫結伺服器執行的主機的IP地址
在不同的網路中擁有不同的IP地址->通過 地址萬用字元 INADDR_ANY解決,不應該指定確定的IP地址
listen:
int listen (sd, queuesize) ;
•置伺服器端的流套接字處於監聽狀態
僅伺服器端呼叫
僅用於面向連線的流套接字
•設定連線請求佇列大小(queuesize)
當有很多請求到達時,就存放到佇列中快取,再從佇列中一一提取。
•返回值:
0:成功
SOCKET_ ERROR:失敗
connect:
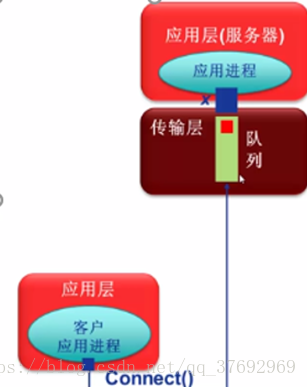
connect ( sd, saddr , saddrlen)
•客戶程式呼叫connect函式來使客戶套接字(sd)與特定計算機的特定埠(saddr) 的套接字(服務)進行連線心
•僅用於客戶端
•可用於TCP客戶端也可以用於
UDP客戶端
TCP客戶端:建立TCP連線
UDP客戶端:指定伺服器端點地址
accept:
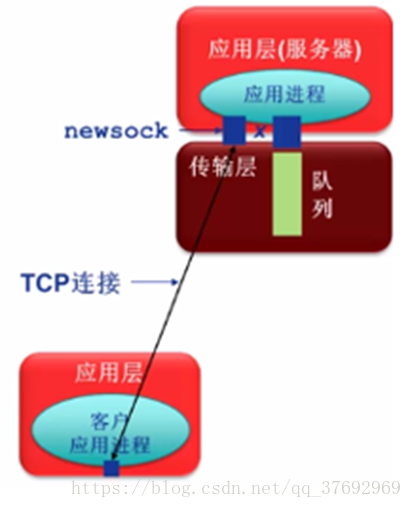
newsock = accept (sd, caddr,caddrlen);
•服務程式呼叫accept函式從處於監聽狀態的流套接字sd的客戶連線請求佇列中取出排在最前的一個客戶請求,並且建立一一個新的套接字來與客戶套接字建立連線通道
1)僅用於TCP套接字
2)僅用於伺服器
•利用新建立的套接字
(newsock)與客戶通訊
•利於實現併發TCP伺服器
send,sendto:
send (sd, *buf ,len, flags) ;
sendto (sd, *buf len, flags , des taddr , addrlen) ;
•send函式TCP套接字(客戶與伺服器)或呼叫了connect函式的UDP客戶端套接字
•sendto函式用於UDP伺服器端套接字與未呼叫connect函式的UDP客戶端套接字
recv,recvfrom:
recv (sd, *buffer,len, flags) ;
recvfrom sd, *buf,len , flags,senderaddr,saddrlen) ;
•recv函式從TCP連線的另一端接收資料,或者從
呼叫了connect函式的UDP客戶端套接字接收伺服器發來的資料
•recvfrom函式用於從UDP伺服器端套接字與未調
用connect函式的UDP客戶端套接字接收對端資料
setsockopt,getsockopt:
int setsockopt(int sd, int level, int optname, *optval, int optlen);
int getsockopt(int sd, int level, int optname, *optval, socklen_ t *optlen);
•setsockopt()函式用來設定套接字sd的選項引數
• getsockopt()函式用於獲取任意型別、任意狀態套介面的選項當前值,並把結果存入optval
小節:
•WSAStartup:初始化socket庫(僅對WinSock)
•WSACleanup:清楚/終止socket庫的使用(僅對WinSock)socket:建立套接字
•connect:“連線”遠端伺服器(僅用於客戶端)closesocket.釋放/關閉套接字
•bind:繫結套接字的本地IP地址和埠號(通常客戶端不需要)
•listen:置伺服器端TCP套接字為監聽模式,並設定佇列大小(僅用於伺服器端TCP套接字)
•accept:接受/提取一個連線請求,建立新套接字,通過新套接(僅用於伺服器端的TCP套接字)
•recv:接收資料(用於TCP套接字或連線模式的客戶端UDP套接字)
•recvfrom:接收資料報(用於非連線模式的UDP套接字)
•send:傳送資料(用於TCP套接字或連線模式的客戶端UDP套接字)
•sendto:傳送資料報(用於非連線模式的UDP套接字)
•setsockopt:設定套接字選項引數
•getsockopt:獲取套接字選項引數
網路位元組順序:
•TCP/IP定義了標準的用於協議頭中的二進位制整數表示:網路位元組順序(network byte order)
•某些SocketAPI函式的引數需要儲存為網路位元組順序(如IP地址、埠號等)
•可以實現本地位元組順序與網路位元組順序間轉換的函式
•htons:本地位元組順序-→網路位元組順序(16bits)
•ntohs:網路位元組順序- +本地位元組順序(16bits)
•htonl:本地位元組順序- >網路位元組順序(32bits)
•ntohl:網路位元組順序_本地位元組順序(32bits)
SocketAPI 呼叫基本流程:
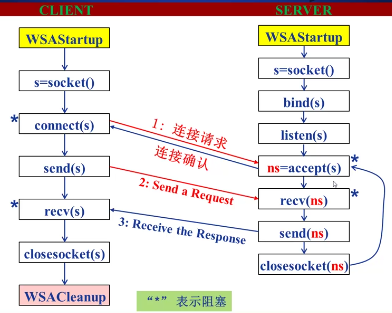
客戶端軟體設計
解析伺服器IP地址:
IP協議需要使用32位二進位制IP地址。
將域名或IP地址轉換位32位IP地址的函式:
1)函式inet_ add( )實現點分十進位制IP地址到32位IP地址轉換
2)函式gethostbyname( )實現域名到32位IP地址轉換
返回一個指向結構hostent的指標

解析伺服器(熟知)埠號:
將服務名(如http)轉換為熟知埠號的函式:

解析協議號:
需要將協議名轉換為協議號:

| TCP客戶端軟體流程 |
UDP客戶端軟體流程 |
| 1.確定伺服器IP地址與埠號 2.建立套接字 3.分配本地端點地址(IP地址+埠號) 4.連線伺服器(套接字) 5.遵循應用層協議進行通訊 6.關閉/釋放連線 |
1.確定伺服器IP地址與埠號 2.建立套接字 3.分配本地端點地址(IP地址+埠號) 4.指定伺服器端點地址,構造UDP資料報 5.遵循應用層協議進行通訊 6.關閉/釋放套接字 |
客戶端軟體的實現-connectsock()




客戶端軟體的實現-UDP客戶端

客戶端軟體的實現-TCP客戶端:

客戶端軟體的實現-異常處理

例:
訪問DAYTIME服務的客戶端(TCP):
(資料流傳輸)





訪問DATTIME服務的客戶端(UDP):
(資料報傳輸)

MSG:給DAYTIME伺服器傳送的訊息



伺服器軟體設計
基於套接字程式設計的伺服器端軟體設計:
4種類型基本伺服器:
•迴圈無連線(Iterative connectionless)伺服器
•循環面向連線(terative connection-oriented)伺服器
•併發無連線(Concurrent connectionless)伺服器
•併發面向連線(Concurrent connection-oriented)伺服器
迴圈無連線伺服器基本流程:
1.建立套接字
2.繫結端點地址(INADDR_ ANY+埠號)
3.反覆接收來自客戶端的請求
4.遵循應用層協議,構造響應報文,傳送給客戶
資料傳送:
•伺服器端不能使用connect()函式
•無連線伺服器使用sendto()函式傳送資料報
retcode=sendto (socket , data , length , flags , destaddr , addrlen) ;
註釋:
•socket:伺服器(UDP)套接字
•data:儲存待發送資料快取的地址
•length:快取中資料位元組數
•flags:除錯或控制選項
•destaddr:指向結枸sockaddr_ in的指籵(客戸端端點地址)
•addrlen:地址結構長度
客戶的端點地址在呼叫recvfrom()函式接收資料時 自動提取:
retcode=recvf com ( socket ,buf , length, flags , from, fromlen) ;
註釋:
•socket : (UDP)伺服器套接字
•buf:存放資料報的快取地址
•length:快取可用空間
•flags:除錯或控制選項
•from:存放源地址的快取地址
•fromlen:源地址長度
循環面向連線伺服器的基本流程:
1.建立(主)套接字,並繫結熟知埠號;
2.設定(主)套接字為被動監聽模式,準備用於伺服器;
3. 呼叫accept()函式接收下一一個連線請求(通過主套接字),建立新套接字用於與該客戶建立連線;
4. 遵循應用層協議,反覆接收客戶請求,構造併發送響應(通過新套接字);
5. 完成為特定客戶服務後,關閉與該客戶之間的連線,返回步驟3.
併發無連線伺服器基本流程:
•主執行緒1:建立套接字,並繫結熟知埠號;
•主執行緒2:反覆呼叫recvfrom()函式,接收下一個客戶請求,並建立新執行緒處理該客戶響應;
•子執行緒1:接收一個特定請求;
•子執行緒2:依據應用層協議構造響應報文,並呼叫sendto()傳送;
•子執行緒3:退出(一個子執行緒處理-一個請求後即終止)。
併發面向連線伺服器的基本流程:
•主執行緒1:建立(主)套接字,並繫結熟知埠號;
•主執行緒2:設定(主)套接字為被動監聽模式,準備用於伺服器;
•主執行緒3:反覆呼叫accept()函式接收下一一個連線請求(通過主套接字),並建立一一個新的子執行緒處理該客戶響應;
•子執行緒1:接收一一個客戶的服務請求(通過新建立的套接字) ;
•子執行緒2:遵循應用層協議與特定客戶進行互動;
•子執行緒3:關閉/釋放連線並退出(執行緒終止).
伺服器的實現:

passivesock:



passiveUDP():

passiveTCP():

(同時參考https://www.cnblogs.com/cellphone7/p/9520438.html,十分感謝)