
Kubernetes資源排程1--k8s資源排程
研究一下Kubernetes的資源排程器的實現原理以及大神們的改進。
k8s的基本架構如下:

Scheduler排程器做為Kubernetes三大核心元件之一, 承載著整個叢集資源的排程功能,其根據特定排程演算法和策略,將Pod排程到最優工作節點上,從而更合理與充分的利用叢集計算資源。其作用是根據特定的排程演算法和策略將Pod排程到指定的計算節點(Node)上,其做為單獨的程式執行,啟動之後會一直監聽API Server,獲取PodSpec.NodeName為空的Pod,對每個Pod都會建立一個繫結。預設情況下,k8s的排程器採用擴散策略,將同一叢集內部的pod物件排程到不同的Node節點,以保證資源的均衡利用。
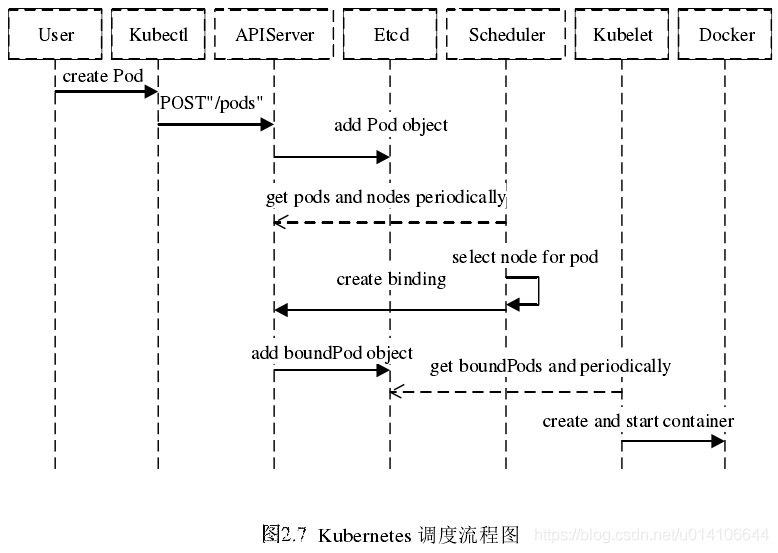
首先使用者通過 Kubernetes 客戶端 Kubectl 提交建立 Pod 的 Yaml 的檔案,向Kubernetes 系統發起資源請求,該資源請求被提交到
Kubernetes 系統中,使用者通過命令列工具 Kubectl 向 Kubernetes 叢集即 APIServer 用 的方式傳送“POST”請求,即建立 Pod 的請求。
APIServer 接收到請求後把建立 Pod 的資訊儲存到 Etcd 中,從叢集執行那一刻起,資源排程系統 Scheduler 就會定時去監控 APIServer
通過 APIServer 得到建立 Pod 的資訊,Scheduler 採用 watch 機制,一旦 Etcd 儲存 Pod 資訊成功便會立即通知APIServer,APIServer會立即把Pod建立的訊息通知Scheduler,Scheduler發現 Pod 的屬性中 Dest Node 為空時(Dest Node=””)便會立即觸發排程流程進行排程。
Kubernetes的排程器以外掛化形式實現的,排程器的原始碼位於kubernetes/plugin/中
kubernetes/pkg/scheduler/
`-- scheduler //排程相關的具體實現
|-- algorithm
| |-- predicates //節點篩選策略
| `-- priorities //節點打分策略
| `-- util
|-- algorithmprovider
| `-- defaults //定義預設的排程器 Scheduler建立和執行的過程, 對應的程式碼在
具體的排程過程,一般如下:
- 首先,客戶端通過API Server的REST API/kubectl/helm建立pod/service/deployment/job等,支援型別主要為JSON/YAML/helm tgz。
- 接下來,API Server收到使用者請求,儲存到相關資料到etcd。
- 排程器通過API Server檢視未排程(bind)的Pod列表,迴圈遍歷地為每個Pod分配節點,嘗試為Pod分配節點。排程過程分為2個階段:
- 第一階段:預選過程,過濾節點,排程器用一組規則過濾掉不符合要求的主機。比如Pod指定了所需要的資源量,那麼可用資源比Pod需要的資源量少的主機會被過濾掉。
- 第二階段:優選過程,節點優先順序打分,對第一步篩選出的符合要求的主機進行打分,在主機打分階段,排程器會考慮一些整體優化策略,比如把容一個Replication Controller的副本分佈到不同的主機上,使用最低負載的主機等。
- 選擇主機:選擇打分最高的節點,進行binding操作,結果儲存到etcd中。
- 所選節點對於的kubelet根據排程結果執行Pod建立操作。
預選過程: 原始碼位置kubernetes/pkg/scheduler/algorithm/predicates/predicates.go
predicatesOrdering = []string{CheckNodeConditionPred, CheckNodeUnschedulablePred,
GeneralPred, HostNamePred, PodFitsHostPortsPred,
MatchNodeSelectorPred, PodFitsResourcesPred, NoDiskConflictPred,
PodToleratesNodeTaintsPred, PodToleratesNodeNoExecuteTaintsPred, CheckNodeLabelPresencePred,
CheckServiceAffinityPred, MaxEBSVolumeCountPred, MaxGCEPDVolumeCountPred, MaxCSIVolumeCountPred,
MaxAzureDiskVolumeCountPred, CheckVolumeBindingPred, NoVolumeZoneConflictPred,
CheckNodeMemoryPressurePred, CheckNodePIDPressurePred, CheckNodeDiskPressurePred, MatchInterPodAffinityPred}主要包括主機的目錄,埠,cpu記憶體資源等條件進行物理主機的篩選,篩選出可以進行排程的物理機節點,然後進行優選環節,通過某種策略進行可用節點的評分,最終選出最優節點。
優選過程: 原始碼位置 kubernetes/pkg/scheduler/algorithm/priorities/
用一組優先順序函式處理每一個通過預選的節點,每一個優先順序函式會返回一個0-10的分數,分數越高表示節點越優, 同時每一個函式也會對應一個表示權重的值。最終主機的得分用以下公式計算得出:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + … + (weightn * priorityFuncn)
優先順序策略:
LeastRequestedPriority:節點的優先順序就由節點空閒資源與節點總容量的比值,即由(總容量-節點上Pod的容量總和-新Pod的容量)/總容量)來決定。CPU和記憶體具有相同權重,資源空閒比越高的節點得分越高。
cpu((capacity – sum(requested)) * 10 / capacity) + memory((capacity – sum(requested)) * 10 / capacity) / 2
BalancedResourceAllocation:CPU和記憶體使用率越接近的節點權重越高,該策略不能單獨使用,必須和LeastRequestedPriority組合使用,儘量選擇在部署Pod後各項資源更均衡的機器。如果請求的資源(CPU或者記憶體)大於節點的capacity,那麼該節點永遠不會被排程到。
InterPodAffinityPriority:通過迭代 weightedPodAffinityTerm 的元素計算和,並且如果對該節點滿足相應的PodAffinityTerm,則將 “weight” 加到和中,具有最高和的節點是最優選的。 `
SelectorSpreadPriority:為了更好的容災,對同屬於一個service、replication controller或者replica的多個Pod副本,儘量排程到多個不同的節點上。如果指定了區域,排程器則會盡量把Pod分散在不同區域的不同節點上。當一個Pod的被排程時,會先查詢Pod對於的service或者replication controller,然後查詢service或replication controller中已存在的Pod,執行Pod越少的節點的得分越高。
NodeAffinityPriority:親和性機制。Node Selectors(排程時將pod限定在指定節點上),支援多種操作符(In, NotIn, Exists, DoesNotExist, Gt, Lt),而不限於對節點labels的精確匹配。另外支援兩種型別的選擇器,一種是“hard(requiredDuringSchedulingIgnoredDuringExecution)”選擇器,它保證所選的主機必須滿足所有Pod對主機的規則要求。這種選擇器更像是之前的nodeselector,在nodeselector的基礎上增加了更合適的表現語法。另一種是“soft(preferresDuringSchedulingIgnoredDuringExecution)”選擇器,它作為對排程器的提示,排程器會盡量但不保證滿足NodeSelector的所有要求。
NodePreferAvoidPodsPriority(權重1W):如果 節點的 Anotation 沒有設定 key-value:scheduler. alpha.kubernetes.io/ preferAvoidPods = "...",則節點對該 policy 的得分就是10分,加上權重10000,那麼該node對該policy的得分至少10W分。如果Node的Anotation設定了,scheduler.alpha.kubernetes.io/preferAvoidPods = "..." ,如果該 pod 對應的 Controller 是 ReplicationController 或 ReplicaSet,則該 node 對該 policy 的得分就是0分。
TaintTolerationPriority : 使用 Pod 中 tolerationList 與 節點 Taint 進行匹配,配對成功的項越多,則得分越低。
ImageLocalityPriority:根據Node上是否存在一個pod的容器執行所需映象大小對優先順序打分,分值為0-10。遍歷全部Node,如果某個Node上pod容器所需的映象一個都不存在,分值為0;如果Node上存在Pod容器部分所需映象,則根據這些映象的大小來決定分值,映象越大,分值就越高;如果Node上存在pod所需全部映象,分值為10。
EqualPriority : EqualPriority 是一個優先順序函式,它給予所有節點相等權重。
MostRequestedPriority : 在 ClusterAutoscalerProvider 中,替換 LeastRequestedPriority,給使用多資源的節點,更高的優先順序。計算公式為:(cpu(10 sum(requested) / capacity) + memory(10 sum(requested) / capacity)) / 2
自定義排程:
kubernetes/pkg/scheduler/algorithmprovider/defaults/defaults.go
自定義預選以及優選策略,scheduler在啟動的時候可以通過 --policy-config-file引數可以指定排程策略檔案。
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 1},
{"name" : "EqualPriority", "weight" : 1}
],
"hardPodAffinitySymmetricWeight" : 10 自定義Priority和Predicate
自定義Priority的實現過程
1.介面位置:kubernetes/pkg/scheduler/algorithm/types.go
// PriorityFunction is a function that computes scores for all nodes.
// DEPRECATED
// Use Map-Reduce pattern for priority functions.
type PriorityFunction func(pod *v1.Pod, nodeNameToInfo map[string]*schedulercache.NodeInfo, nodes []*v1.Node) (schedulerapi.HostPriorityList, error)2.在kubernetes/pkg/scheduler/algorithm/predicates/predicates.go檔案中編寫物件是實現上述介面

3.註冊自定義過濾函式 kubernetes/pkg/scheduler/algorithmprovider/defaults/defaults.go

4.--policy-config-file將自定義Priority載入進來即可
自定義排程器:
利用Pod的spec.schedulername欄位來指定排程器,預設為default
#!/bin/bash
SERVER='localhost:8001'
while true;
do
for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"')
;
do
NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
NUMNODES=${#NODES[@]}
CHOSEN=${NODES[$[ $RANDOM % $NUMNODES ]]}
curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding", "metadata": {"name": "'$PODNAME'"}, "target": {"apiVersion": "v1", "kind"
: "Node", "name": "'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
echo "Assigned $PODNAME to $CHOSEN"
done
sleep 1
done Pod優先順序(Priority)和搶佔(Preemption)
pod priority指的是Pod的優先順序,高優先順序的Pod會優先被排程,或者在資源不足低情況犧牲低優先順序的Pod,以便於重要的Pod能夠得到資源部署.
定義PriorityClass物件:
apiVersion: scheduling.k8s.io/v1alpha1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."在Pod的spec. priorityClassName中指定已定義的PriorityClass名稱
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority當節點沒有足夠的資源供排程器排程Pod、導致Pod處於pending時,搶佔(preemption)邏輯會被觸發。Preemption會嘗試從一個節點刪除低優先順序的Pod,從而釋放資源使高優先順序的Pod得到節點資源進行部署。
參考地址:
http://dockone.io/article/2885
https://github.com/kubernetes/kubernetes/blob/master