
【NLP】【五】gensim之Word2Vec
阿新 • • 發佈:2018-11-25
【一】整體流程綜述
gensim底層封裝了Google的Word2Vec的c介面,藉此實現了word2vec。使用gensim介面非常方便,整體流程如下:
1. 資料預處理(分詞後的資料)
2. 資料讀取
3.模型定義與訓練
4.模型儲存與載入
5.模型使用(相似度計算,詞向量獲取)
【二】gensim提供的word2vec主要功能
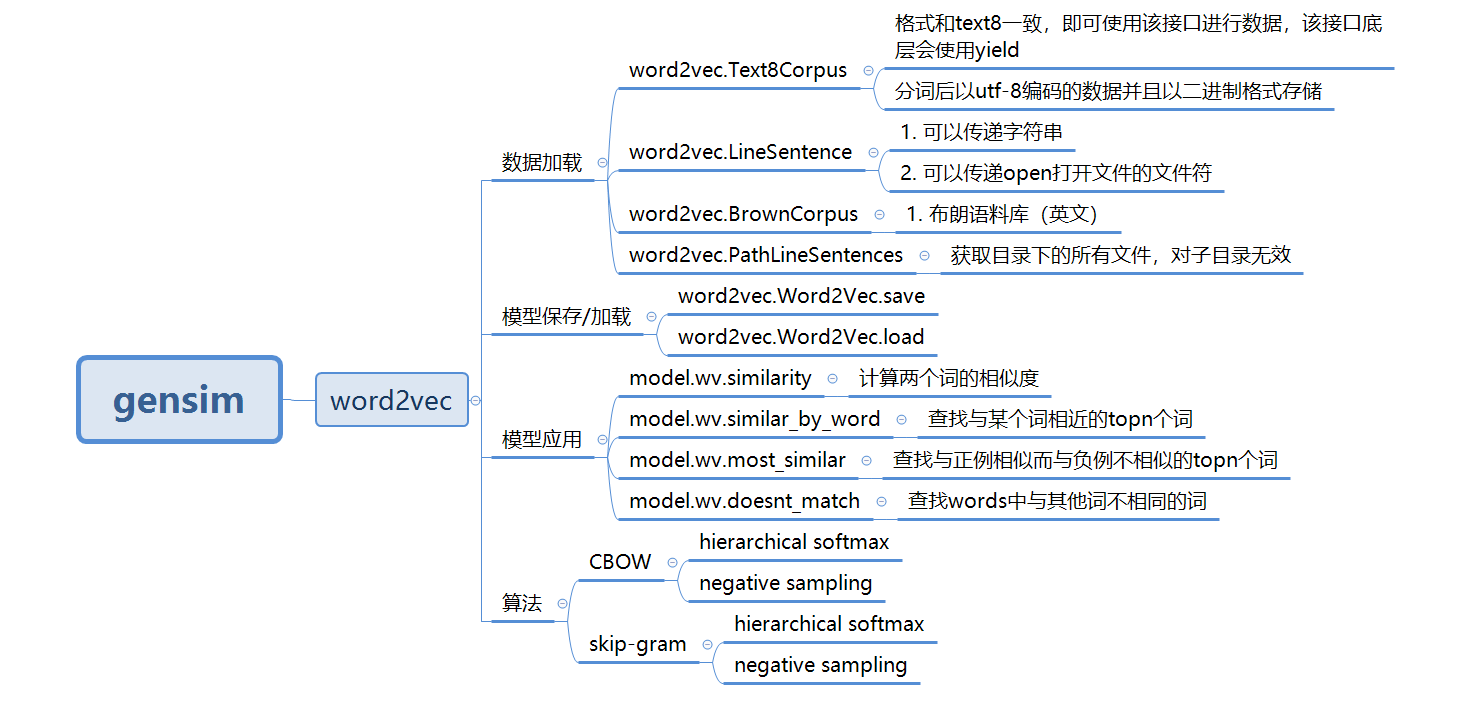
【三】gensim介面使用示例
1. 使用jieba進行分詞。
文字資料:《人民的名義》的小說原文作為語料
百度雲盤:https://pan.baidu.com/s/1ggA4QwN
# -*- coding:utf-8 -*- import jieba def preprocess_in_the_name_of_people(): with open("in_the_name_of_people.txt",mode='rb') as f: doc = f.read() doc_cut = jieba.cut(doc) result = ' '.join(doc_cut) result = result.encode('utf-8') with open("in_the_name_of_people_cut.txt",mode='wb') as f2: f2.write(result)
2. 使用原始text8.zip進行詞向量訓練
from gensim.models import word2vec # 引入日誌配置 import logging logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO) def train_text8(): sent = word2vec.Text8Corpus(fname="text8") model = word2vec.Word2Vec(sentences=sent) model.save("text8.model")
注意。這裡是解壓後的檔案,不是zip包
3. 使用Text8Corpus 介面載入資料
def train_in_the_name_of_people():
sent = word2vec.Text8Corpus(fname="in_the_name_of_people_cut.txt")
model = word2vec.Word2Vec(sentences=sent)
model.save("in_the_name_of_people.model")4. 使用 LineSentence 介面載入資料
def train_line_sentence(): with open("in_the_name_of_people_cut.txt", mode='rb') as f: # 傳遞open的fd sent = word2vec.LineSentence(f) model = word2vec.Word2Vec(sentences=sent) model.save("line_sentnce.model")
5. 使用 PathLineSentences 介面載入資料
def train_PathLineSentences():
# 傳遞目錄,遍歷目錄下的所有檔案
sent = word2vec.PathLineSentences("in_the_name_of_people")
model = word2vec.Word2Vec(sentences=sent)
model.save("PathLineSentences.model")6. 資料載入與訓練分開
def train_left():
sent = word2vec.Text8Corpus(fname="in_the_name_of_people_cut.txt")
# 定義模型
model = word2vec.Word2Vec()
# 構造詞典
model.build_vocab(sentences=sent)
# 模型訓練
model.train(sentences=sent,total_examples = model.corpus_count,epochs = model.iter)
model.save("left.model")7. 模型載入與使用
model = word2vec.Word2Vec.load("text8.model")
print(model.similarity("eat","food"))
print(model.similarity("cat","dog"))
print(model.similarity("man","woman"))
print(model.most_similar("man"))
print(model.wv.most_similar(positive=['woman', 'king'], negative=['man'],topn=1))
model2 = word2vec.Word2Vec.load("in_the_name_of_people.model")
print(model2.most_similar("吃飯"))
print(model2.similarity("省長","省委書記"))
model2 = word2vec.Word2Vec.load("line_sentnce.model")
print(model2.similarity("李達康","市委書記"))
top3 = model2.wv.similar_by_word(word="李達康",topn=3)
print(top3)
model2 = word2vec.Word2Vec.load("PathLineSentences.model")
print(model2.similarity("李達康","書記"))
print(model2.wv.similarity("李達康","書記"))
print(model2.wv.doesnt_match(words=["李達康","高育良","趙立春"]))
model = word2vec.Word2Vec.load("left.model")
print(model.similarity("李達康","書記"))結果如下:
0.5434648
0.8383337
0.7435267
[('woman', 0.7435266971588135), ('girl', 0.6460582613945007), ('creature', 0.589219868183136), ('person', 0.570125937461853), ('evil', 0.5688984990119934), ('god', 0.5465947389602661), ('boy', 0.544859766960144), ('bride', 0.5401148796081543), ('soul', 0.5365912914276123), ('stranger', 0.531282901763916)]
[('queen', 0.7230167388916016)]
[('只能', 0.9983761310577393), ('招待所', 0.9983713626861572), ('深深', 0.9983667135238647), ('幹警', 0.9983251094818115), ('警察', 0.9983127117156982), ('公安', 0.9983105659484863), ('趙德漢', 0.9982908964157104), ('似乎', 0.9982795715332031), ('一場', 0.9982751607894897), ('才能', 0.9982657432556152)]
0.97394305
0.99191403
[('新', 0.9974302053451538), ('趙立春', 0.9974139928817749), ('談一談', 0.9971731901168823)]
0.91472965
0.91472965
高育良
0.885189958. 參考連結
https://github.com/RaRe-Technologies/gensim
https://github.com/RaRe-Technologies/gensim/blob/develop/docs/notebooks/word2vec.ipynb