【AI實戰】快速掌握TensorFlow(四):損失函式

在前面的文章中,我們已經學習了TensorFlow激勵函式的操作使用方法(見文章:快速掌握TensorFlow(三)),今天我們將繼續學習TensorFlow。
本文主要是學習掌握TensorFlow的損失函式。
一、什麼是損失函式
損失函式(loss function)是機器學習中非常重要的內容,它是度量模型輸出值與目標值的差異,也就是作為評估模型效果的一種重要指標,損失函式越小,表明模型的魯棒性就越好。
二、怎樣使用損失函式
在TensorFlow中訓練模型時,通過損失函式告訴TensorFlow預測結果相比目標結果是好還是壞。在多種情況下,我們會給出模型訓練的樣本資料和目標資料,損失函式即是比較預測值與給定的目標值之間的差異。
下面將介紹在TensorFlow中常用的損失函式。
1、迴歸模型的損失函式
首先講解迴歸模型的損失函式,迴歸模型是預測連續因變數的。為方便介紹,先定義預測結果(-1至1的等差序列)、目標結果(目標值為0),程式碼如下:
import tensorflow as tf
sess=tf.Session()
y_pred=tf.linspace(-1., 1., 100)
y_target=tf.constant(0.)注意,在實際訓練模型時,預測結果是模型輸出的結果值,目標結果是樣本提供的。
(1)L1正則損失函式(即絕對值損失函式)
L1正則損失函式是對預測值與目標值的差值求絕對值,公式如下:
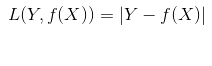
在TensorFlow中呼叫方式如下:
loss_l1_vals=tf.abs(y_pred-y_target)
loss_l1_out=sess.run(loss_l1_vals)L1正則損失函式在目標值附近不平滑,會導致模型不能很好地收斂。
(2)L2正則損失函式(即尤拉損失函式)
L2正則損失函式是預測值與目標值差值的平方和,公式如下:
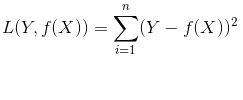
當對L2取平均值,就變成均方誤差(MSE, mean squared error),公式如下:
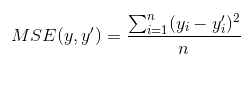
在TensorFlow中呼叫方式如下:
# L2損失
loss_l2_vals=tf.square(y_pred - y_target)
loss_l2_out=sess.run(loss_l2_vals)
# 均方誤差
loss_mse_vals= tf.reduce.mean(tf.square(y_pred - y_target))
loss_mse_out = sess.run(loss_mse_vals)L2正則損失函式在目標值附近有很好的曲度,離目標越近收斂越慢,是非常有用的損失函式。
L1、L2正則損失函式如下圖所示:
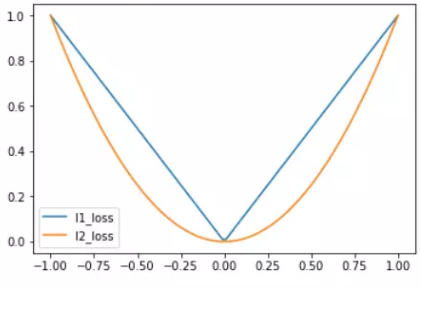
(3)Pseudo-Huber 損失函式
Huber損失函式經常用於迴歸問題,它是分段函式,公式如下:
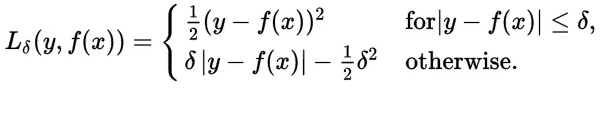
從這個公式可以看出當殘差(預測值與目標值的差值,即y-f(x) )很小的時候,損失函式為L2範數,殘差大的時候,為L1範數的線性函式。
Peseudo-Huber損失函式是Huber損失函式的連續、平滑估計,在目標附近連續,公式如下:
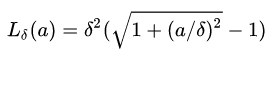
該公式依賴於引數delta,delta越大,則兩邊的線性部分越陡峭。
在TensorFlow中的呼叫方式如下:
delta=tf.constant(0.25)
loss_huber_vals = tf.mul(tf.square(delta), tf.sqrt(1. + tf.square(y_target – y_pred)/delta)) – 1.)
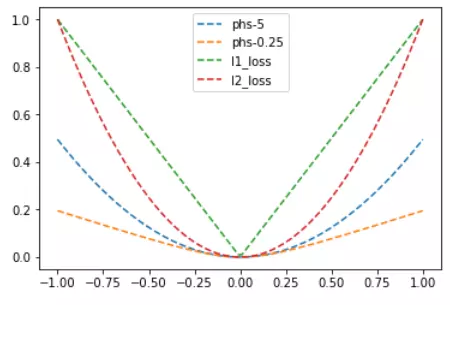
loss_huber_out = sess.run(loss_huber_vals)L1、L2、Huber損失函式的對比圖如下,其中Huber的delta取0.25、5兩個值:
2、分類模型的損失函式
分類損失函式主要用於評估預測分類結果,重新定義預測值(-3至5的等差序列)和目標值(目標值為1),如下:
y_pred=tf.linspace(-3., 5., 100)
y_target=tf.constant(1.)
y_targets=tf.fill([100, ], 1.)(1)Hinge損失函式
Hinge損失常用於二分類問題,主要用來評估向量機演算法,但有時也用來評估神經網路演算法,公式如下:
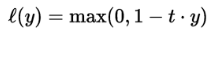
在TensorFlow中的呼叫方式如下:
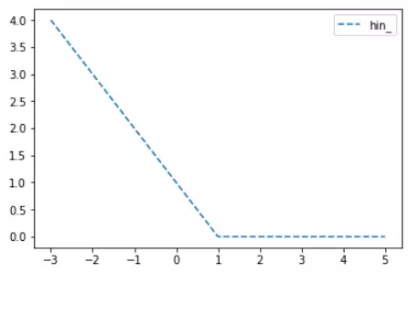
loss_hinge_vals = tf.maximum(0., 1. – tf.mul(y_target, y_pred))
loss_hinge_out = sess.run(loss_hinge_vals)上面的程式碼中,目標值為1,當預測值離1越近,則損失函式越小,如下圖:
(2)兩類交叉熵(Cross-entropy)損失函式
交叉熵來自於資訊理論,是分類問題中使用廣泛的損失函式。交叉熵刻畫了兩個概率分佈之間的距離,當兩個概率分佈越接近時,它們的交叉熵也就越小,給定兩個概率分佈p和q,則距離如下:
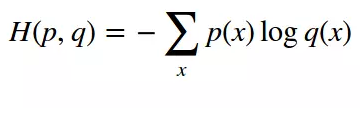
對於兩類問題,當一個概率p=y,則另一個概率q=1-y,因此代入化簡後的公式如下:
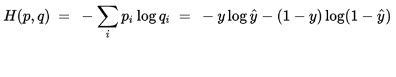
在TensorFlow中的呼叫方式如下:
loss_ce_vals = tf.mul(y_target, tf.log(y_pred)) – tf.mul((1. – y_target), tf.log(1. – y_pred))
loss_ce_out = sess.run(loss_ce_vals)Cross-entropy損失函式主要應用在二分類問題上,預測值為概率值,取值範圍為[0,1],損失函式圖如下:
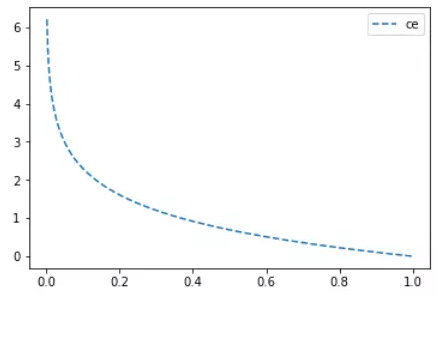
(3)Sigmoid交叉熵損失函式
與上面的兩類交叉熵類似,只是將預測值y_pred值通過sigmoid函式進行轉換,再計算交叉熵損失。在TensorFlow中有內建了該函式,呼叫方式如下:
loss_sce_vals=tf.nn.sigmoid_cross_entropy_with_logits(y_pred, y_targets)
loss_sce_out=sess.run(loss_sce_vals)由於sigmoid函式會將輸入值變小很多,從而平滑了預測值,使得sigmoid交叉熵在預測值離目標值比較遠時,其損失的增長沒有那麼的陡峭。與兩類交叉熵的比較圖如下:
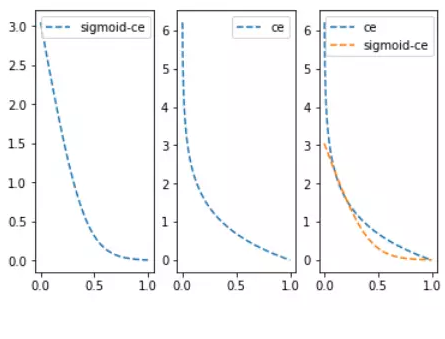
(4)加權交叉熵損失函式
加權交叉熵損失函式是Sigmoid交叉熵損失函式的加權,是對正目標的加權。假定權重為0.5,在TensorFlow中的呼叫方式如下:
weight = tf.constant(0.5)
loss_wce_vals = tf.nn.weighted_cross_entropy_with_logits(y)vals, y_targets, weight)
loss_wce_out = sess.run(loss_wce_vals)(5)Softmax交叉熵損失函式
Softmax交叉熵損失函式是作用於非歸一化的輸出結果,只針對單個目標分類計算損失。
通過softmax函式將輸出結果轉化成概率分佈,從而便於輸入到交叉熵裡面進行計算(交叉熵要求輸入為概率),softmax定義如下:
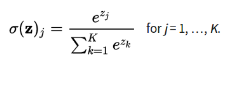
結合前面的交叉熵定義公式,則Softmax交叉熵損失函式公式如下:
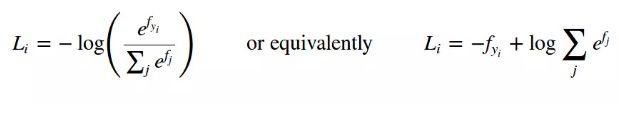
在TensorFlow中呼叫方式如下:
y_pred=tf.constant([[1., -3., 10.]]
y_target=tf.constant([[0.1, 0.02, 0.88]])
loss_sce_vals=tf.nn.softmax_cross_entropy_with_logits(y_pred, y_target)
loss_sce_out=sess.run(loss_sce_vals)用於迴歸相關的損失函式,對比圖如下:
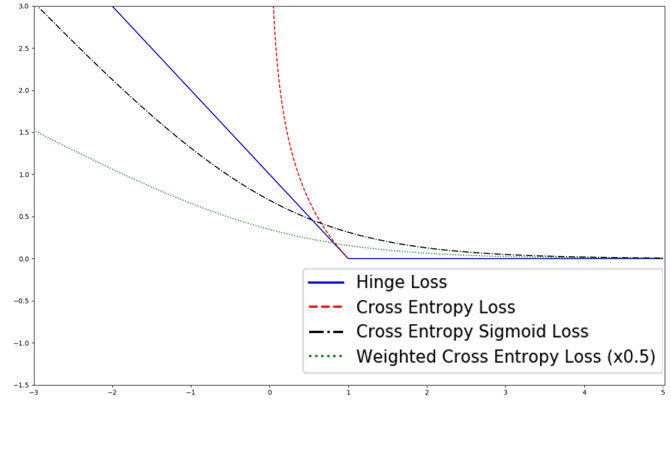
3、總結
下面對各種損失函式進行一個總結,如下表所示:

在實際使用中,對於迴歸問題經常會使用MSE均方誤差(L2取平均)計算損失,對於分類問題經常會使用Sigmoid交叉熵損失函式。
大家在使用時,還要根據實際的場景、具體的模型,選擇使用的損失函式,希望本文對你有幫助。
接下來的“快速掌握TensorFlow”系列文章,還會有更多講解TensorFlow的精彩內容,敬請期待。
推薦相關閱讀
- 【AI實戰】快速掌握TensorFlow(一):基本操作
- 【AI實戰】快速掌握TensorFlow(二):計算圖、會話
- 【AI實戰】快速掌握TensorFlow(三):激勵函式
- 【AI實戰】快速掌握TensorFlow(四):損失函式
- 【AI實戰】搭建基礎環境
- 【AI實戰】訓練第一個模型
- 【AI實戰】編寫人臉識別程式
- 【AI實戰】動手訓練目標檢測模型(SSD篇)
- 【AI實戰】動手訓練目標檢測模型(YOLO篇)
- 【精華整理】CNN進化史
- 大話卷積神經網路(CNN)
- 大話迴圈神經網路(RNN)
- 大話深度殘差網路(DRN)
- 大話深度信念網路(DBN)
- 大話CNN經典模型:LeNet
- 大話CNN經典模型:AlexNet
- 大話CNN經典模型:VGGNet
- 大話CNN經典模型:GoogLeNet
- 大話目標檢測經典模型:RCNN、Fast RCNN、Faster RCNN
- 大話目標檢測經典模型:Mask R-CNN
- 27種深度學習經典模型
- 淺說“遷移學習”
- 什麼是“強化學習”
- AlphaGo演算法原理淺析
- 大資料究竟有多少個V
- Apache Hadoop 2.8 完全分散式叢集搭建超詳細教程
- Apache Hive 2.1.1 安裝配置超詳細教程
- Apache HBase 1.2.6 完全分散式叢集搭建超詳細教程
- 離線安裝Cloudera Manager 5和CDH5(最新版5.13.0)超詳細教程
關注本人公眾號“大資料與人工智慧Lab”(BigdataAILab),獲取更多資訊。