
【AI實戰】動手實現人臉識別程式

人臉識別在現實生活中有非常廣泛的應用,例如iPhone X的識別人臉解鎖螢幕、人臉識別考勤機、人臉識別開門禁、刷臉坐高鐵,還有識別人臉虛擬化妝、美顏,甚至支付寶還推出了刷臉支付、建設銀行還實現了刷臉取錢……,可見人臉識別的用處非常廣。
既然人臉識別這麼有用,那我們能否自己來實現一個人臉識別模型呢?
答案是肯定的。
接下來將在之前我們搭建好的AI基礎環境上(見文章:搭建AI基礎環境),實現人臉識別模型。
0、人臉識別主要流程
要識別一張人臉,一般需要經過以下步驟:(1)通過攝像頭或上傳圖片等方式採集影象;(2)檢測影象裡面有沒有人臉,如果有就把人臉所在的區域圈出來;(3)對人臉影象進行灰度處理、噪聲過濾等預處理;(4)提取人臉的特徵資料出來;(5)將提取的人臉特徵資料與人臉庫進行匹配,輸出識別結果。主要流程如下圖所示:

下面將按步驟逐個介紹實現方式。
1、影象採集
本文采用OpenCV採集影象。

OpenCV是處理影象的流行工具,具備多種影象處理的能力,可跨平臺執行在Linux、Windows、Mac OS等多個平臺,使用C++編寫,提供Python、C++、Ruby等語言的介面。在Python環境中,OpenCV和Tensorflow能很好地相互配合,利用OpenCV可方便快速地採集、處理影象,配合Tensorflow能很好地實現影象的建模工作。
(1)安裝OpenCV
在conda虛擬環境中,OpenCV的安裝方式如下:
conda install --channel https://conda.anaconda.org/menpo opencv3
(2)採集影象
在OpenCV中呼叫攝像頭採集影象的方式如下:
# 1、呼叫攝像頭進行拍照
cap = cv2.VideoCapture(0)
ret, img = cap.read()
cap.release()
如果已經是有現成的圖片,則在OpenCV中直接讀取就可以:
# 2、根據提供的路徑讀取影象
img=cv2.imread(img_path)
2、人臉檢測
人臉檢測的主要目的是檢測採集的影象中有沒有人臉,並確定出人臉所在的位置和大小。檢測人臉有很多種方式,下面介紹幾種常用的方法:
(1)使用OpenCV檢測人臉
OpenCV中自帶了人臉檢測器,基於Haar演算法進行人臉檢測。Haar演算法的基本思路是這樣的,通過使用一些矩形模板對影象進行掃描,例如下圖中的兩個矩形模板,中間一幅在掃描到眼睛時發現眼睛區域的顏色比周邊臉頰區域的顏色深,表示符合眼睛的特徵;右邊一幅在掃描到鼻樑時發現鼻樑兩側比鼻樑的顏色要深,符合鼻樑的特徵。同樣地,再通過其它的矩形模板進行掃描,當發現具備眼睛、鼻樑、嘴巴等特徵且超過一定的閾值時,則判定為是一張人臉。

使用OpenCV檢測人臉,要先載入人臉分類器
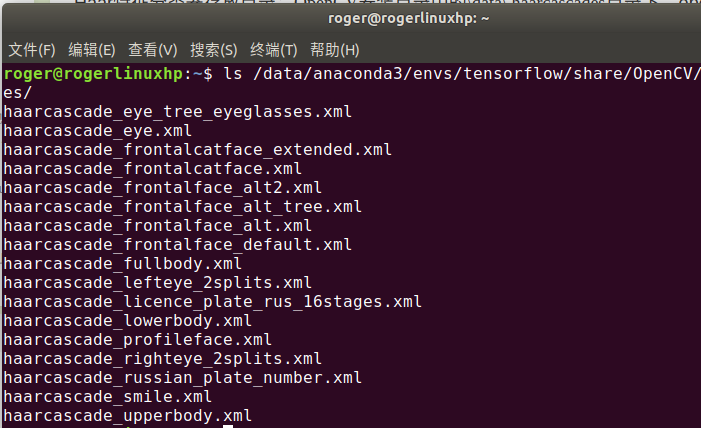
程式碼如下:
# 1、使用 opencv 檢測人臉
# 載入人臉檢測分類器(正面人臉),位於OpenCV的安裝目錄下
face_cascade=cv2.CascadeClassifier('/data/anaconda3/envs/tensorflow/share/OpenCV/haarcascades/haarcascade_frontalface_default.xml')
# 轉灰度圖
img_gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 檢測人臉(可能有多張),返回人臉位置資訊(x,y,w,h)
img_faces=face_cascade.detectMultiScale(img_gray)
(2)使用Dlib檢測人臉
Dlib是一個包含機器學習演算法開源工具包,基於C++編寫,同樣也提供了Python語言介面。使用Dlib也能很方便地檢測出人臉,檢測的效果要比OpenCV好,安裝方式如下:
# 安裝 Dlib
# 啟用 conda 虛擬環境
conda activate tensorflow
# 安裝 Dlib
conda install -c menpo dlib程式碼如下:
# Dlib 人臉檢測
detector = dlib.get_frontal_face_detector()
dets = detector(img, 1)
# 獲取人臉所在的位置
img_faces=[]
for i in range(len(dets)):
x = dlib.rectangle.left(dets[i])
y = dlib.rectangle.top(dets[i])
h = dlib.rectangle.height(dets[i])
w = dlib.rectangle.width(dets[i])
img_faces.append([x,y,w,h])
(3)使用face_recognition檢測人臉

face_recognition是基於dlib的深度學習人臉識別庫,在戶外臉部檢測資料庫基準(Labeled Faces in the Wild benchmark,簡稱LFW)上的準確率達到了99.38%。
使用face_recognition檢測人臉,安裝方式如下:
# 安裝 face_recognition
# 需要先安裝dlib , 還有 CMake ( sudo apt-get install cmake )
# 啟用 conda 虛擬環境
conda activate tensorflow
# 由於 face_recognition 在 conda 中沒有相應的軟體包,因此通過 pip 安裝
pip install face_recognition程式碼如下:
# 檢測人臉
face_locations = face_recognition.face_locations(img)
# 獲取人臉的位置資訊
img_faces = []
for i in range(len(face_locations)):
x = face_locations[i][3]
y = face_locations[i][0]
h = face_locations[i][2] - face_locations[i][0]
w = face_locations[i][1] - face_locations[i][3]
img_faces.append([x, y, w, h])
(4)使用FaceNet檢測人臉

FaceNet是谷歌釋出的人臉檢測演算法,發表於CVPR 2015,這是基於深度學習的人臉檢測演算法,利用相同人臉在不同角度、姿態的高內聚性,不同人臉的低耦合性,使用卷積神經網路所訓練出來的人臉檢測模型,在LFW人臉影象資料集上準確度達到99.63%,比傳統方法的準確度提升了將近30%,效果非常好。
使用FaceNet檢測人臉,安裝方式如下:
a. 到FaceNet的github上將原始碼和相應的模型下載下來(https://github.com/davidsandberg/facenet)
b. 將要用到的python檔案匯入到本地的 facenet 庫中,如下圖所示:
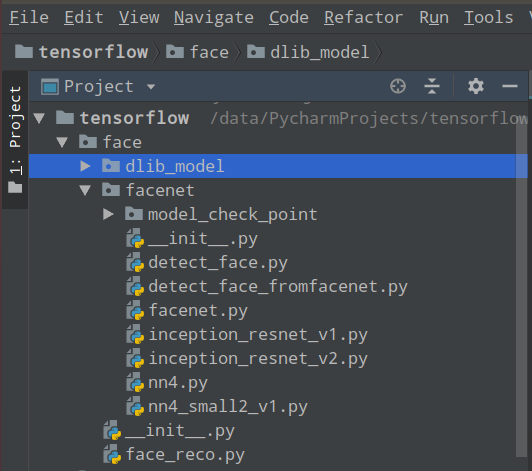
程式碼如下:
with tf.Graph().as_default():
sess = tf.Session()
with sess.as_default():
pnet, rnet, onet = facenet.detect_face_fromfacenet.create_mtcnn(sess, './facenet/model_check_point/')
minsize = 20
threshold = [0.6, 0.7, 0.7]
factor = 0.709
bounding_boxes, _ = facenet.detect_face_fromfacenet.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
img_faces = []
for face_position in bounding_boxes:
face_position = face_position.astype(int)
x = face_position[0]
y = face_position[1]
h = face_position[3] - face_position[1]
w = face_position[2] - face_position[0]
img_faces.append([x, y, w, h])
3、預處理
在做完影象的人臉檢測後,得到了人臉所在的位置和大小,但由於受到各種條件的限制和隨機干擾,需要根據實際採集的影象質量情況進行預處理,以提升影象的質量。主要的預處理有:
(1)調整尺寸:根據網路傳輸頻寬、電腦處理效能等相關的要求,對檢測的人臉影象進行尺寸調整;
(2)直方圖均衡化:根據實際情況,對影象作直方圖均衡,避免因光線問題,導致人臉上出現明顯陰影的情況,從而影響了識別的準確率;
(3)噪聲過濾:通過使用中值濾波器、高斯濾波器等對影象進行噪聲過濾,以提升影象質量;
(4)銳化:由於攝像頭對焦的問題,導致某些採集的照片出現模糊,通過銳化操作,提升影象的清晰度;
(5)光線補償:對於一些光線不足的影象進行光線補償,提升照片的亮度,便於後續更加準確地提取特徵。
4、特徵提取
人臉是由眼睛、鼻子、嘴、下巴等區域性構成,這些區域性之間的結構關係,便是作為人臉的重要特徵。人臉特徵的提取,是對人臉進行特徵建模的過程。
下面介紹提取人臉特徵的幾種方法:
(1)使用Dlib提取人臉特徵(68維)
使用Dlib可提取人臉的68個特徵點,這些特徵點描述了眉毛、眼睛、鼻子、嘴巴,以及整個臉部的輪廓,如下圖所示:

使用Dlib提取人臉特徵的程式碼如下:
# 1、dlib 提取人臉特徵
# opencv 無法直接提取人臉特徵,在這裡設定 opencv 也採用 dlib 的特徵提取方式
# 下載模型:http://dlib.net/files/
# 下載檔案:shape_predictor_68_face_landmarks.dat.bz2
# 解壓檔案,得到 shape_predictor_68_face_landmarks.dat 檔案
# 獲取人臉檢測器
predictor = dlib.shape_predictor('./dlib_model/shape_predictor_68_face_landmarks.dat')
for index,face in enumerate(dets):
face_feature = predictor(face_img,face)(2)使用face_recognition提取人臉特徵(128維)
face_recognition提取的人臉特徵比Dlib更加細緻,達到128個點,同樣也是描述了眉毛、眼睛、鼻子、嘴巴等區域性的關係。
使用face_recognition提取人臉特徵的程式碼如下:
# 2、face_recognition 提取人臉特徵
face_feature = face_recognition.face_encodings(face_img)(3)使用FaceNet提取人臉特徵(128維)
使用FaceNet提取的人臉特徵同樣也有128維,程式碼如下:
with tf.Graph().as_default():
sess = tf.Session()
with sess.as_default():
batch_size=None
image_size=160
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,image_size,image_size, 3), name='input')
phase_train_placeholder = tf.placeholder(tf.bool, name='phase_train')
model_checkpoint_path = './facenet/model_check_point/'
input_map = {'input': images_placeholder, 'phase_train': phase_train_placeholder}
model_exp = os.path.expanduser(model_checkpoint_path)
meta_file, ckpt_file = get_model_filenames(model_exp)
saver = tf.train.import_meta_graph(os.path.join(model_exp, meta_file), input_map=input_map)
saver.restore(sess, os.path.join(model_exp, ckpt_file))
face_img = cv2.resize(face_img, (image_size, image_size), interpolation=cv2.INTER_CUBIC)
data = np.stack([face_img])
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
feed_dict = {images_placeholder: data, phase_train_placeholder: False}
face_feature = sess.run(embeddings, feed_dict=feed_dict)
5、匹配識別
在提取好人臉特徵後,便是要用於識別這個人是誰。
將提取的人臉特徵與資料庫中儲存的人臉特徵資料進行檢索匹配,當匹配的相似度超過一定的閾值後,便將匹配結果輸出。
一般常用以下方式進行匹配:
(1)基於距離判斷(歐氏距離)
將提取出來的人臉特徵(68維或128維),逐個與資料庫中的人臉特徵計算距離,一般使用歐氏距離,然後取最小的距離,當超過閾值時便輸出識別結果。
這種方式簡單易用,但卻經常會誤判,這是由於人的表情很豐富,資料庫中並不一定會把所有表情都儲存起來。
基於歐氏距離的人臉識別程式碼如下:
# 1、歐氏距離
min_dis=99999
min_idx=-1
for i in range(len(features)):
dis=np.sqrt(np.sum(np.square(face_feature-features[i])))
if dis<min_dis:
min_dis=dis
min_idx=i
name=labels[min_idx]
(2)基於分類演算法(KNN)
人臉特徵的匹配本質上也是一個分類過程,即將屬於同一個人的分類出來。採用K近鄰(KNN)演算法進行分類,這是資料探勘中最簡單的方法之一。所謂K近鄰,就是K個最近鄰居,就是說每個樣本都可以用它最接近的K個鄰居來代表。因此,KNN演算法的核心思想是如果一個樣本的K個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別。
基於KNN的人臉識別程式碼如下:
# 2、KNN
knn = neighbors.KNeighborsClassifier(n_neighbors=2)
knn.fit(features, labels)
name = knn.predict([face_feature])
name = name[0]
通過以上步驟,我們瞭解了幾種常見的人臉檢測、識別演算法,並掌握了一個完整的人臉識別程式的編寫過程。
後面將陸續推出更多AI實戰內容,敬請留意。
推薦相關閱讀
- 【AI實戰】快速掌握TensorFlow(一):基本操作
- 【AI實戰】快速掌握TensorFlow(二):計算圖、會話
- 【AI實戰】快速掌握TensorFlow(三):激勵函式
- 【AI實戰】快速掌握TensorFlow(四):損失函式
- 【AI實戰】搭建基礎環境
- 【AI實戰】訓練第一個模型
- 【AI實戰】編寫人臉識別程式
- 【AI實戰】動手訓練目標檢測模型(SSD篇)
- 【AI實戰】動手訓練目標檢測模型(YOLO篇)
- 【精華整理】CNN進化史
- 大話卷積神經網路(CNN)
- 大話迴圈神經網路(RNN)
- 大話深度殘差網路(DRN)
- 大話深度信念網路(DBN)
- 大話CNN經典模型:LeNet
- 大話CNN經典模型:AlexNet
- 大話CNN經典模型:VGGNet
- 大話CNN經典模型:GoogLeNet
- 大話目標檢測經典模型:RCNN、Fast RCNN、Faster RCNN
- 大話目標檢測經典模型:Mask R-CNN
- 27種深度學習經典模型
- 淺說“遷移學習”
- 什麼是“強化學習”
- AlphaGo演算法原理淺析
- 大資料究竟有多少個V
- Apache Hadoop 2.8 完全分散式叢集搭建超詳細教程
- Apache Hive 2.1.1 安裝配置超詳細教程
- Apache HBase 1.2.6 完全分散式叢集搭建超詳細教程
- 離線安裝Cloudera Manager 5和CDH5(最新版5.13.0)超詳細教程